Data Integration
Data integration provides ETL (Extract-Transform-Load) functionality, which extracts, filters, transforms formats, adds calculated columns, associates, merges, aggregates, and other processing on data from different sources, and then outputs it to the data source specified by the user for subsequent exploration and analysis.
Data Processing Workflow
The data processing workflow for data integration projects is roughly divided into three parts: connecting data, cleaning and transforming data, and outputting data.
The data integration page is shown as follows. The red box area on the left is the node area, where all nodes are dragged into the blue box canvas area in the middle. Nodes are connected within the canvas area to complete the data flow transmission between nodes, eventually flowing to the output node. Clicking on a node in the canvas allows you to set up the node. The top right of the canvas is the Project Execution button. 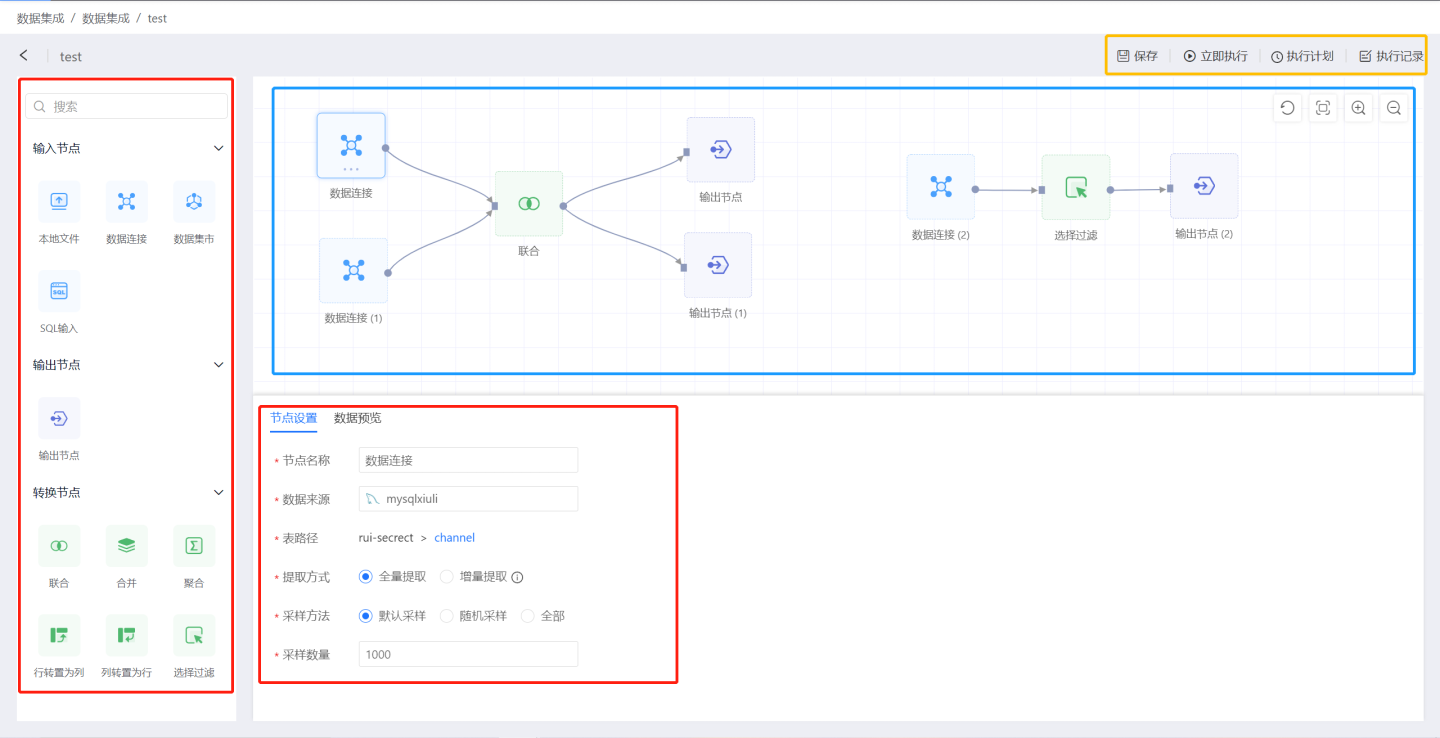
Data Integration Project Creation Process
Below describes the process of creating a data integration project, you can follow the instructions below to create a project.
Create a project. Click
New Projectin the upper right corner of the data integration page, and a pop-up window for creating a new project will appear. Enter the project name in the pop-up window and select a data connection as the default output path for the output node inDefault Output Path.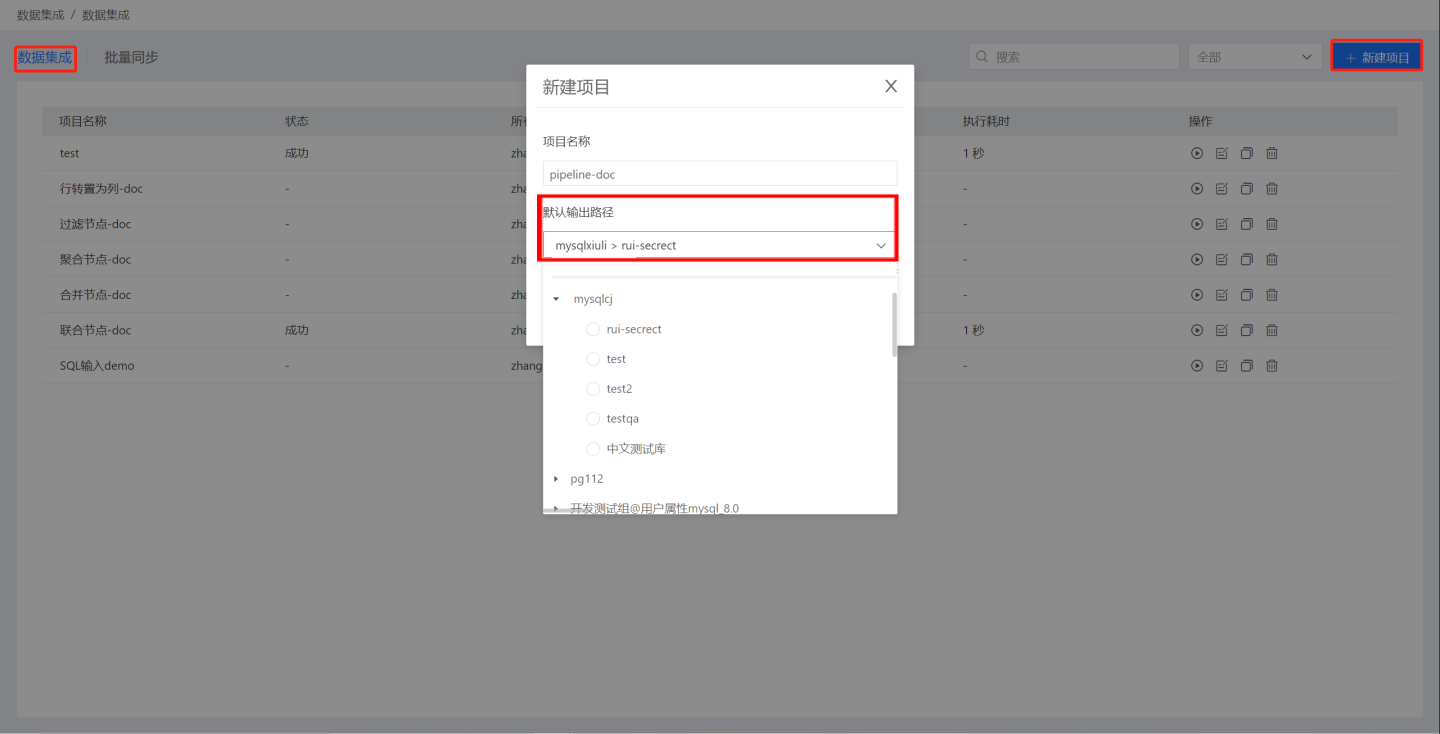
Create an input node. Select the type of input node, drag it into the canvas, and choose the data source. Supports four types of input nodes: Local File, Data Connection, Data Mart, and SQL Input.
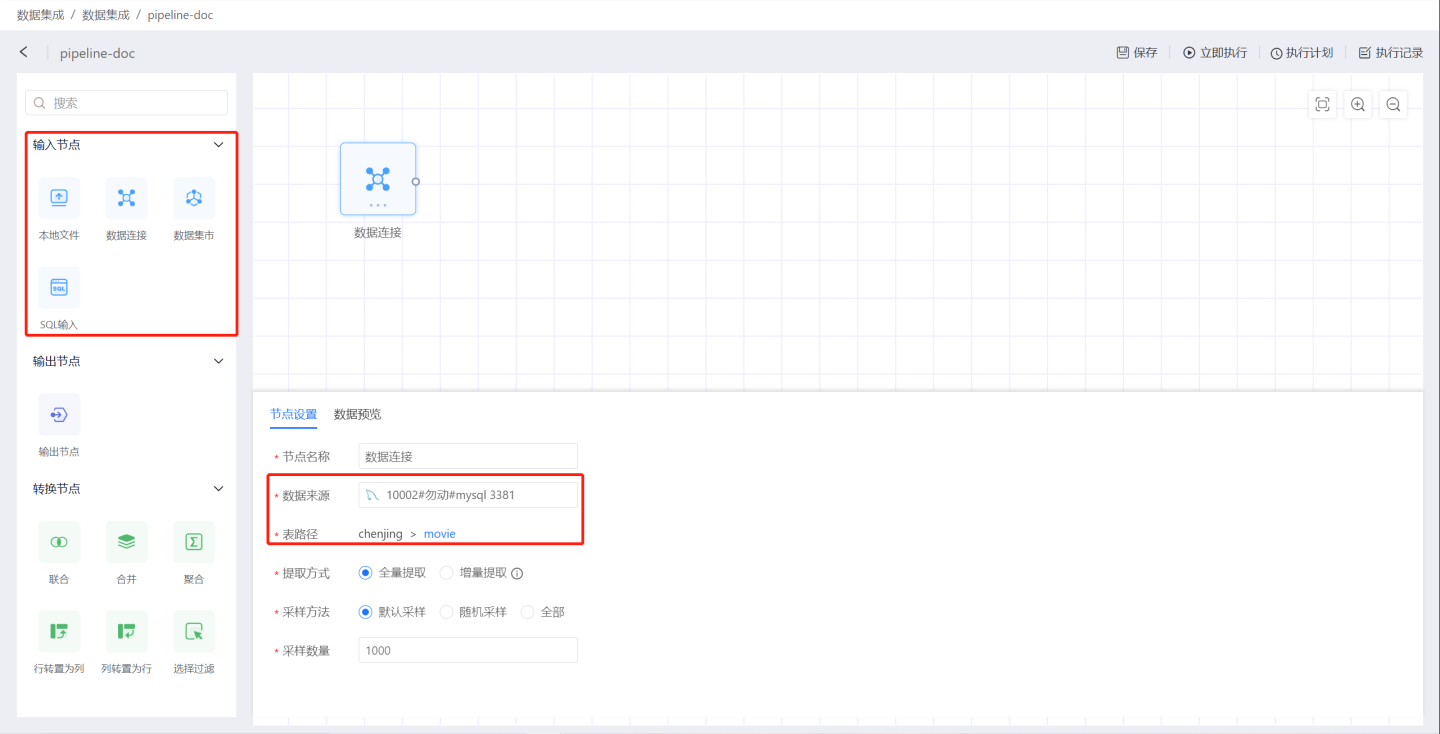 Configure the input node. Set the node name, extraction method, sampling method, and then preview the data to see if it meets the settings. In the example, full extraction is selected, with the default sampling method, and 1000 data entries are taken. For detailed configuration item descriptions, please refer to Input Node.
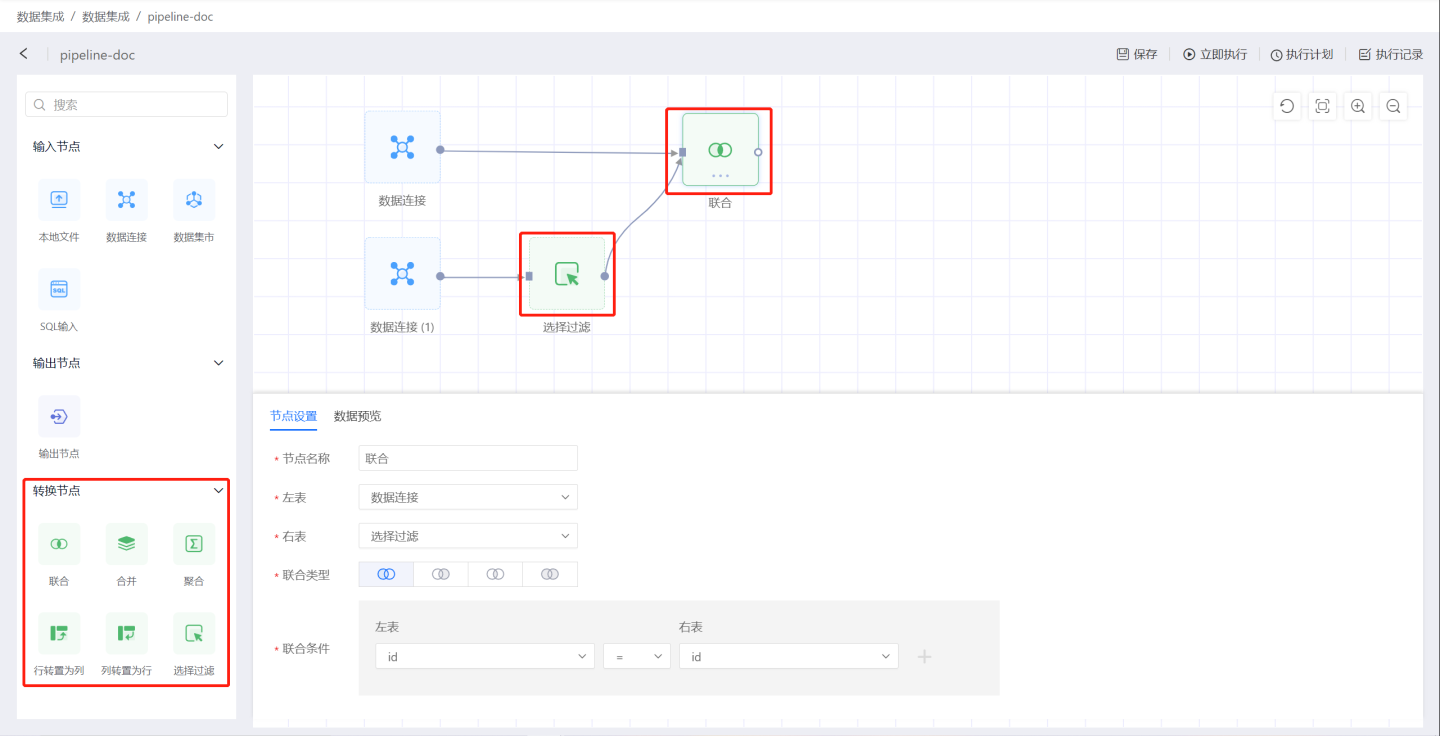
Configure the input node. Set the node name, extraction method, sampling method, and then preview the data to see if it meets the settings. In the example, full extraction is selected, with the default sampling method, and 1000 data entries are taken. For detailed configuration item descriptions, please refer to Input Node.Add a transformation node. Select a transformation node, drag it into the canvas, connect it to the upstream data source, and perform data transformation operations. Supports transformation operations such as Union, Merge, Aggregation, Pivot Rows to Columns, Pivot Columns to Rows, and Select Filter.
Create an output node to store data. Drag an output node into the canvas and connect it to the upstream data, setting the location and table name for data output.
 Configure the output node. Set the validation schema, table operation method, update method, load SQL, and post-load SQL. For detailed configuration item descriptions, please refer to Output Node.
Configure the output node. Set the validation schema, table operation method, update method, load SQL, and post-load SQL. For detailed configuration item descriptions, please refer to Output Node.Complete the construction of a data processing flow by following the above steps. Click the three-dot menu of the output node to execute, and you can view the data processing results.
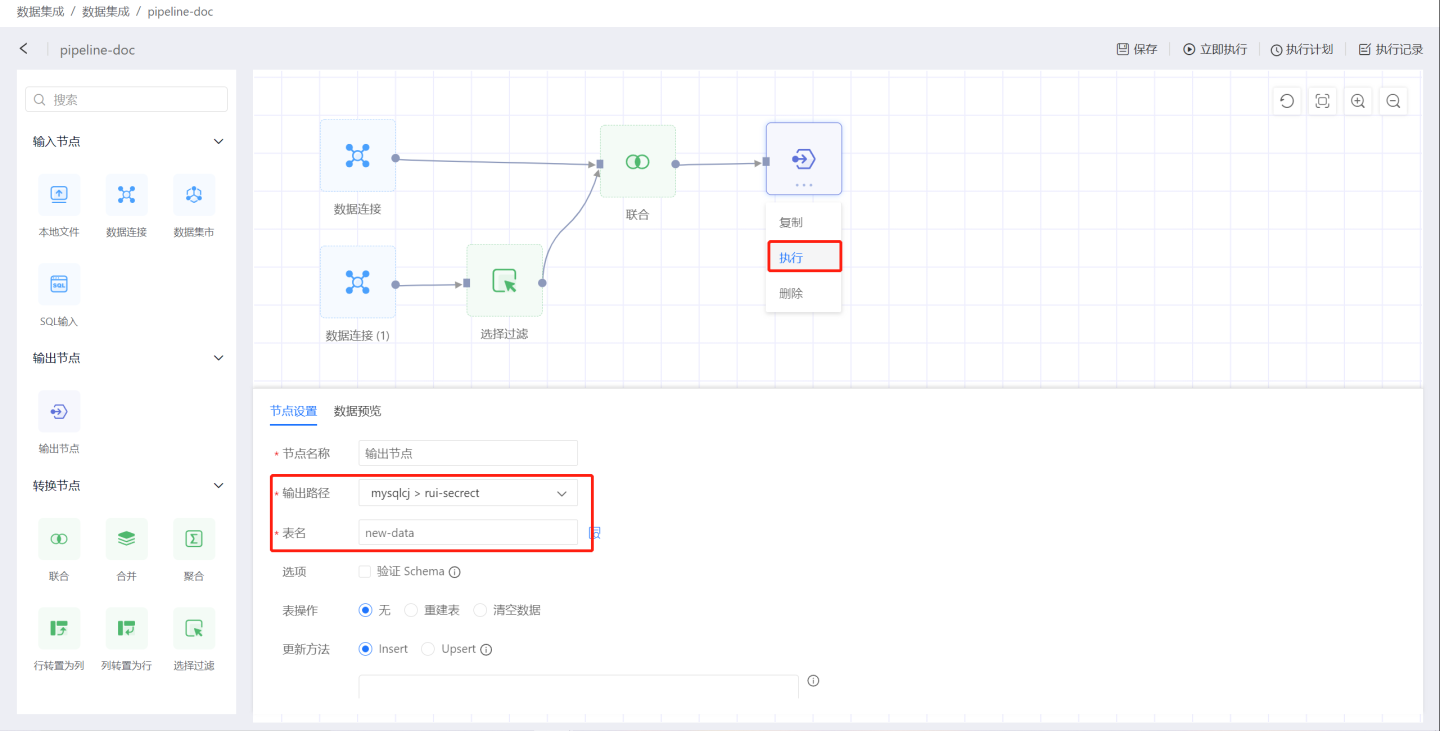
Build other data processing flows in the project.
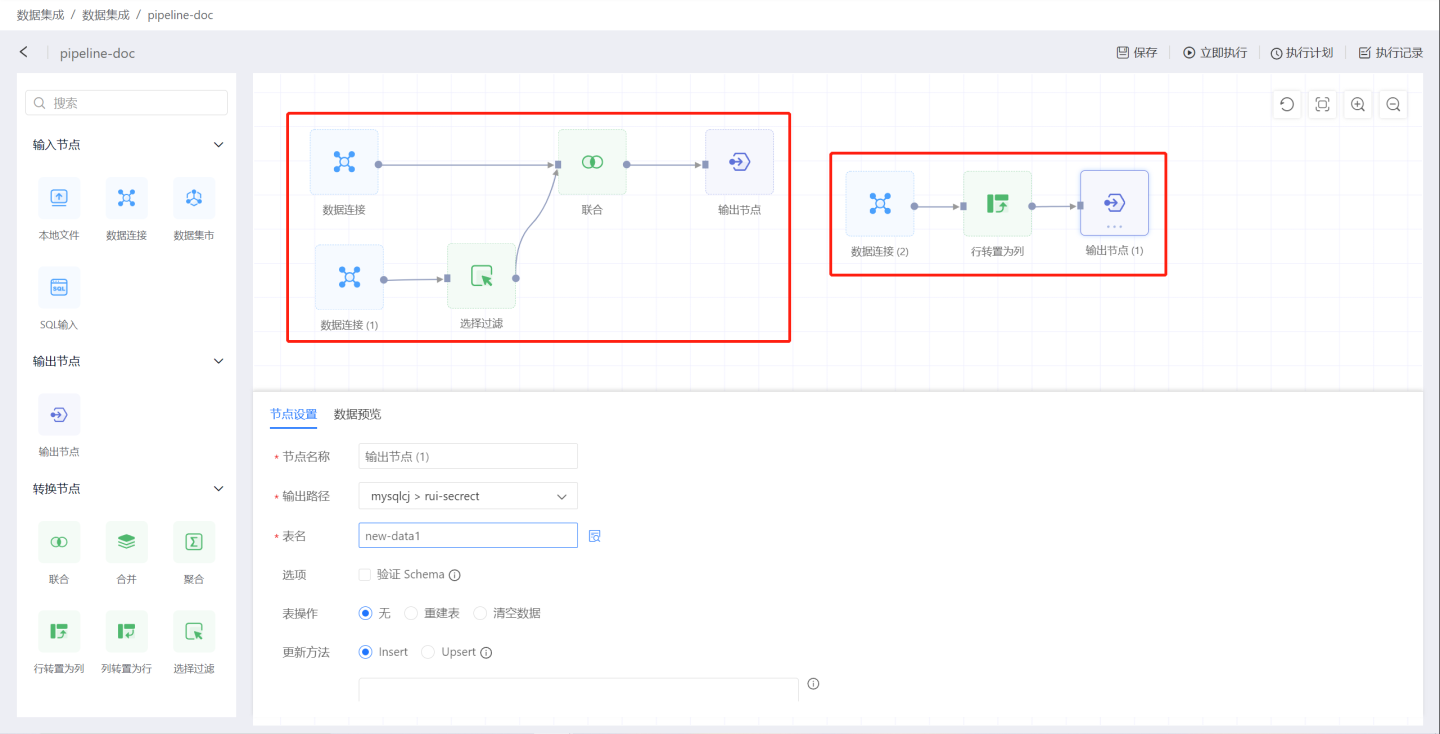
The above example simply demonstrates the creation of a data processing process in data integration. Below is a detailed introduction to the functions and configurations of each node in the data processing process.
Input Node
Data integration sources are implemented through input nodes, where a single input node can connect to multiple transformation nodes or output nodes. Below is a detailed introduction to the functions and configurations of input nodes.
Input Type
Input nodes support four types: local files, data connections, data markets, and SQL inputs.
Local Files
When adding a local file as an input node, files in csv and excel formats are supported for upload.
CSV format file
When uploading a CSV format file, you can set the delimiter, encoding, and other settings according to the local file format, such as setting headers, selecting rows and columns, and setting row and column reversal as needed.
Excel format file
When uploading an Excel format file, you can select the desired sheet from a multi-sheet file, and then set headers, select rows and columns, and set row and column reversal as needed.
Data Connection
When adding tables from data connections as input nodes, they are divided into two main categories: built-in data connections and user data connections:
Built-in Connections: These are the engine data connections embedded within the HENGSHI SENSE system.
User Connections: These are data connections created by the user themselves, as well as authorized data connections that the current account has permission to access. Users can select a table from these connections as an input node.
Tip
If the user only has View Name permissions for the table, the Add button will be grayed out and cannot be used as an input node when previewing the data.
Dataset Market
You can select a dataset from the dataset market as the input node, export the results of the dataset to the output source, and facilitate customer exploration and use.
SQL Input
SQL input node refers to the data content of an input node defined using SQL language. First, select the data connection, and then use SQL language to define the data object.
Data Extraction Method
Data import is divided into two methods: full extraction and incremental extraction.
Full Extraction
Full Extraction will extract all data from the input node each time.
Incremental Extraction
Incremental Extraction requires selecting an Incremental Field, and only data with an incremental field value greater than the maximum value of that incremental field in the currently imported data will be extracted.
Tip
When performing incremental extraction, the incremental field must be of numeric or date type, with granularity from large to small, such as: year > month > day or datetime field > unique id. During incremental extraction, the Data Preview will only display data where the incremental field value is greater than the maximum value in the output table. If there is no data in the input table with an incremental field value greater than the maximum value, the preview data will be empty.
Data Batch Extraction
When the amount of data extracted is large, the data import time may exceed the query time of the source database, leading to data extraction failure. In this case, you can set the maximum limit for one-time data extraction through the configuration item ETL_SRC_MYSQL_PAGE_SIZE. When the limit is exceeded, the data is extracted in batches. Currently, only MySQL data sources support batch extraction.
Please contact the technical staff to configure ETL_SRC_MYSQL_PAGE_SIZE.
Data Sampling
Data sampling is a debugging feature that allows for previewing the data extracted from the input node in this data processing session. The amount of sampling does not affect the actual amount of data extracted during runtime.
If the sampling quantity is greater than 0 but the preview data is empty, it indicates that the extracted data is empty. During node execution, no data will be loaded into the dataset.
Sampling methods are divided into three types: Default Sampling, Random Sampling, and All.
Default Sampling: That is, according to the storage location of the data in the database, sequentially extract the specified number of samples from the sampling quantity.
Random Sampling: That is, without paying attention to the storage location in the database, randomly extract the specified number of samples from the sampling quantity.
All: When the sampling method is selected as "All", all data in the database is extracted, and the sampling quantity cannot be manually set again.
Output Node
Data processed is stored in the specified database through the output node. Below is a detailed introduction to the output node.
Basic Information
Output node basic information includes node name, output path, and table name.
Node Name: Refers to the name of the output node in the canvas, which can be modified.
Output Path: The path where the data is stored. By default, it is the destination selected when creating a new project and can be modified. Currently supported are MySQL, Apache Doris, StarRocks, PostgreSQL, Greenplum, Oracle, SQL Server, ClickHouse, Dameng, Saphana, Presto, Amazon Redshift, Amazon Athena, Alibaba Hologres, TDSQL MySQL, TDSQL PostgreSQL, and AnalyticDB MySQL as the output node storage path.
Table Name: The name of the table in the database where the data is stored after the output node execution. The default table name is Output Node.
Tip
The current user must have read and write (RW) permissions for the output directory or output table for the project to execute successfully.
Output Settings
Output settings include: schema validation, table operations, update methods, pre-load SQL, and post-load SQL. The execution order in the output node is pre-load SQL -> schema validation -> table operations -> update methods -> post-load SQL.
Validate Schema
Validating the Schema will verify whether the input fields match the output table fields.
When
Validate Schemais selected, the output node will only run if the schema matches; otherwise, an error will be reported during the execution of the output node. The matching rules are:- The number and names of fields on both sides must be the same; mismatched numbers or names are considered mismatches.
- For fields with the same name, the original type must be converted to the same HENGSHI SENSE type. Among them, the HENGSHI SENSE type (number/text/date/boolean/json) is identified by the type field in the backend.
When
Validate Schemais not selected, the following processing will be performed on the output table:- For fields missing in the input table, the output table fields will be filled with null.
- For extra fields in the input table, the output table will add these fields and fill new rows; for existing rows in the output table, they will be filled with null.
- If the field names are the same but the field types are incompatible, such as the output table field type being number and the input table field type being string, the project execution will fail.
- If the field names are the same and the field types are compatible, such as the output table field type being text and the input table type being number, the project execution will succeed.
Table Operations
Table operations are defined as actions performed on an existing output table. This option has no effect when creating a new table.
None: Indicates that no operation is performed on the output table, and it remains unchanged.
Rebuild Table: Deletes the existing output table and then rebuilds the table according to the input field Schema.
Clear Data: Clears the data in the table.
Tip
- When rebuilding a table in actual operation, a temporary table is first created in the output path to store the data processing results. When the data processing is complete, the original output table is deleted, and the temporary table is renamed to the original output table. However, in the TDSQL-MySQL data source, since the operation of renaming a temporary table is not supported, the original output table can only be deleted first. If an exception occurs during the data processing, the new output table will have no data. Therefore, please choose carefully when using the TDSQL-MySQL data source.
Update Method
Define how the input data is updated to the output table.
Insert: Insert data into the output table, i.e., append to the output table.
Upsert: Upsert = Update + Insert, update existing rows and insert new rows.
Tip
When selecting Upsert, you must set the key fields to identify existing rows in the output table. For existing rows, update the existing rows based on the key fields. For non-existing rows, insert them directly into the output table.
Key Field
Key fields are used as primary keys and distribution keys. Key fields have two functions.
- Used as the primary key for incremental updates.
- Used as the primary key and distribution key when creating a table. If table properties are set during table creation, the configuration of table properties takes precedence, and the key field, even if set, will not take effect.
Table Properties
During the creation of the data synchronization table, customize partition fields and index fields to distribute the data storage. The table properties only take effect during the first table creation. Currently, data sources that support table properties include Greenplum, Apache Doris, StarRocks, and ClickHouse. Example:
DISTRIBUTED BY (username)
PARTITION BY RANGE (username)
( START (varchar 'A1') EXCLUSIVE
END (varchar 'A8') INCLUSIVE,
DEFAULT PARTITION extra
);SQL Before Loading
The SQL executed before loading the extracted input data into the output table is the first configuration executed by the output node.
SQL After Loading
The SQL executed after loading the extracted input data into the output table is the final configuration executed by the output node.
Conversion Node
The transformation node is part of the T in ELT, making data integration capabilities more robust and helping enterprises meet the needs of agile business preprocessing. By incorporating transformation nodes into the data processing pipeline, data cleaning and transformation operations can be performed in a low-threshold, visual manner, meeting flexible data processing requirements.
Union
The union node enables the joint processing of two data sources, as shown in the figure. Connect the data sources to be merged, then select the union type and conditions, and the union node operation is completed. Preview the data processing results through data preview. 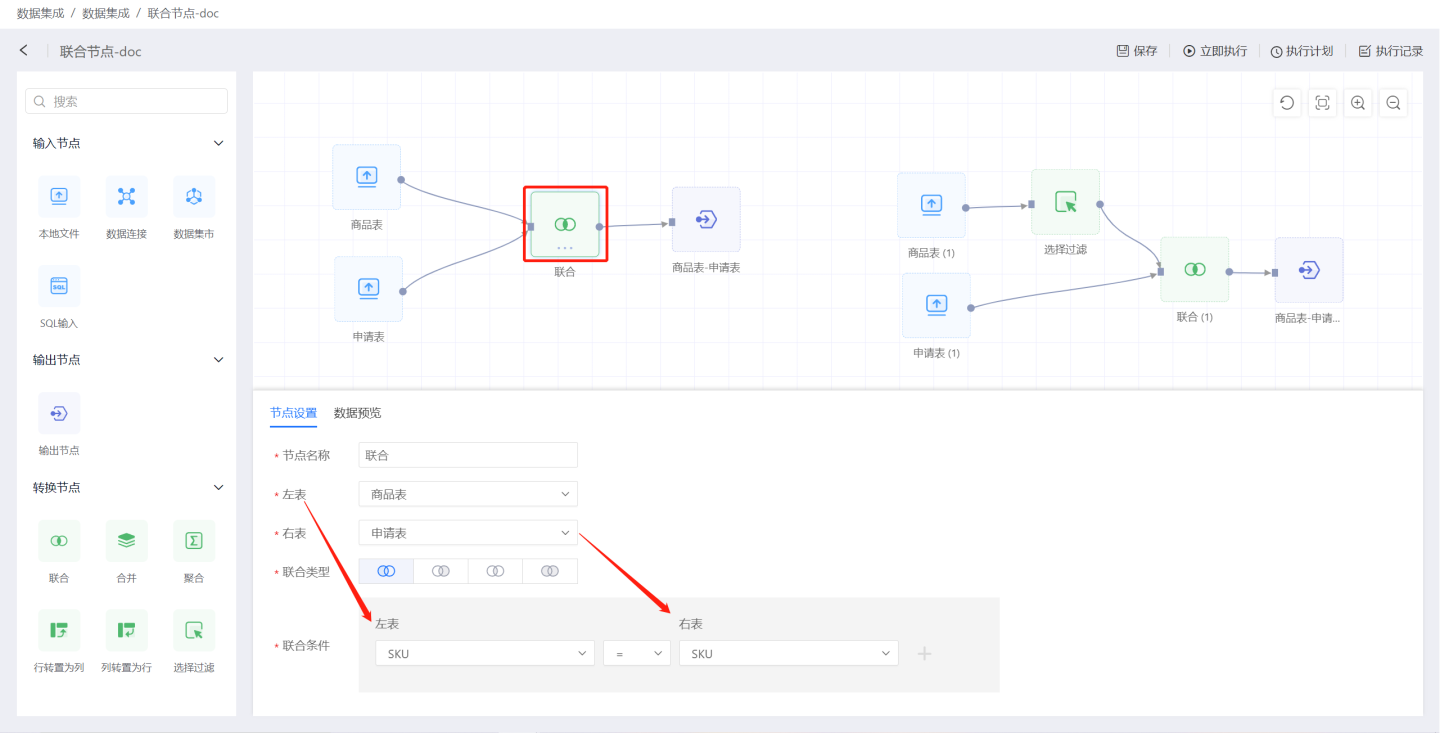
Joint Node Configuration Content Description:
- Node Name: Defaults to
Union, supports user modification. - Left Table: The data source to be unioned, designated as the left table.
- Right Table: The data source to be unioned, designated as the right table.
- Union Type: Supports four types of joins: left join, right join, inner join, and outer join.
- Union Conditions: Can set one or multiple union conditions.
Tip
The union node only supports union operations on two data sources.
Merge
Merge nodes combine multiple data source information into a single table. As shown, connect the nodes of the January to March order tables to the merge node to generate the quarterly order table. 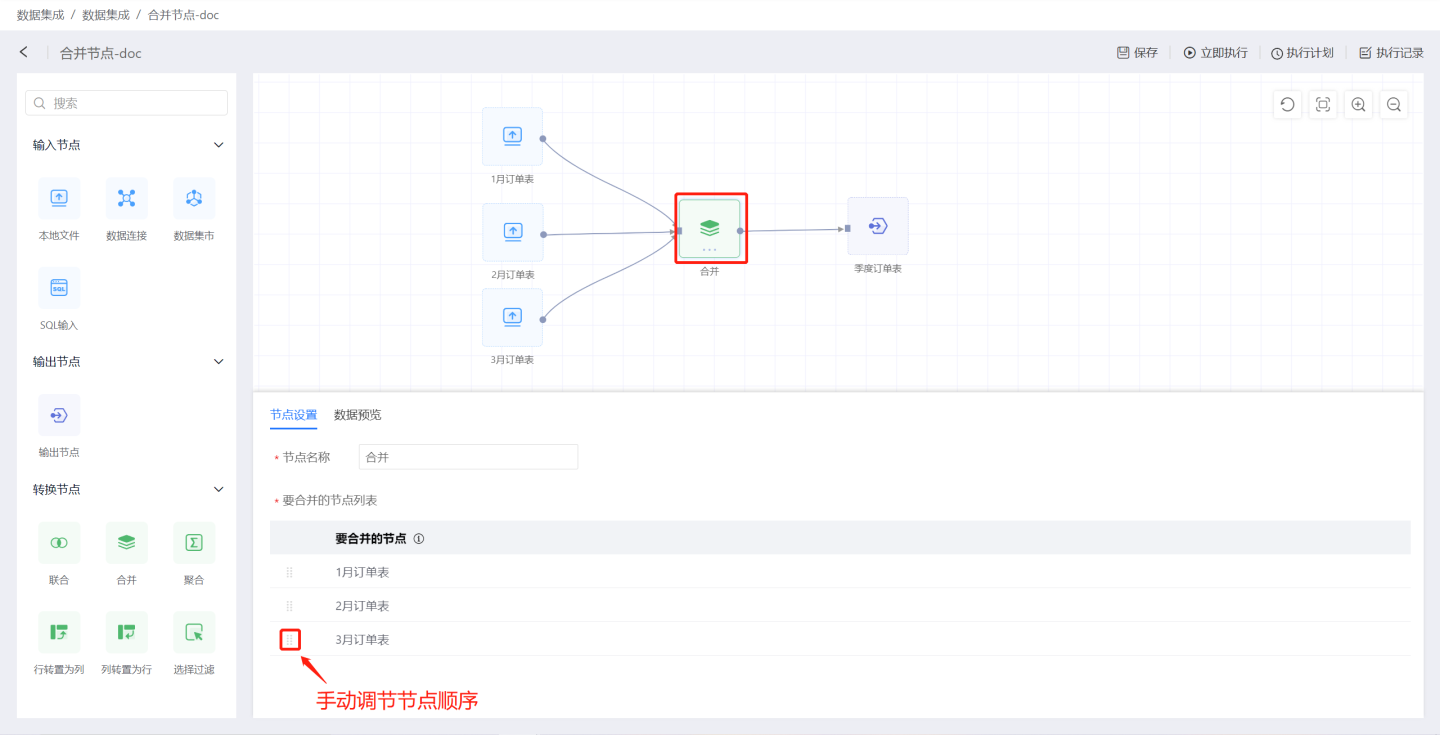
Merge Node Configuration Content Description:
- Node Name: Defaults to
Merge, supports user modification. - Merge Node List: Data nodes to be merged, sorted by connection order. Supports manual adjustment of the order.
Merge Rules:
- The first node in the merged node list serves as the basis for the data. The field names, field types, and field order of this node will be used as the field names, field types, and field order of the output data.
- Starting from the second node, merge with the first node according to the following rules:
- When the field name is the same as the field name of the first node and the types are the same, fill the field content into the corresponding field of the output data.
- When the field name is the same as the field name of the first node but the types are different, attempt to convert the type. If the conversion is successful, fill the field content into the corresponding field of the output data; if the conversion fails, fill the corresponding field of the output data with NULL.
- When the field name is different from the field name of the first node, the field is discarded.
- When a field does not exist in the first node, the corresponding field in the output data is filled with NULL.
- Support manual adjustment of the merge node order.
Aggregation
Aggregation nodes refer to operations that aggregate input data sources. As shown in the figure, the order prices and shipping fees from the January order table are aggregated to generate the order amount table.
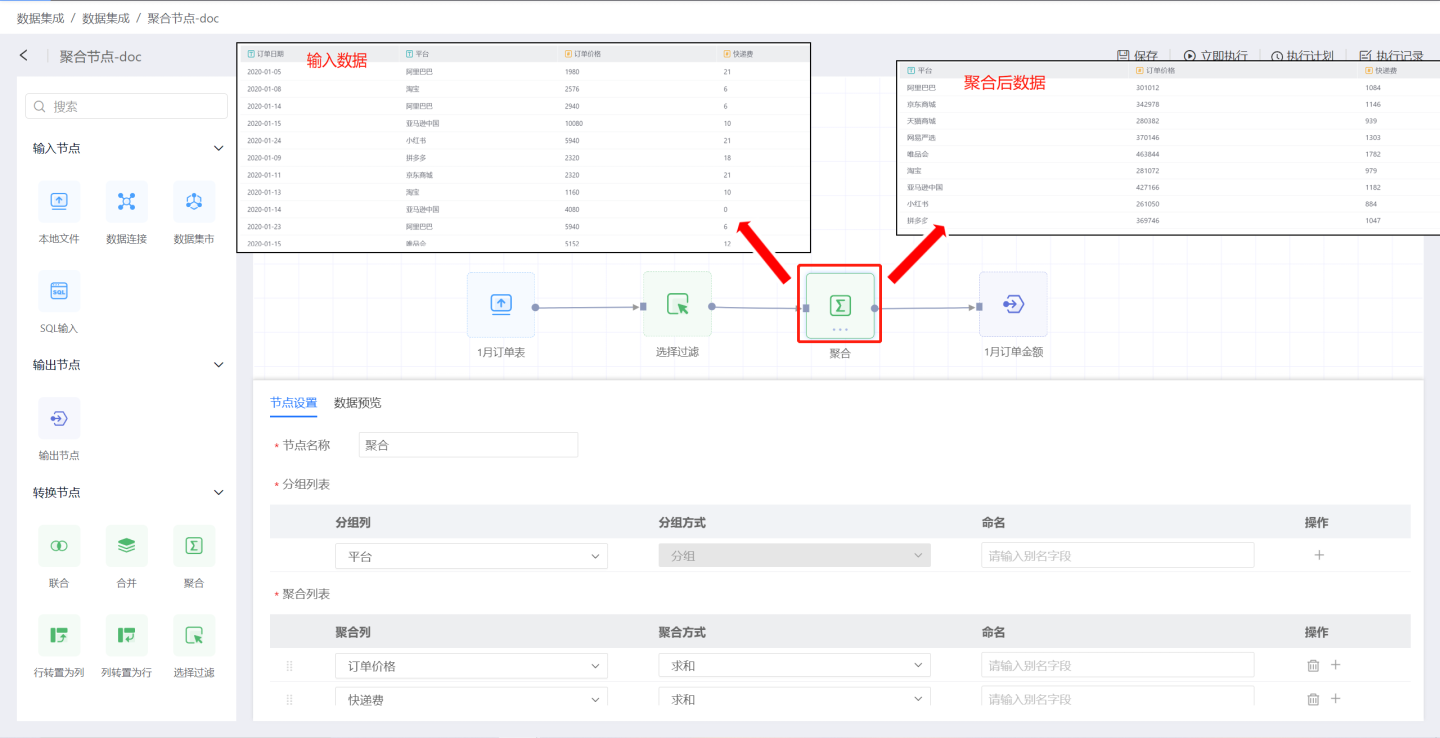 Aggregation Node Configuration Content Description:
Aggregation Node Configuration Content Description:
Node Name: Defaults to
Aggregation, supports user modification.Group List: Retains fields from the input data. The Group List adds fields from the input data to the output data, allowing fields to be renamed. Multiple fields can be added.
Aggregation List: Performs aggregation operations on fields in the input data. Numeric fields support aggregation operations such as average, sum, maximum, minimum, count, and distinct count. Non-numeric fields support aggregation operations such as maximum, minimum, count, and distinct count.
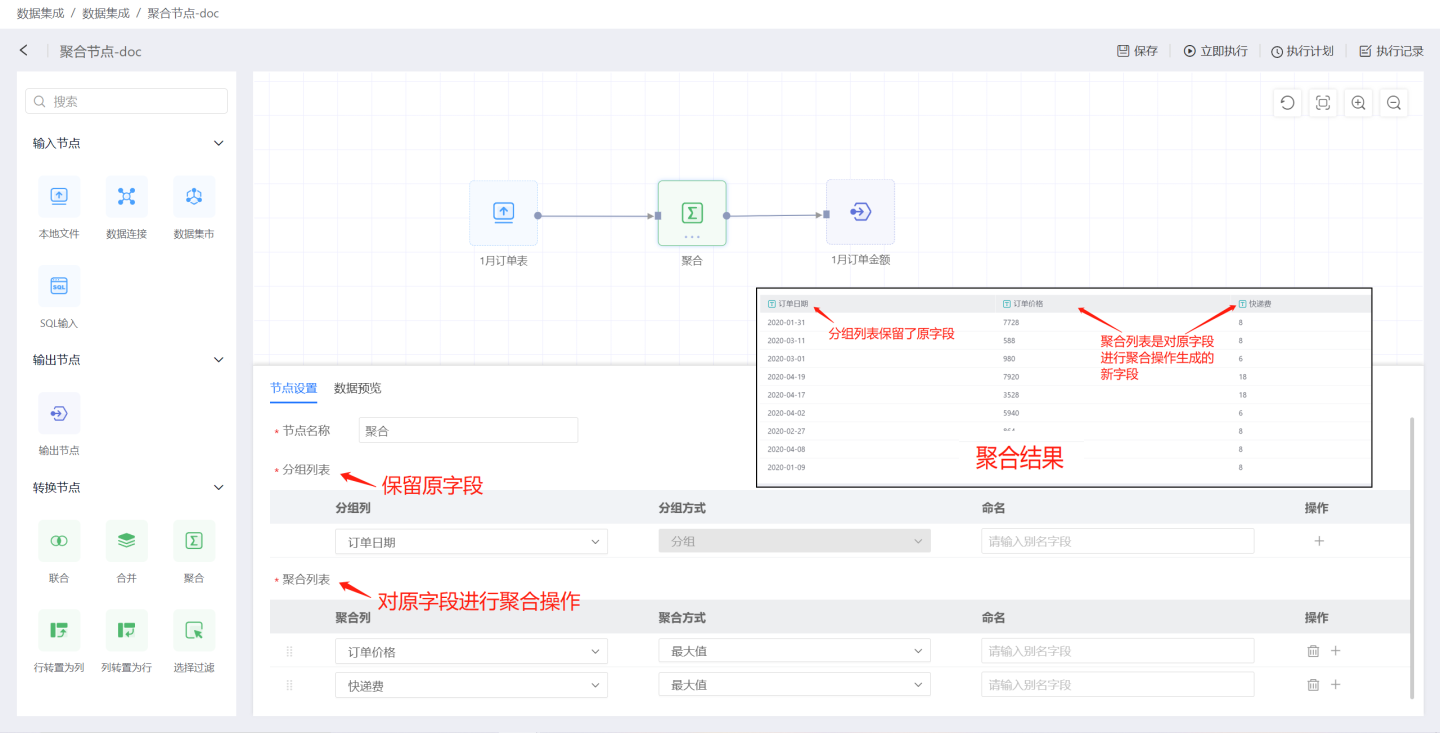
Tip
Fields in the aggregation list are displayed after the fields in the grouping list.
Select Filter
Select the filtering node to perform selection and filtering operations on the input data. As shown in the figure, by selecting the filtering node, the average price per order for each platform from the orders is selected, and finally, the relevant information on the Taobao platform is filtered out through the filtering function. 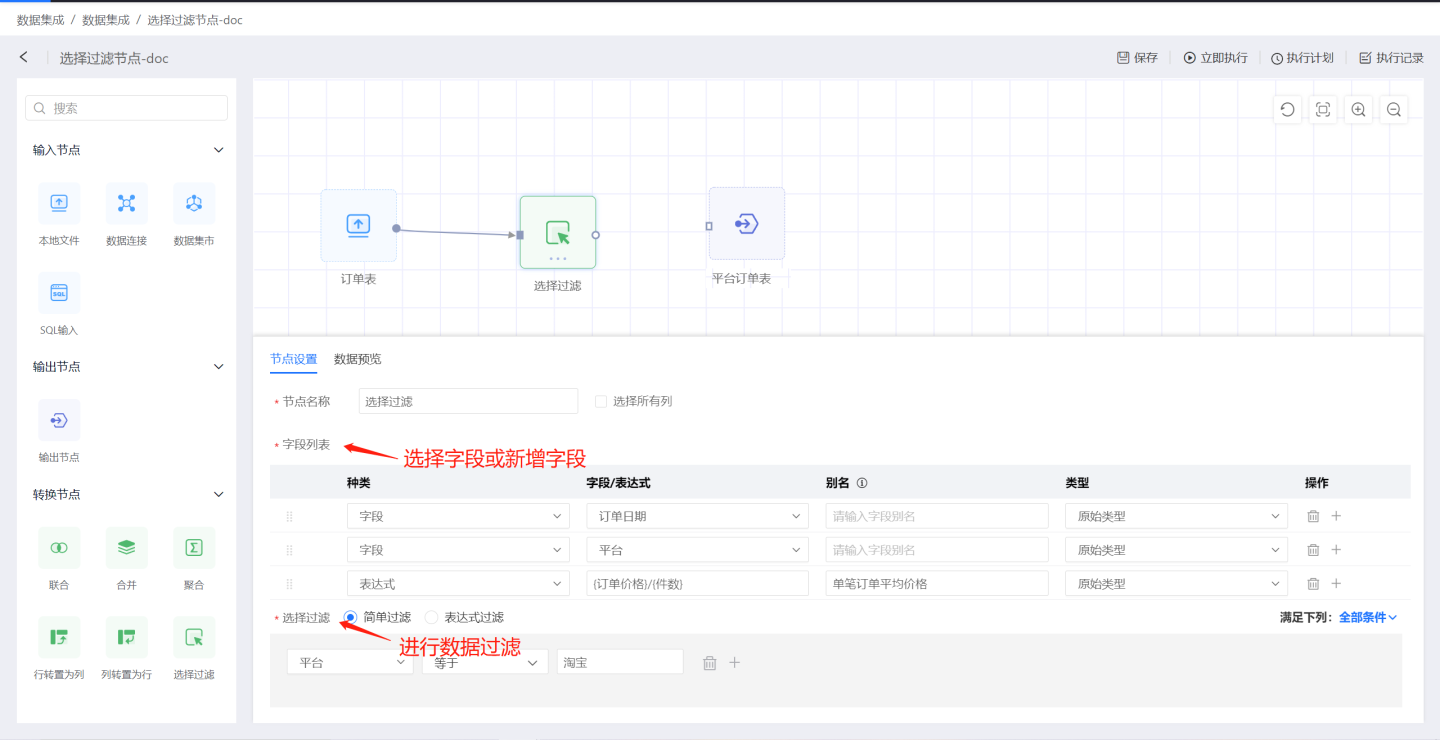
Select Filter Configuration Content Description:
Node Name: Defaults to
Select Filter, supports user modification.Select All Columns: When checked, all columns from the input data will be added to the output data, but they will not be displayed in the field list.
Field List: Add column fields independently. Supports adding existing fields and creating new fields using expressions.
- Field: Add original fields from the input data, with the ability to modify aliases and field types. If
Select All Columnsis already checked, please modify the alias when adding fields to avoid duplicate field names. - Expression: Create new fields using expressions.
- Field: Add original fields from the input data, with the ability to modify aliases and field types. If
Filtering Method
- Simple Filter: Users set filtering conditions through options. When there are multiple filtering conditions, you can set the condition selection method as 'All Conditions' or 'Any Condition'. 'All Conditions' means the filtered data must meet all filtering conditions. 'Any Condition' means the filtered data only needs to meet one of the conditions.
- Expression Filter: Users set filtering conditions through expressions, allowing for more flexible data filtering. The filtering expression must return a boolean value. On the right side of the expression editing area is the function list, available for use in expressions.
Select the typical usage scenarios for the filter node.
Scenario 1: Add fields by selecting
All Columnsand set filtering conditions. Do not add fields using the field list. As shown in the figure, only checkAll Columns, and do not add fields in the field list. Use simple filtering to filter out data with the platform as Xiaohongshu.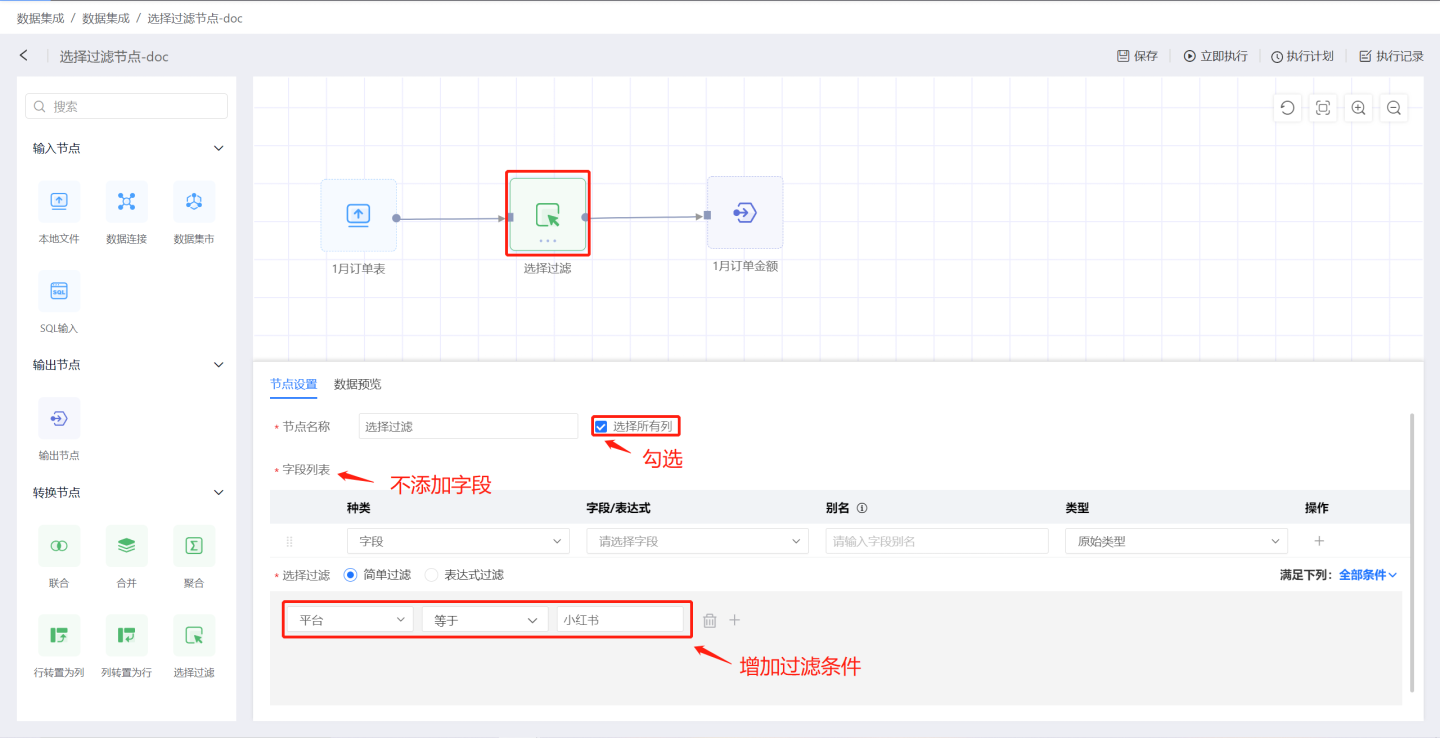 The output result is shown in the figure, which includes all field information from the input data and filters out data with the platform as Xiaohongshu.
The output result is shown in the figure, which includes all field information from the input data and filters out data with the platform as Xiaohongshu. 
Scenario 2: Add fields in the
Field Listand filter the fields. As shown in the figure, select the original fieldsOrder DateandPlatformfrom the field list, and create a new fieldProduct Priceusing an expression.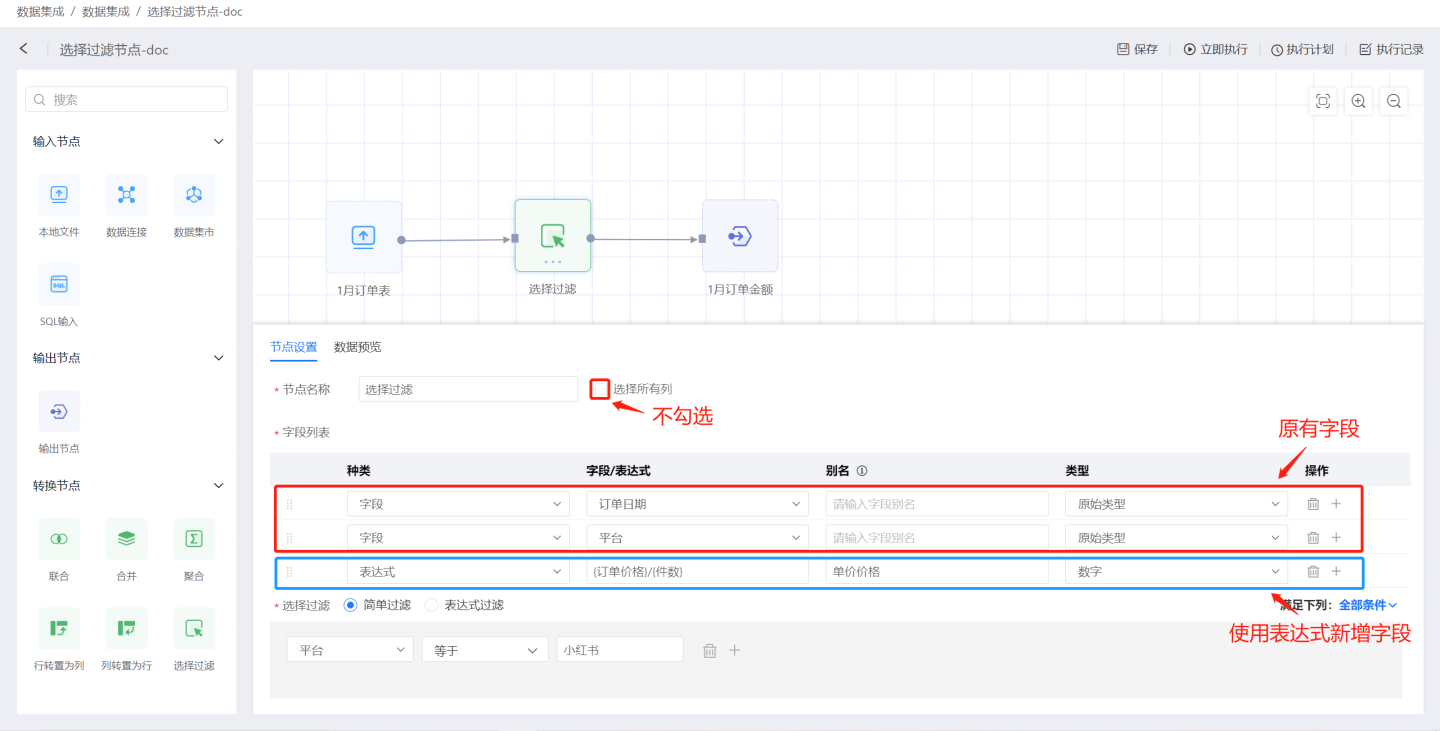 The output result is shown in the figure, which includes only the 3 fields created in the field list, and filters out data with the platform as Xiaohongshu based on the filtering conditions.
The output result is shown in the figure, which includes only the 3 fields created in the field list, and filters out data with the platform as Xiaohongshu based on the filtering conditions. 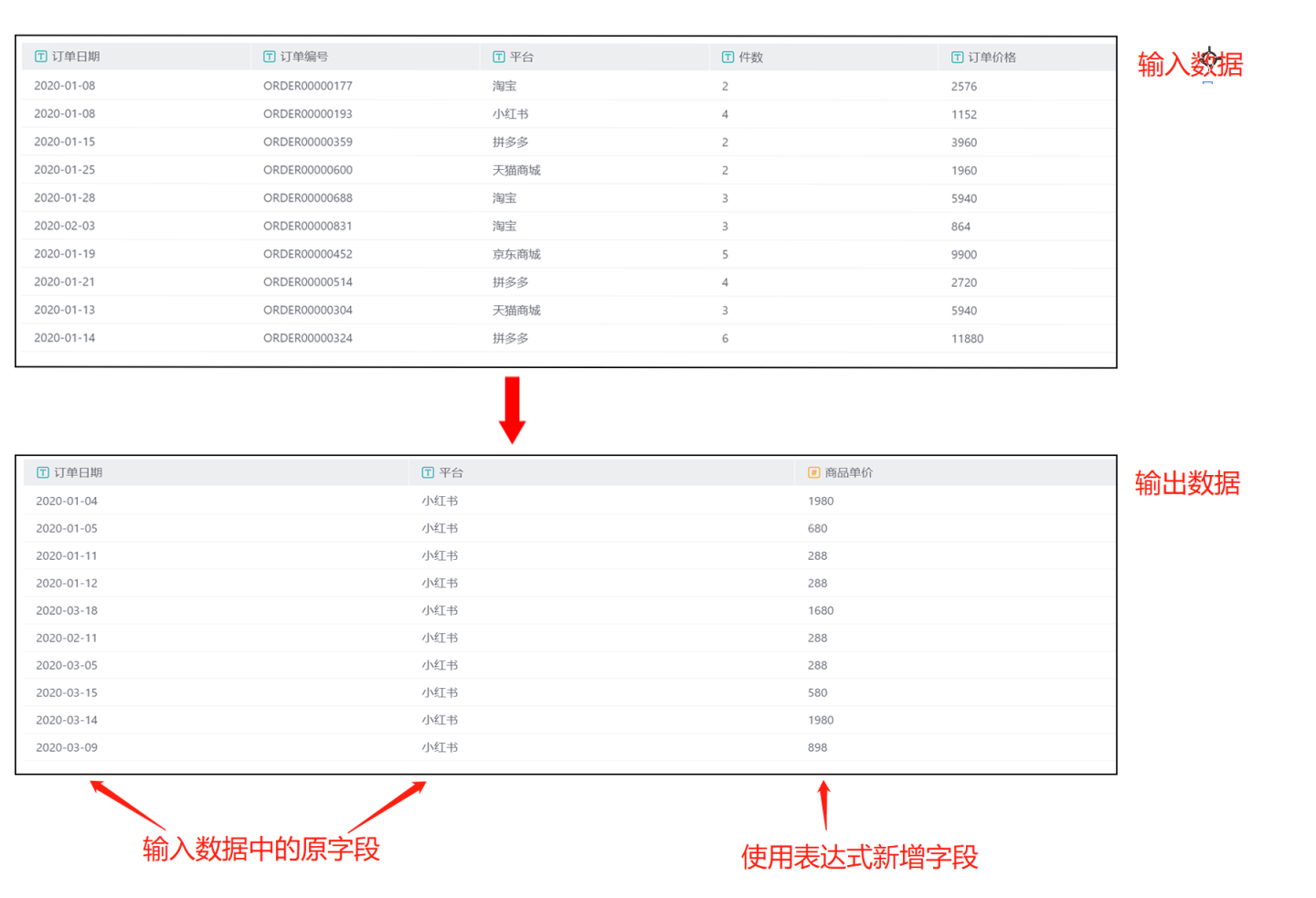
Scenario 3: Add fields by selecting
All Columnsand theField List, and set filtering conditions. As shown in the figure, checkAll Columns, and add the original fieldsOrder DateandPlatformin the field list, modify the field alias and type, and create a new fieldProduct Priceusing an expression.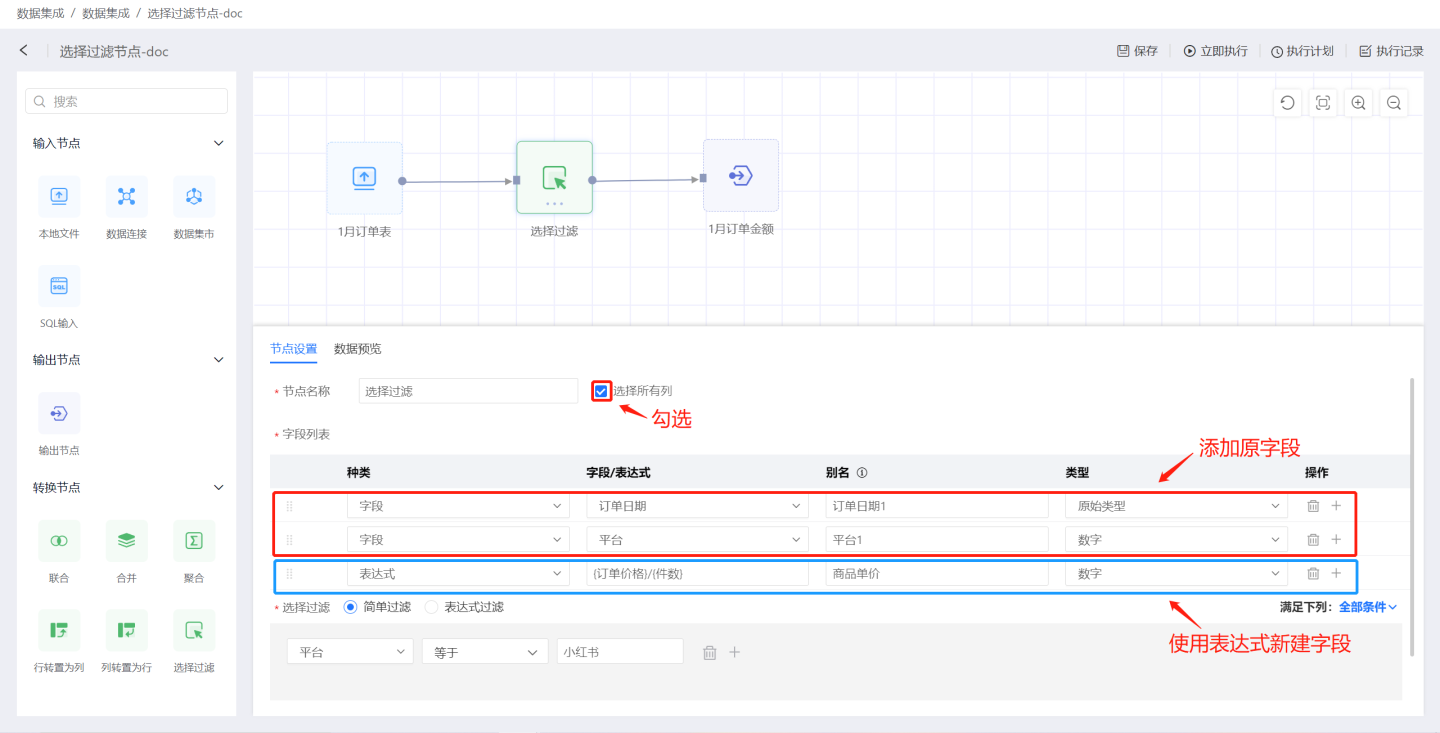 The output result is shown in the figure, which includes all fields from the input data, in addition to the 3 fields created in the field list, and filters out data with the platform as Xiaohongshu based on the filtering conditions. The
The output result is shown in the figure, which includes all fields from the input data, in addition to the 3 fields created in the field list, and filters out data with the platform as Xiaohongshu based on the filtering conditions. The Order DateandPlatformin the field list are the original fields added, which conflict with the field names inAll Columns, so the alias needs to be modified.Platform1attempted a numeric type conversion, which failed, so null is used for filling.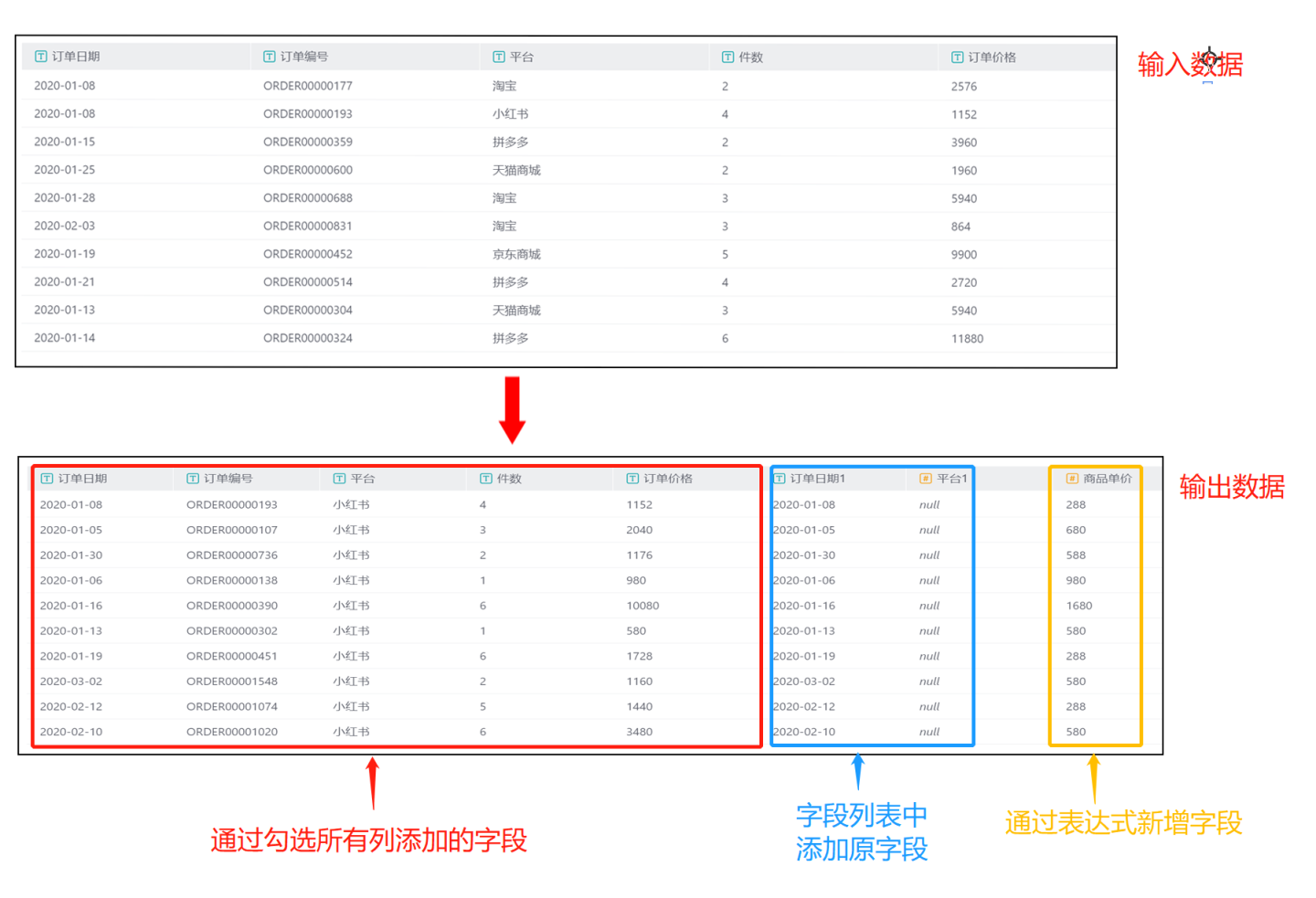
Transpose Rows to Columns
Transposing rows to columns involves converting the values of a specific row in the input data into columns for display. As shown in the figure, the values of the platform field, such as Taobao, Tmall Mall, and JD Mall, are converted into column names to view the total order fees for these three platforms. 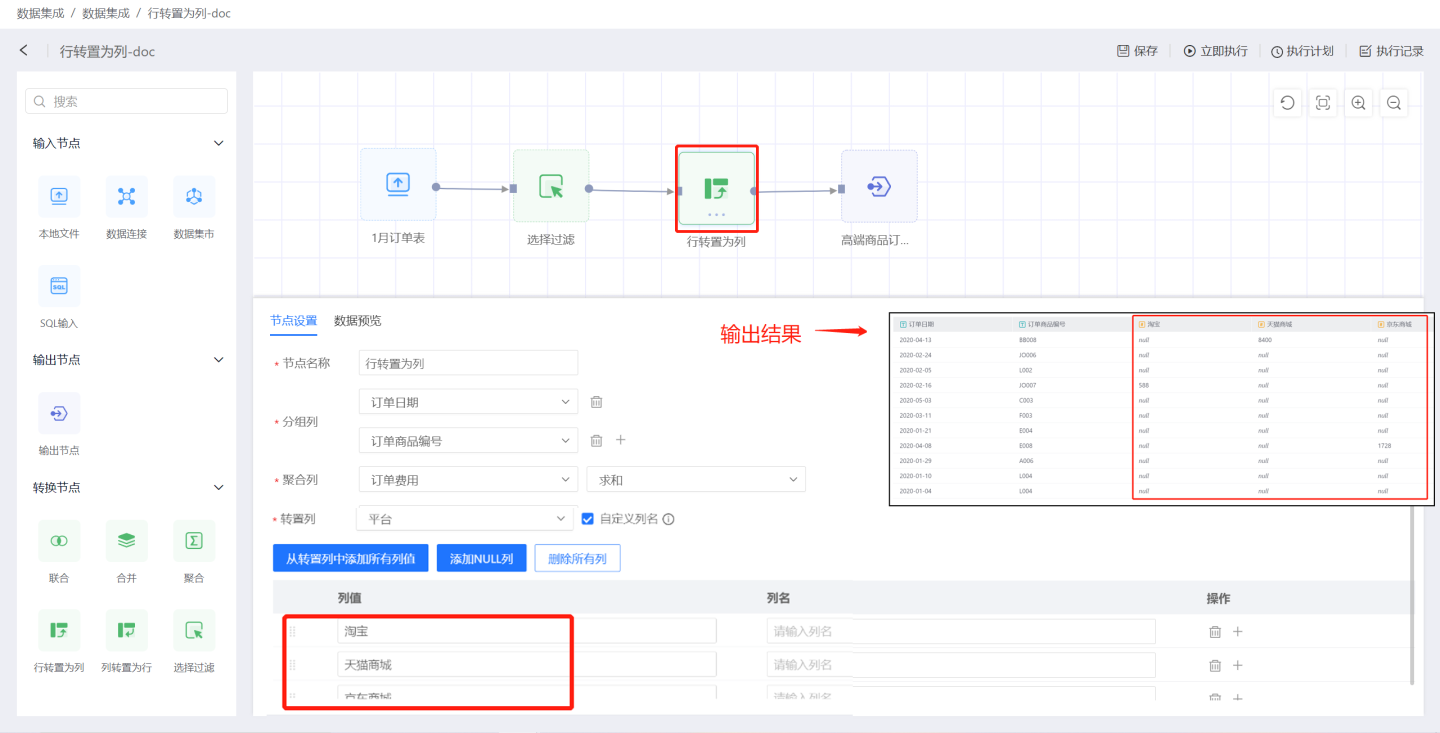
Transpose Rows to Columns Node Configuration Content Description:
- Node Name: Defaults to
Pivot Rows to Columns, supports user modification. - Grouping Columns: Adds the original fields from the input data to the output data, allowing the addition of one or more fields.
- Aggregation Columns: The values of the aggregation columns are used to populate the pivoted columns. When the aggregation column is of numeric type, it supports aggregation operations such as average, sum, maximum, minimum, count, and distinct count. For non-numeric types, it supports operations such as maximum, minimum, count, and distinct count.
- Pivot Columns: The fields that need to be pivoted into columns. By default, the values of this field will be presented as columns. Supports user-defined column names. Users can manually add column value fields or use shortcut buttons for operation.
- Add All Column Values from Pivot Columns Displays all column values of the pivot column field, allowing users to select the desired column values for conversion using the delete button, and also modify aliases.
- Add NULL Column Adds a column with NULL values.
- Delete All Columns Deletes all column information displayed in the list.
Data Integration Row-to-Column Node Typical Use Cases.
- Scenario 1: Using the default method, all values in the transpose column are displayed in column format without customizing column names. In the example, the node configuration adds grouping columns
Order DateandOrder Product ID, and converts all column values ofPlatformin the transpose column into column names, using the sum ofOrder Costin the aggregation column as the value of the transpose column.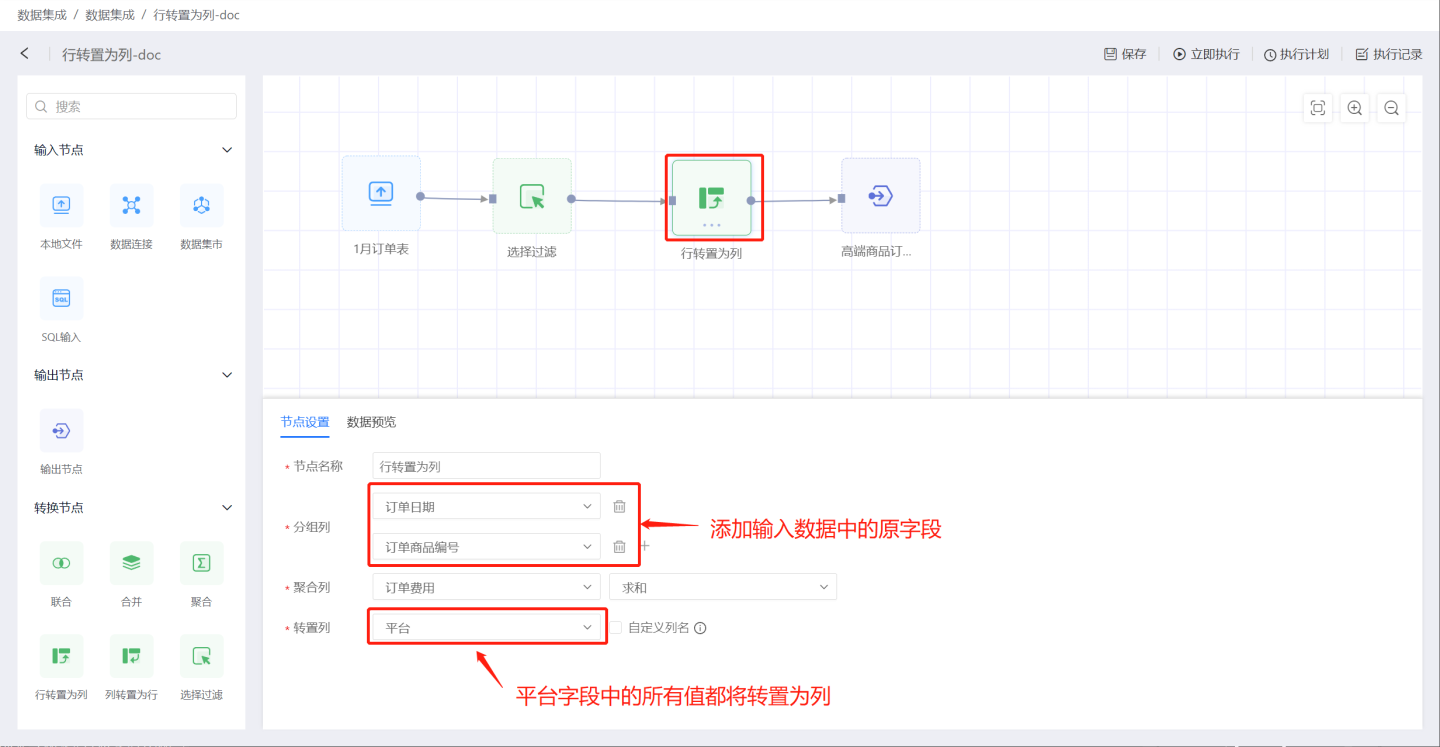 The output result includes the two columns
The output result includes the two columns Order DateandOrder Product IDfrom the original data, with all values inPlatformconverted into columns (red box part), and these columns are filled with the total sum ofOrder Cost(blue box part).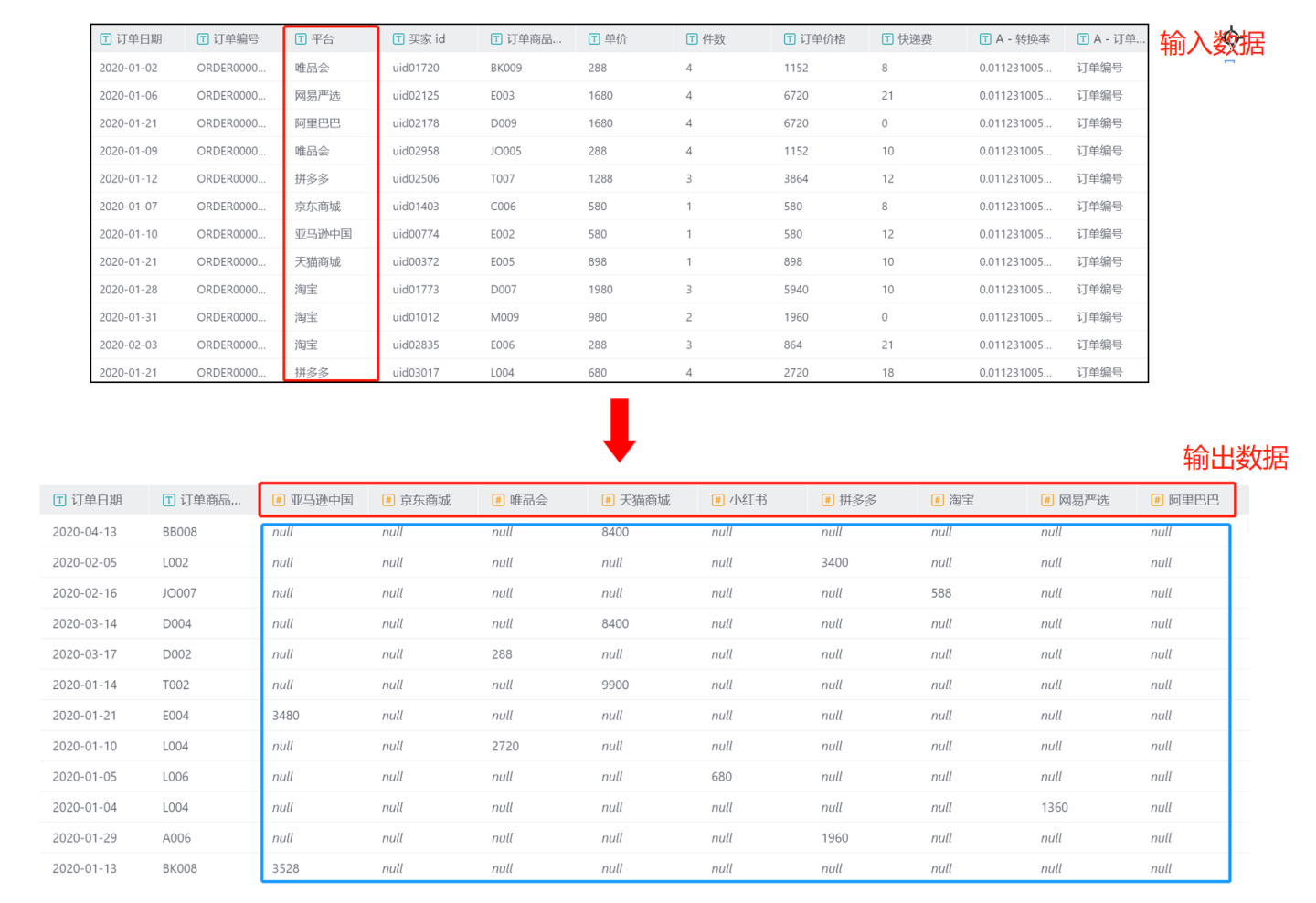
- Scenario 2: Customizing and adding values for the transpose column. Adding values in the transpose column values, and also adding values in the non-transpose columns. In the example, manually add the column values
Taobao,Tmall,JD.com,Null, andWeidianfrom the platform.NullandWeidianare not values originally in the transpose column. The output result includes the two columns
The output result includes the two columns Order DateandOrder Product IDfrom the original data, containing the three column valuesTaobao,Tmall, andJD.comfromPlatform, and filled with the total sum ofOrder Cost.NullandWeidianare values not in the transpose column, and since there is noOrder Costinformation related to these fields in the original fields, they are filled with null.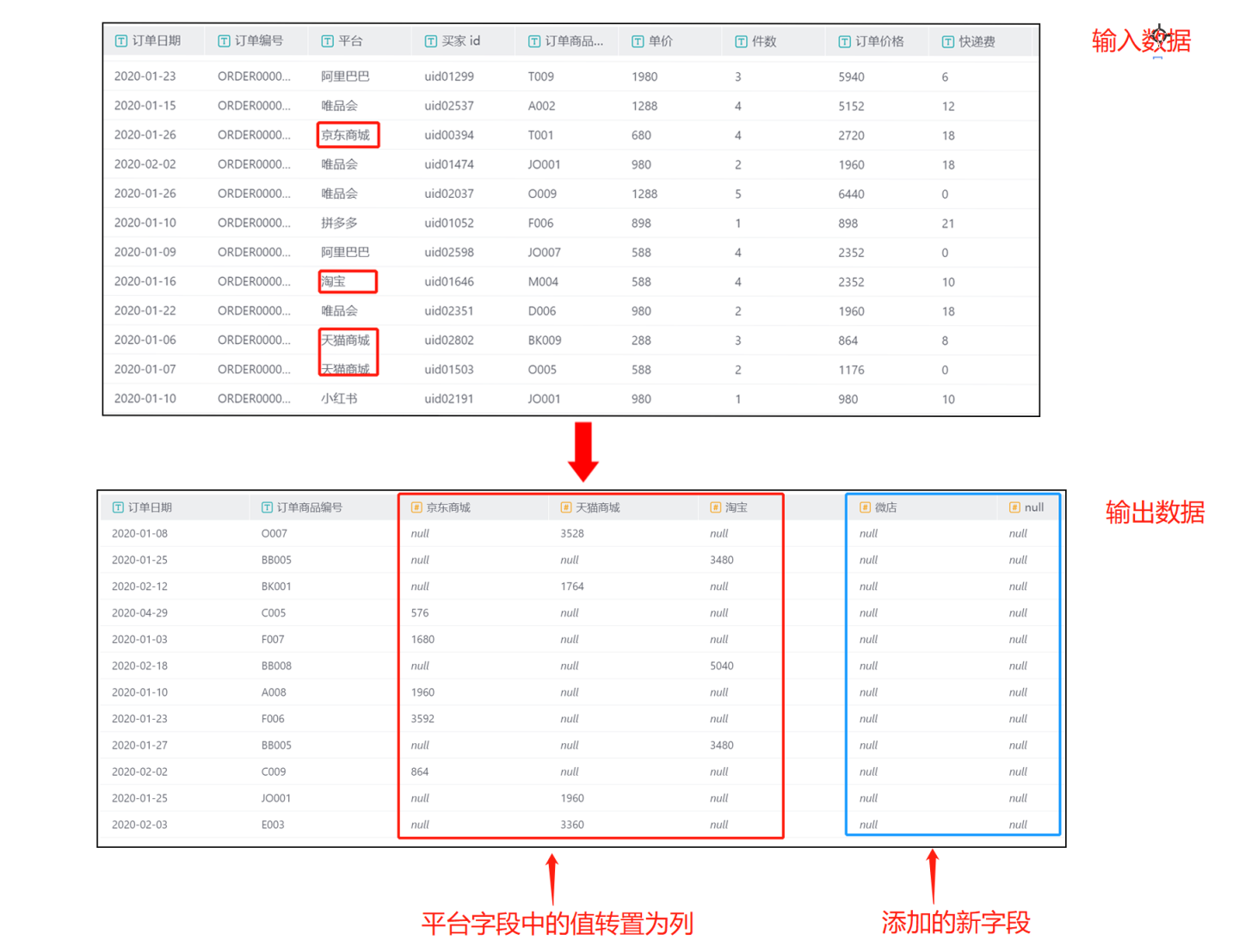
Column Transpose to Row
Transposing columns into rows involves summarizing and converting the values of several columns with common characteristics into rows for display. As shown in the figure, robots, manipulators, auxiliary machines, and water, electricity, and gas are all part of the components, which are organized into the components column for display. 
Column to Row Node Configuration Content Description:
- Node Name: Defaults to
Transpose Columns to Rows, supports user modification. - Transpose Group Columns:
- Group Column Name: The field name after the transpose column is converted to rows. The group column types include text, number, and date. The transpose column is the column to be converted to rows, and you can modify the group values, supporting adding multiple transpose columns.
- Transpose Value Columns: The new column name where the values of the transpose column are located after being converted to rows.
Dataset column transposition to row node typical use cases.
- Scenario 1: Convert columns with common characteristics into groups for display, and modify the grouped values after conversion. In the example, columns such as
机器人,机械手,辅机,水电气,自动化are converted into rows stored in the new column部件, and the values of these columns are stored in the new column个数. Among them, the two columns水电气and自动化are renamed to水电气装备and自动化组件after conversion.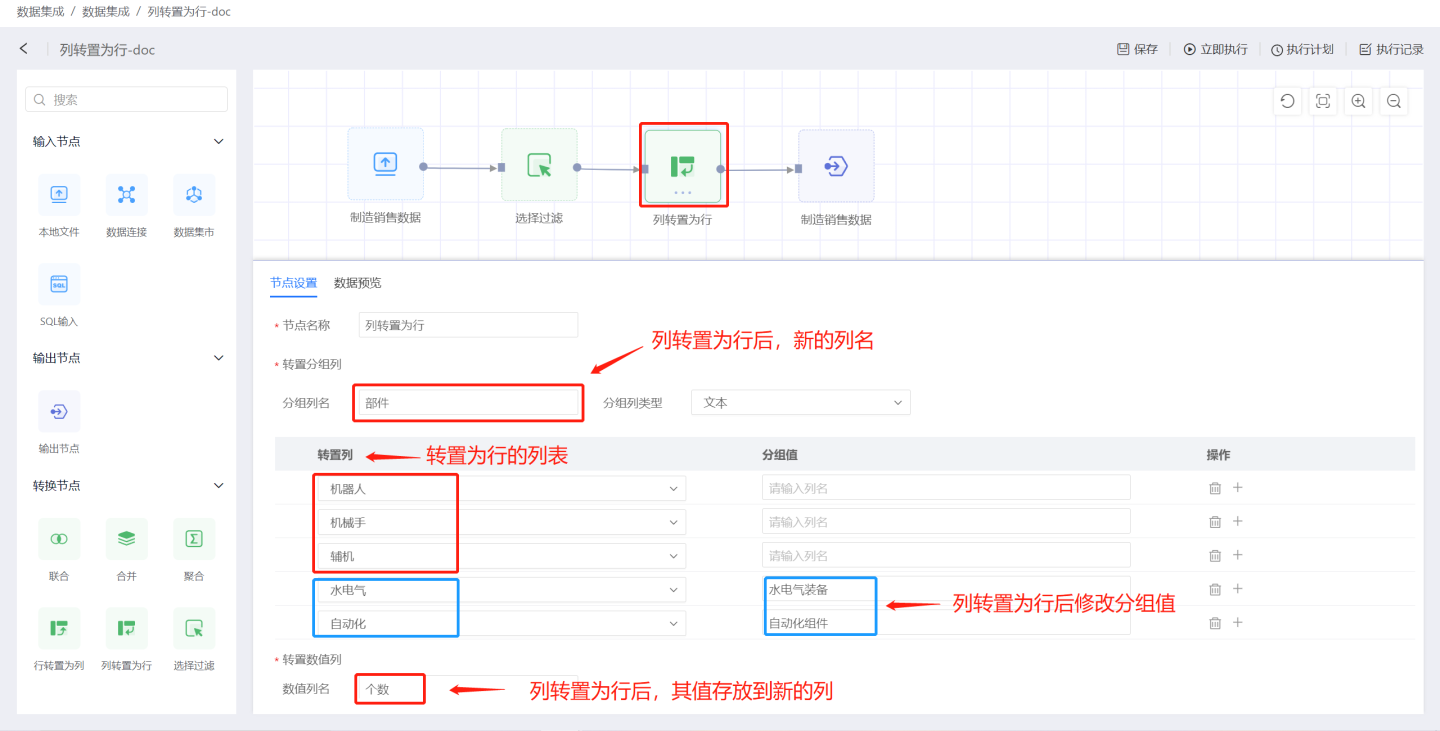 The output result is shown in the figure. After transposition, the columns
The output result is shown in the figure. After transposition, the columns 机器人,机械手,辅机,水电气,自动化are transposed into rows and stored in the部件column, and the values of the columns机器人,机械手,辅机,水电气,自动化are stored in the个数column.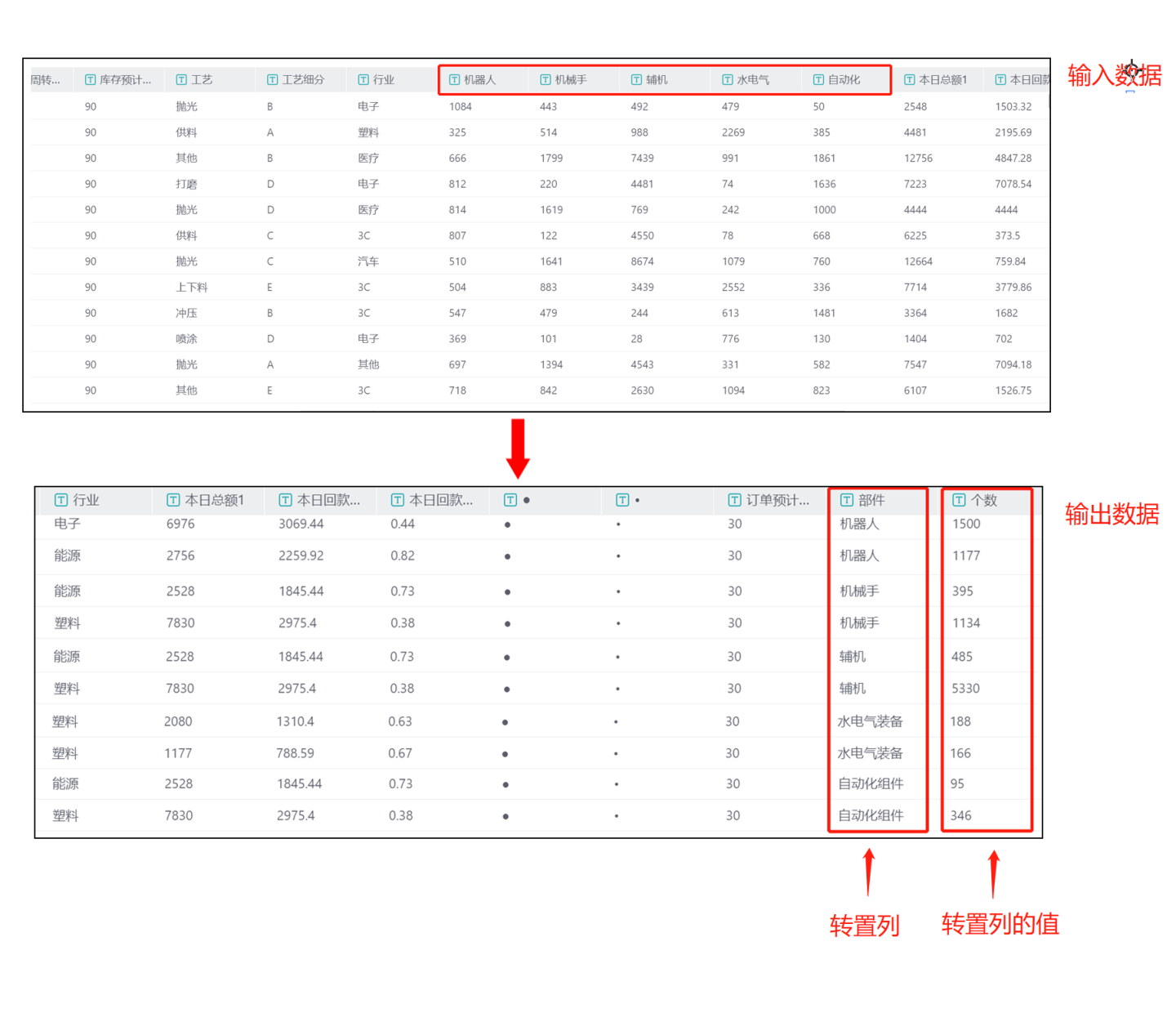
Project Execution
After all data nodes in the data integration project are created, the project can be executed. Each project supports two triggering methods: immediate execution and execution plan.
Immediate Execution
Click Execute Now and the project will be immediately added to the execution queue for processing, with the button changing to Stop Execution.
Tip
Depending on the queue status of the task execution, clicking Execute Now may result in the project being in either the Queuing or Executing state. Queuing: For projects that are Queuing, click Stop Execution to cancel this execution. Executing: For projects that are Executing, the operation button is disabled and cannot be canceled; you can only wait for this execution to complete.
Execution Plan
Click the execution plan in the upper right corner to enter the execution plan settings page, where you can set the basic information, scheduling information, and alarm information for the plan.
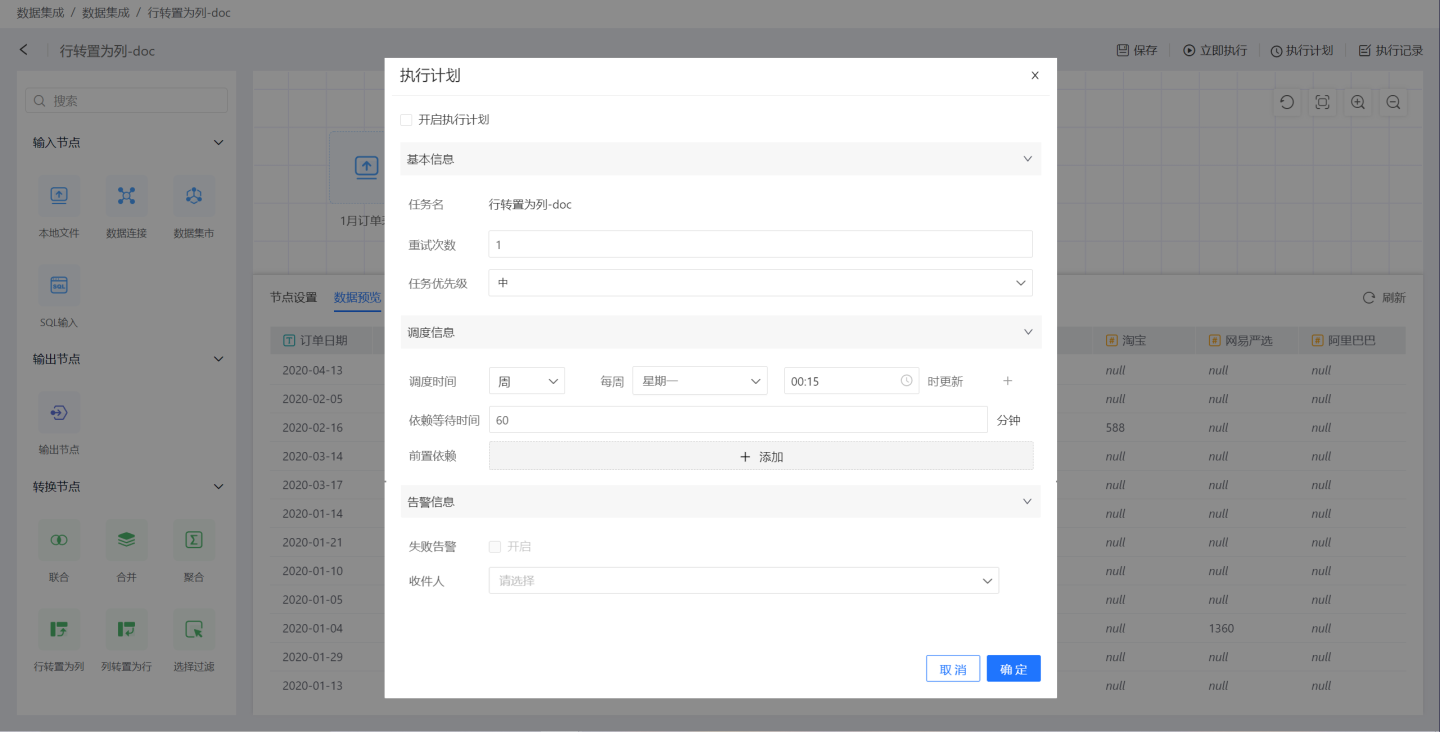
- Basic Information: Set the number of retries upon execution and the priority of the task. Task priority is divided into high, medium, and low levels. High-priority tasks are processed first.
- Scheduling Information:
- Set the scheduling time for the task, with the option to set multiple scheduling times. Supports setting execution plans by hour, day, week, and month.
- Hour: Can set the minute of each hour for updates.
- Day: Can set a specific time of day for updates.
- Week: Can set a specific time of day for updates on certain days of the week, with multiple selections allowed.
- Month: Can set a specific time of day for updates on certain days of the month, with multiple selections allowed.
- Custom: Can set the update time points on your own.
- Set the pre-dependencies of the task, with the option to set multiple pre-dependency tasks.
- Set the dependency waiting time.
- Set the scheduling time for the task, with the option to set multiple scheduling times. Supports setting execution plans by hour, day, week, and month.
- Alert Information: Enable failure alerts. When a task fails to execute, an email notification will be sent to the recipient.
Execution Records
Click on the Execution Records in the upper right corner of the project to view all execution records of the project.
Daily Operations of Projects
Data integration projects support operations such as creating, editing, immediate execution, copying, deleting, filtering, and searching. Immediate execution refers to the Immediate Execution feature of the project, which will not be expanded upon here. 
New Project
Click the New Project in the upper right corner, a new project operation box will pop up, enter the project name in the pop-up window, and select the default output path for the project from the optional data connections in the Default Output Path drop-down box.
Please note:
Only PostgreSQL, Greenplum, Amazon Redshift, MySql, Dameng, Amazon Athena, and Hologres data connections are supported as output paths.
As an optional connection for dataset integration output paths, the owner must check the Support Data Integration Output option when creating the connection, otherwise the output table cannot be stored.
Edit Project
Click the edit button corresponding to the item in the Operation column, and in the pop-up edit box, you can modify the item's name and the default output path.
Delete Item
Click the Delete button in the Operation column corresponding to the item, a confirmation box will pop up, click OK to delete the item.
Filter Items
Project filtering supports classification by project execution status, with the dropdown menu for execution status including:
- All
- Success
- Failure
- Queued
- Cancelled
- Running
Supports searching for items containing keywords under specified filter conditions, for example, searching for failed projects containing the keyword "Dataset" among all projects.
FAQ
- Nodes in the canvas area with a red lightning bolt indicate a node execution error, and a red exclamation mark indicates a configuration error. Please check and modify the node configuration.
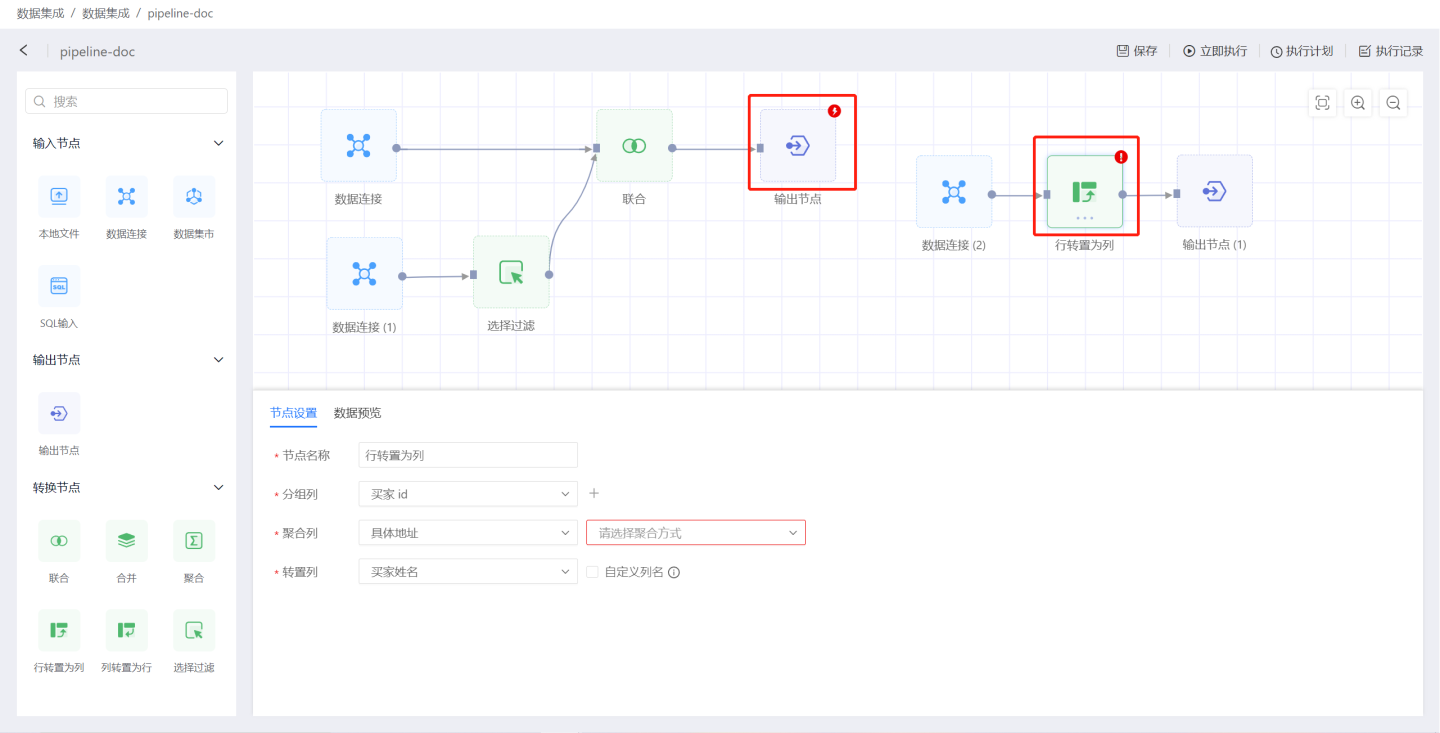
- The data processing flow for the output node is:
Pre-load SQL -> Schema Validation -> Table Operations -> Update Method -> Post-load SQL. - If a node fails to execute in a project, the entire project stops execution.
- When the input node data extraction is empty, subsequent steps do not execute.