AI Assistant
HENGSHI SENSE provides an AI assistant in the Go Analysis feature, allowing users to obtain relevant data and charts through question and answer. Before use, relevant configurations need to be made.
As shown in the image below, the system administrator needs to configure it on the Settings -> Feature Configuration -> AI Assistant page.
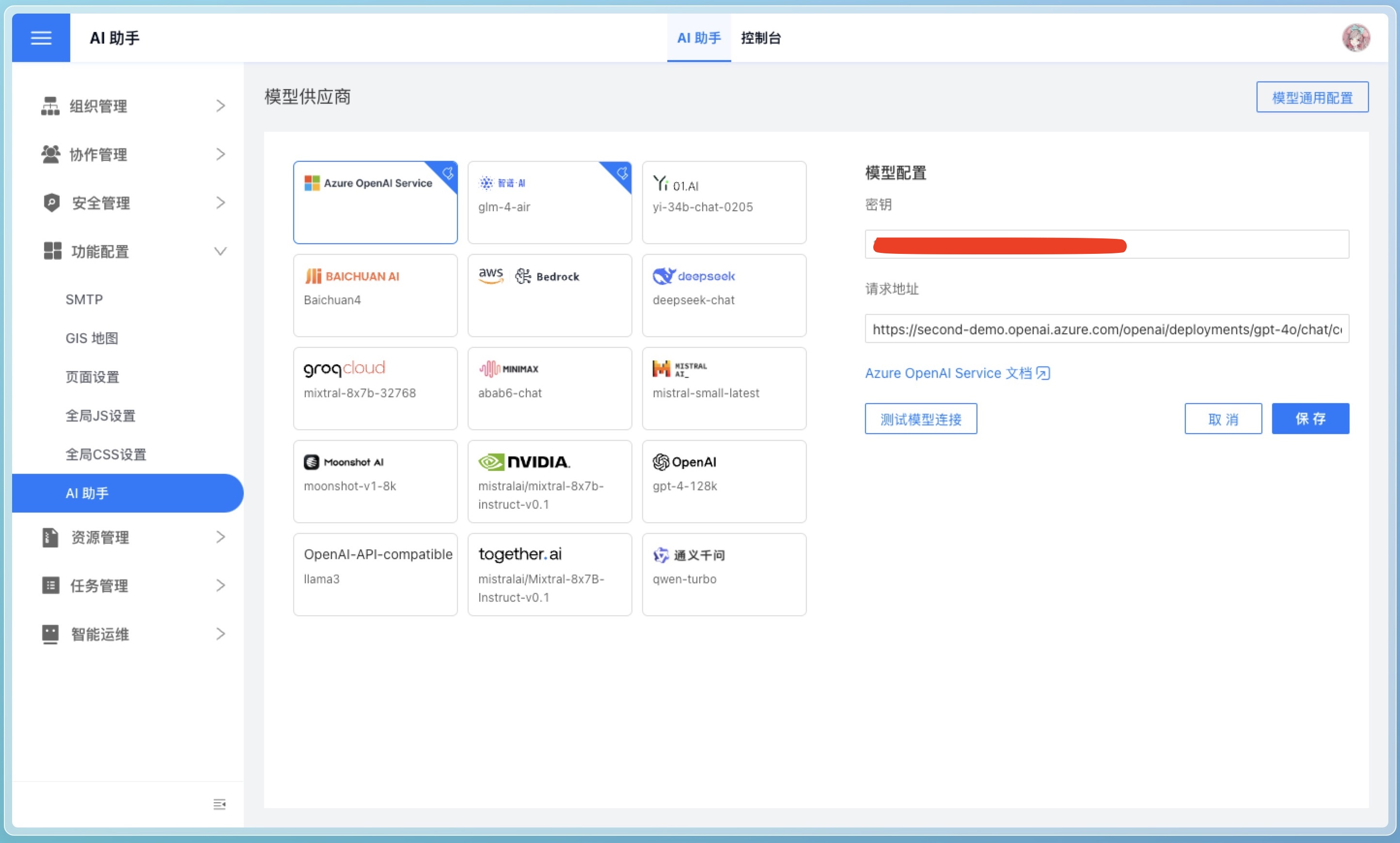
Model Providers
HENGSHI SENSE does not provide AI assistant models; users need to apply for them from model providers themselves. We recommend using Azure OpenAI Service and Zhipu AI.
Currently, the AI assistant supports the following model providers:
Note
The API Key from the model provider needs to be applied for by the user and kept securely.
Other Providers
On the page, you can also see that we support the following model providers, but we currently cannot guarantee the effectiveness of these models:
- 01AI
- Baichuan AI
- Bedrock
- DeepSeek
- Groq Cloud
- MiniMax
- MistralAI
- MoonShot AI
- Nvidia
- OpenAI
- TogetherAI
- Tongyi Qianwen
Note
The effectiveness of large models is influenced by the model provider, and HENGSHI SENSE cannot guarantee the effectiveness of all models. If you find the effect unsatisfactory, please contact support@hengshi.com or the model provider in time.
OpenAI-API-Compatible
If you need to use a model outside the above list, please select the OpenAI-API-Compatible option, as long as the model is compatible with the OpenAI API format.
Taking Doubao AI as an example, the configuration can be as follows:
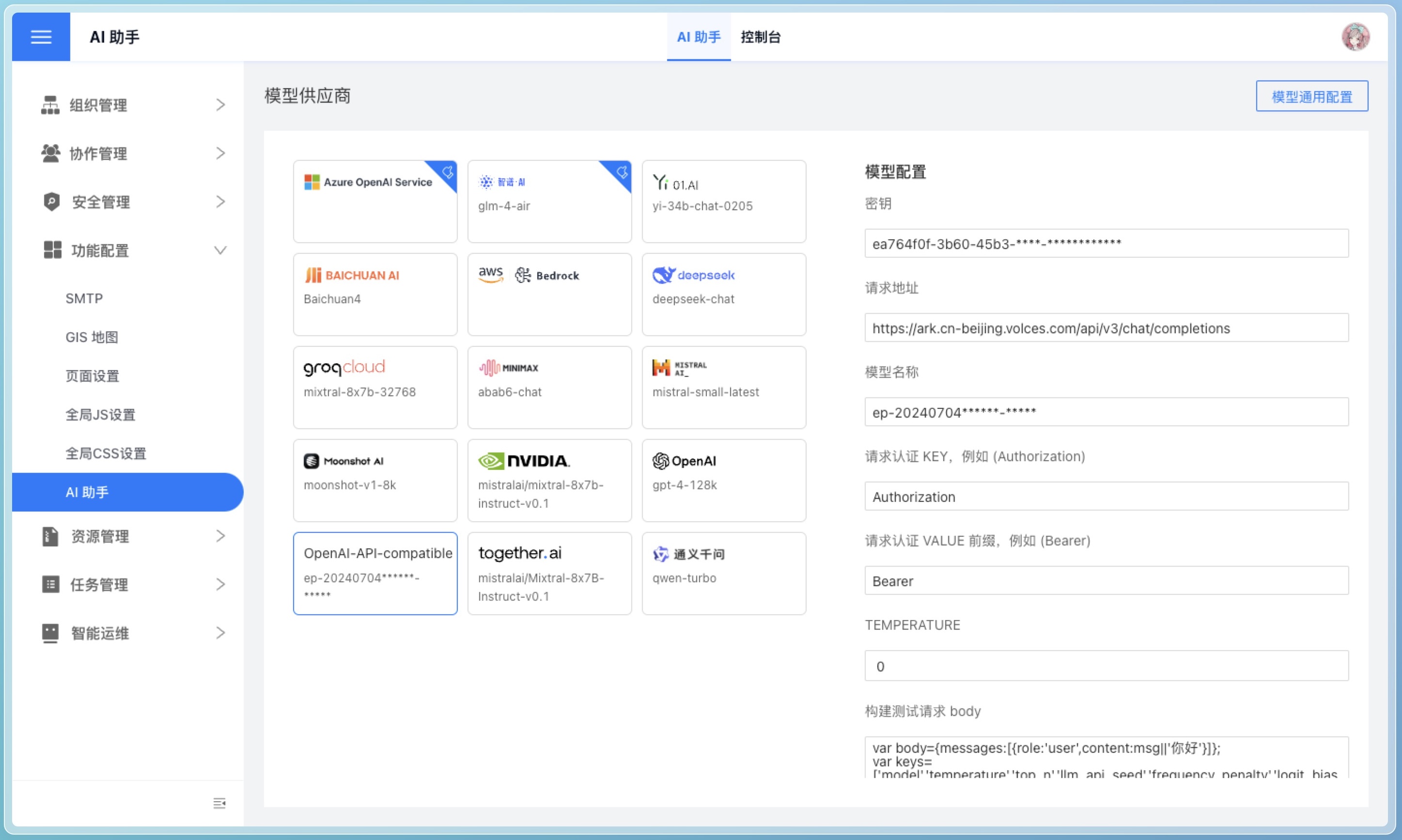
Test Model Connection
After configuring the model's API Key, click the Test Model Connection button to test whether the model connection is normal. As shown in the image below, if the connection is normal, the return content of the model interface will be displayed.

Note
This test is only sent by the frontend and may encounter cross-domain issues that cause the request to fail, but it will not affect the use of the model.
General Model Configuration
The following configuration items are system-level configurations for the AI assistant and are not differentiated by model providers.
LLM_ANALYZE_RAW_DATA
In the page configuration, it is Allow Model to Analyze Raw Data. The function is to set whether the AI assistant analyzes the raw input data. If your data is sensitive, you can turn off this configuration.
LLM_ANALYZE_RAW_DATA_LIMIT
In the page configuration, it is Number of Raw Data Rows Allowed to be Analyzed. The function is to set the limit on the number of raw data rows to be analyzed. Set according to the processing capabilities of the model provider, token limits, and specific needs.
LLM_ENABLE_SEED
In the page configuration, it is Use Seed Parameter. The function is to control whether to enable a random seed when generating replies to bring diversity to the results.
LLM_API_SEED
In the page configuration, it is Seed Parameter. The function is to use a random seed number when generating replies. Used in conjunction with LLM_ENABLE_SEED, it can be randomly specified by the user or kept as default.
LLM_SUGGEST_QUESTION_LOCALLY
In the page configuration, it is Do Not Use Model to Generate Recommended Questions. The function is to specify whether to use a large model when generating recommended questions.
- true: Generate locally by rules
- false: Generate by large model
LLM_SELECT_ALL_FIELDS_THRESHOLD
In the page configuration, it is Allow Model to Analyze Metadata (Threshold). The function is to set the threshold for selecting all fields. This parameter only works when LLM_SELECT_FIELDS_SHORTCUT is true, set it as needed.
LLM_SELECT_FIELDS_SHORTCUT
This parameter sets whether to not select fields when there are fewer fields, directly selecting all fields to participate in generating HQL. Used in conjunction with LLM_SELECT_ALL_FIELDS_THRESHOLD, determine this configuration based on specific operation scenarios. Generally, it does not need to be set to true. It can be turned off when speed is particularly sensitive or when you want to skip the field selection step. However, not selecting fields will affect the correctness of the final data query.
LLM_API_SLEEP_INTERVAL
In the page configuration, it is API Call Interval (Seconds). The function is to set the sleep interval between API requests in seconds. Set according to the request frequency requirements. It can be considered to set for large model APIs that need to limit the frequency.
HISTORY_LIMIT
In the page configuration, it is Number of Context Items in Continuous Dialogue. The function is the number of historical dialogue items carried when interacting with the large model.
LLM_ENABLE_DRIVER
In the page configuration, it is Use Model to Infer Intent. The function is whether to enable AI to judge prohibited questions and optimize questions based on context. The context range is determined by HISTORY_LIMIT. Generally, it needs to be enabled when there is a need for context reference and prohibited questions.
MAX_ITERATIONS
In the page configuration, it is Model Inference Iteration Limit. The function is the maximum number of iterations, used to control the number of times the large model fails to loop.
LLM_API_REQUIRE_JSON_RESP
Determines whether the API response format must be JSON; this configuration item is only supported by OpenAI and generally does not need to be changed.
LLM_HQL_USE_MULTI_STEPS
Whether to optimize trends, the degree of adherence to instructions for year-over-year and month-over-month types of questions through multiple steps, set as needed, multiple steps will be relatively slower.
VECTOR_SEARCH_FIELD_VALUE_NUM_LIMIT
The upper limit of the number of distinct values for token search dataset fields, parts with too many distinct value matches will not be extracted, set as needed.
CHAT_BEGIN_WITH_SUGGEST_QUESTION
Whether to provide users with a few recommended questions after jumping to Go Analysis. Turn on as needed.
CHAT_END_WITH_SUGGEST_QUESTION
Whether to provide users with a few recommended questions after each question round. Turn off to save some time.
Vector Database Configuration
ENABLE_VECTOR
Enable vector search function. The AI assistant selects the most relevant examples to the question through the large model API. After enabling vector search, the AI assistant will synthesize the results of the large model API and vector search.
VECTOR_MODEL
Vectorization model, set based on whether vector search capability is needed. Needs to be used in conjunction with VECTOR_ENDPOINT. The models included in the system's vector service are intfloat/multilingual-e5-base. This model does not need to be downloaded. If other models are needed, currently, models on huggingface are supported. Note that the vector service must be able to ensure connectivity to the huggingface official website, otherwise, the model download will fail.
VECTOR_ENDPOINT
Vectorization API address, set based on whether vector search capability is needed. After installing the relevant vector database services, it defaults to the system's vector service.
VECTOR_SEARCH_RELATIVE_FUNCTIONS
Whether to search for function descriptions related to the question. After opening, function descriptions related to the question will be searched, correspondingly, the prompt will become larger. This switch only takes effect when ENABLE_VECTOR is enabled.
For detailed vector database configuration, see: AI Configuration