Batch Synchronization
When users need to migrate data from one database to one or more target databases, they can achieve this by creating a project in bulk synchronization.
Bulk Synchronization Main Functions:
- Synchronize one or more tables to the specified connection.
- Set data synchronization policies during the data synchronization process.
- Support manual and scheduled data synchronization.
- Can execute multiple projects to complete data synchronization tasks.
Create Data Synchronization Process
The process of batch synchronizing data is as follows: 
- Create a batch synchronization project.
- Configure the source data connection and target data connection.
- Configure the synchronization strategy.
- Set the project execution plan.
Batch Synchronization Detailed Guide
Create Batch Synchronization Project
In the Data Integration -> Batch Sync page, click the New Project in the upper right corner to create a batch sync project. 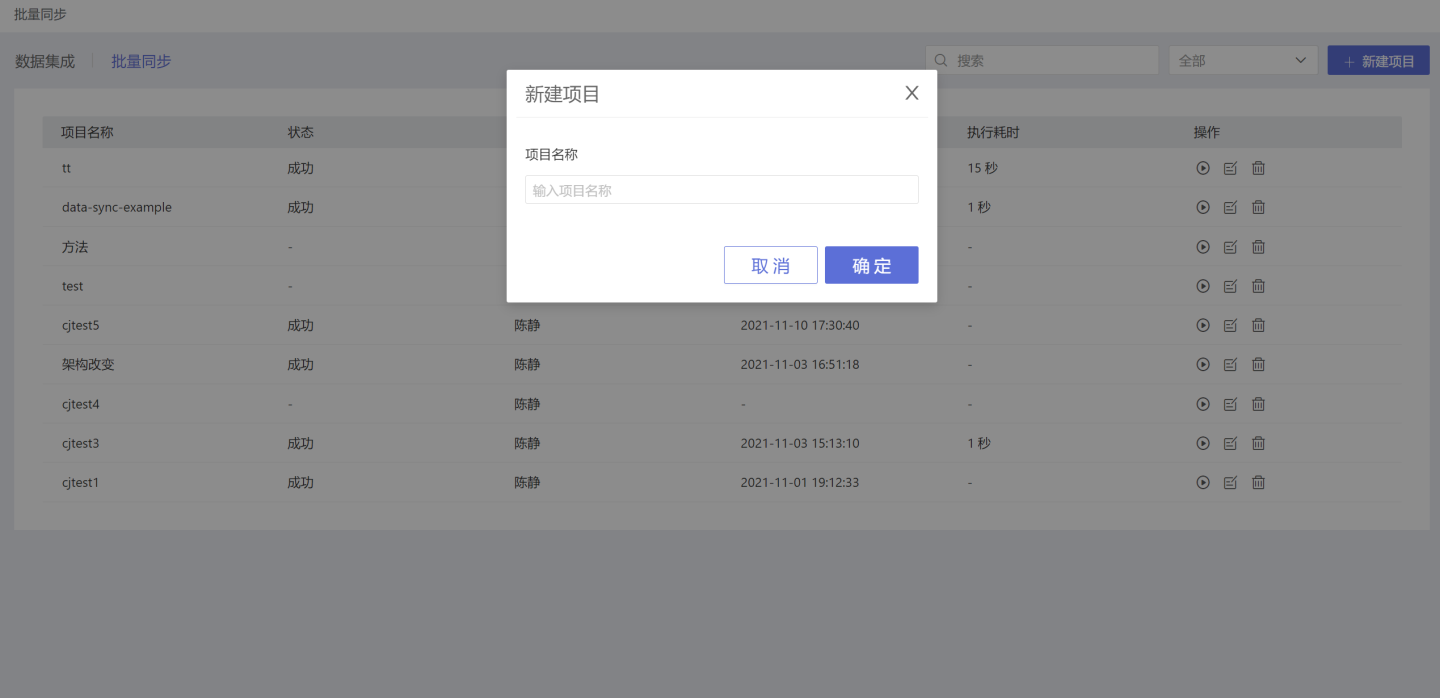
Configure Data Source
Set the source data connection (the data connection to be migrated) and the target data connection (the data connection where the data will be migrated to) on the batch sync project page. The target data connection needs to be created with the Support Data Integration Output Function checked. If you are not familiar with the concept of data connections, please read Data Connection first. 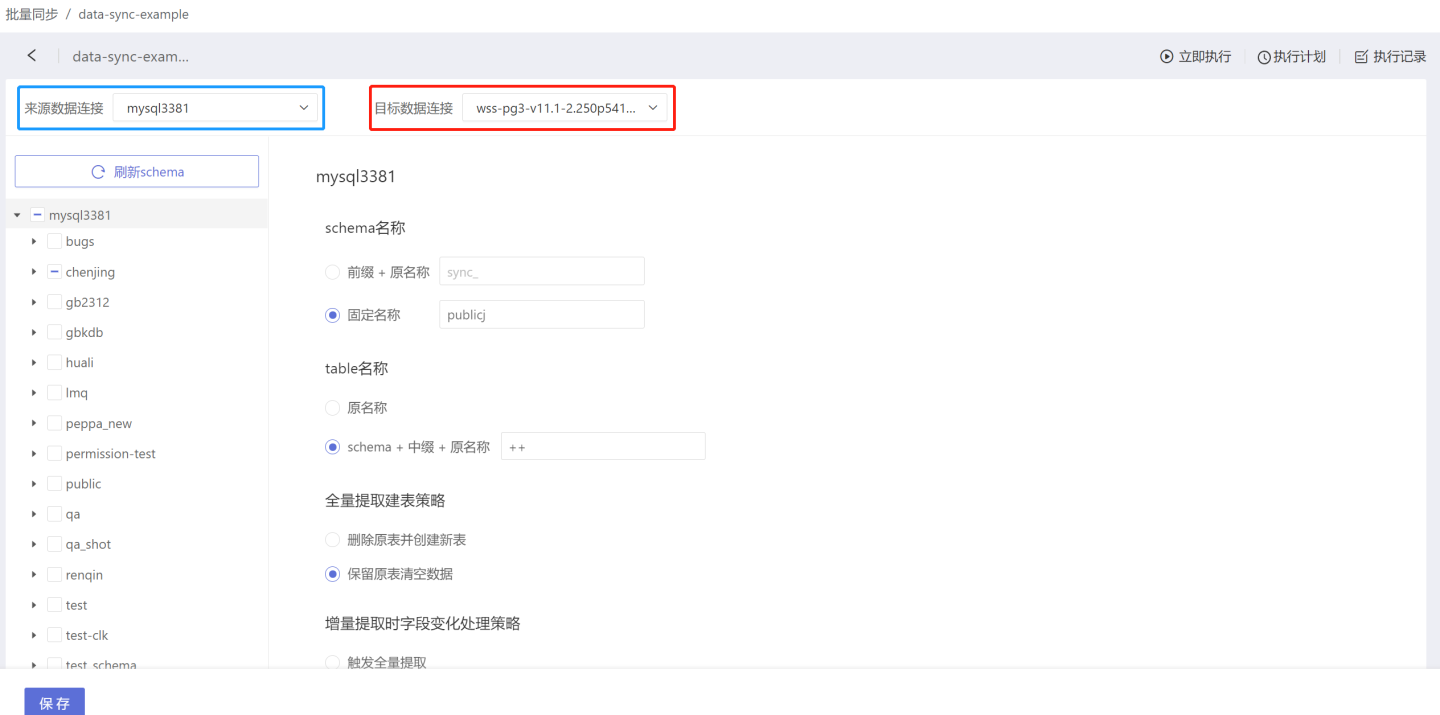
Configure Data Synchronization Strategy
Batch synchronization supports setting synchronization strategies for connections, schemas, and tables separately.
Configure Connection Synchronization Strategy
The connection synchronization policy applies to all directories and tables under the directories within the connection. The connection synchronization policy includes:
- Schema Name: Set the schema name where the table is located after data synchronization.
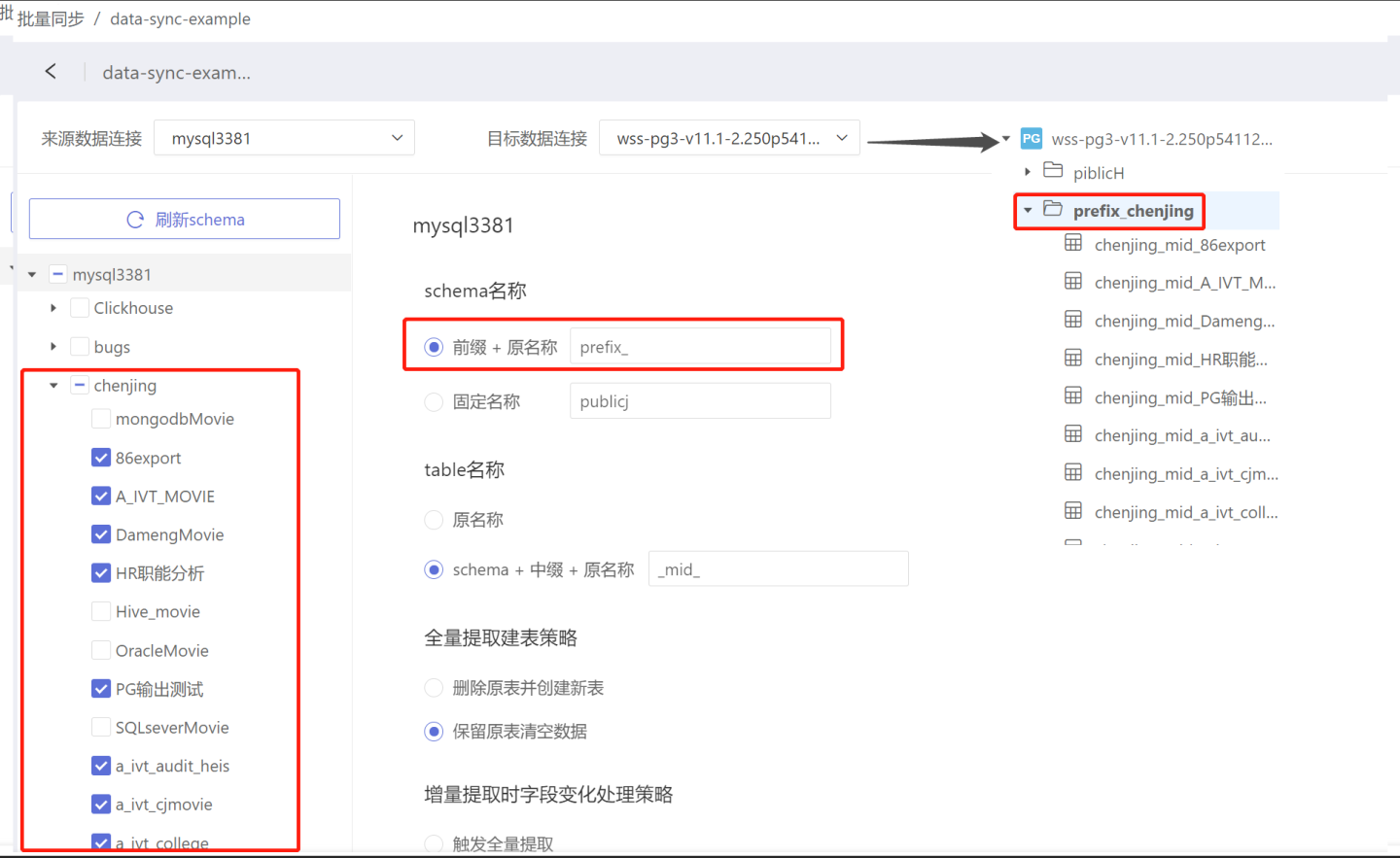
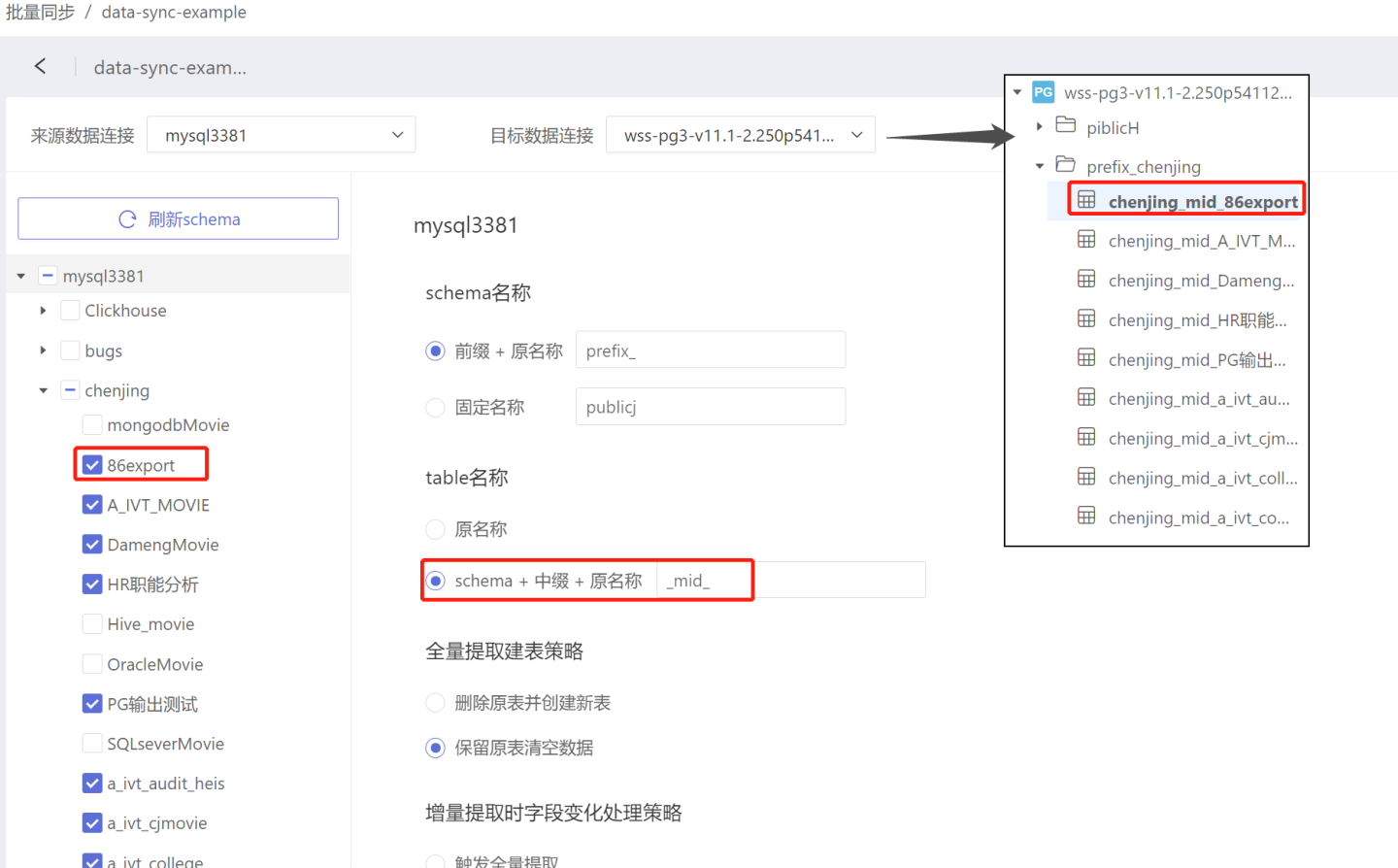
- Prefix + Original Name: The directory name where the table is stored after data synchronization is "Prefix" + "Original Name". As shown in the figure, when the prefix is set to "prefix_", the table 86export before synchronization is stored in the directory chenjing, and after synchronization, the table 86export is stored in the directory named "prefix_chenjing".
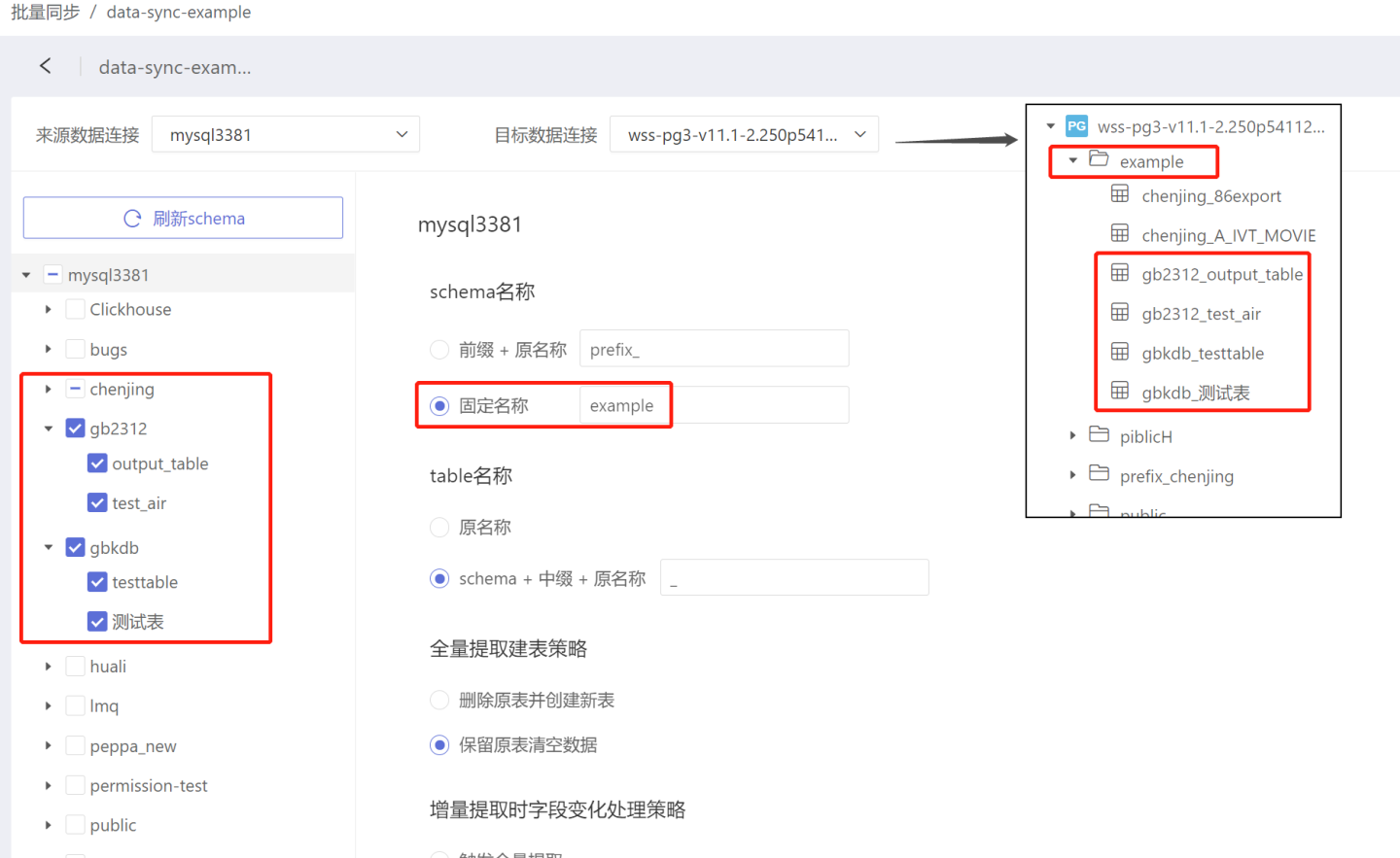
- Fixed Name: All tables after data synchronization are stored in the same directory. As shown in the figure, the tables in the directories chenjing, gb1312, and gbkdb are all stored in example.
- Prefix + Original Name: The directory name where the table is stored after data synchronization is "Prefix" + "Original Name". As shown in the figure, when the prefix is set to "prefix_", the table 86export before synchronization is stored in the directory chenjing, and after synchronization, the table 86export is stored in the directory named "prefix_chenjing".
- Table Name: Naming rules for tables after synchronization.
- Original Name: The table name remains unchanged after data synchronization.
- Schema + Infix + Original Name: After data synchronization, the table name becomes "Schema" + "Infix" + "Original Name". As shown in the figure, when the infix is set to "_mid_", the table 86export is renamed to chenjing_mid_86export after synchronization.
- Full Extraction Table Creation Strategy: When full extraction is selected, the following two methods are supported.
- Delete Original Table and Create New Table: Delete the original table and create a new one, then synchronize the data.
- Retain Original Table and Clear Data: The original table is not deleted, only the data is cleared, and then the data is synchronized.
- Field Change Handling Strategy During Incremental Extraction: When the table selects the incremental extraction method, if the table's fields change, the following two handling strategies can be chosen.
- Trigger Full Extraction: The table is extracted in full mode.
- Ignore Changes: Ignore the changed fields, and the table is extracted in the original incremental mode.
- Ignore Subsequent New Tables: After checking this option, new tables added in the source data connection will not be synchronized.
- Add Additional Update Time Column for Each Table After selecting this option, in addition to the original data columns, an additional hs_sync_time column will be added during data synchronization, recording the timestamp when each row of data is synchronized.
Configure Schema Synchronization Strategy
Configure the schema synchronization strategy to take effect only for the current schema. Currently, only the configuration of "ignoring subsequent new tables" is supported.
Configure Table Synchronization Strategy
Table synchronization strategy only takes effect for the current table configuration. The table synchronization strategy includes:
- Extraction Methods
- Full Extraction: Full data extraction is performed each time.
- Incremental Extraction: Full data extraction is performed during the first synchronization, and subsequent extractions are based on the incremental key or primary key, performing incremental extraction on the basis of the incremental key and primary key.
- Incremental Key: Must be of numeric or date/time type.
- Key Field: Set the key field to be used as the primary key and distribution key. The key field has two functions.
- Used as the primary key during incremental updates, must be of numeric or date/time type.
- Used as the primary key and distribution key when creating the table. If table properties are set, the key field settings will not take effect.
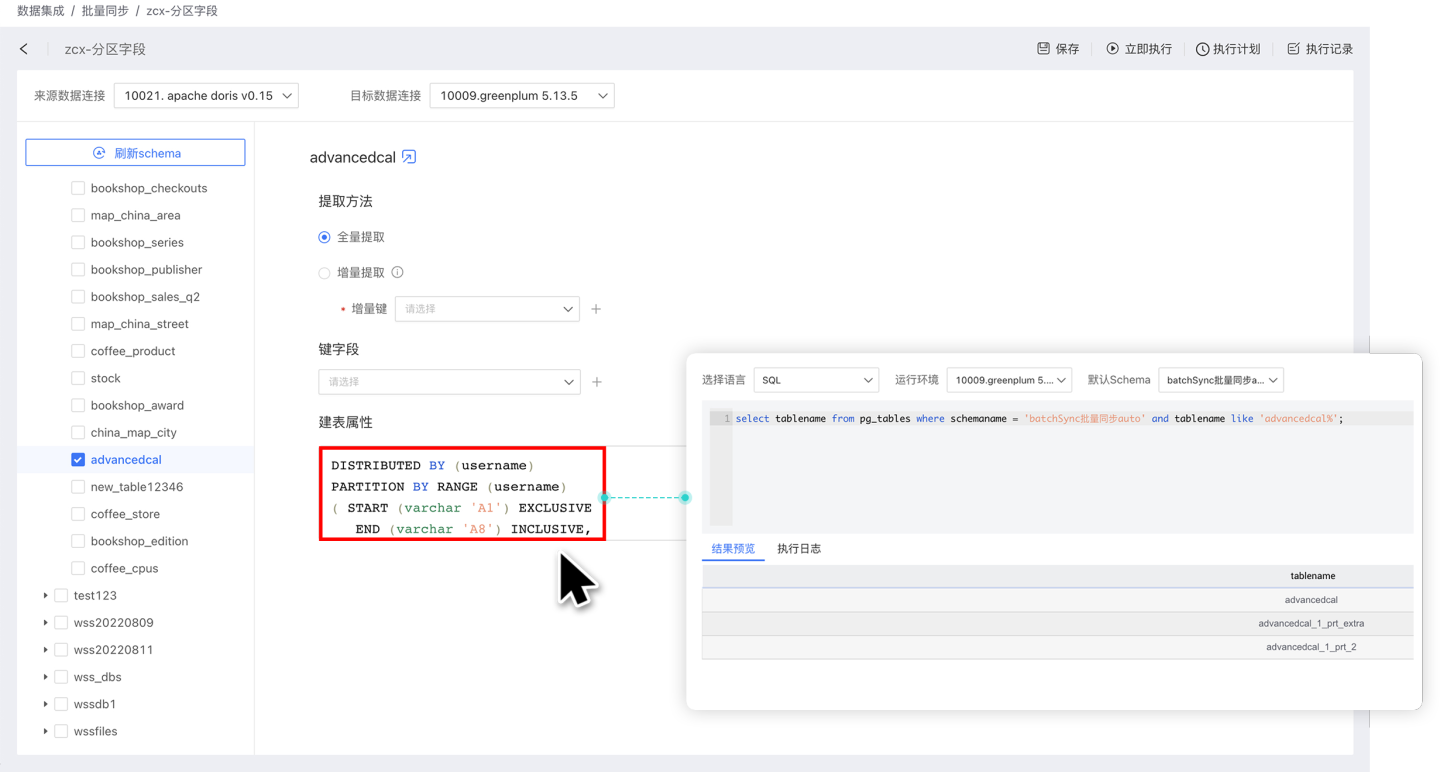
- Table Properties: Customize partition fields and index fields during the data synchronization table creation process to distribute data storage. Table properties only take effect during the first table creation. Currently, data sources that support table properties include Greenplum, Apache Doris, StarRocks, and ClickHouse.
Data Batch Synchronization
When the amount of synchronized data is large, the data import time may exceed the query time of the source database, causing data synchronization to fail. In this case, you can set the maximum limit for extracting data at one time by configuring the ETL_SRC_MYSQL_PAGE_SIZE option. When the limit is exceeded, data is processed in batches. Batch synchronization of data is applicable to incremental extraction and full extraction scenarios with key field settings. Currently, only MySQL data sources support batch synchronization.
Tip
Please contact the technical staff to configure ETL_SRC_MYSQL_PAGE_SIZE.
Perform Synchronization Operation
Data synchronization can be divided into immediate execution and data synchronization through an execution plan.
Immediate Execution: Manually initiate the data synchronization operation by clicking the Execute Now button to start synchronization.
Execution Plan: Set up a synchronization schedule, where the system triggers the data synchronization operation. Click the execution plan in the upper right corner to enter the execution plan setting page, where you can set the basic information, scheduling information, and alert information of the plan.
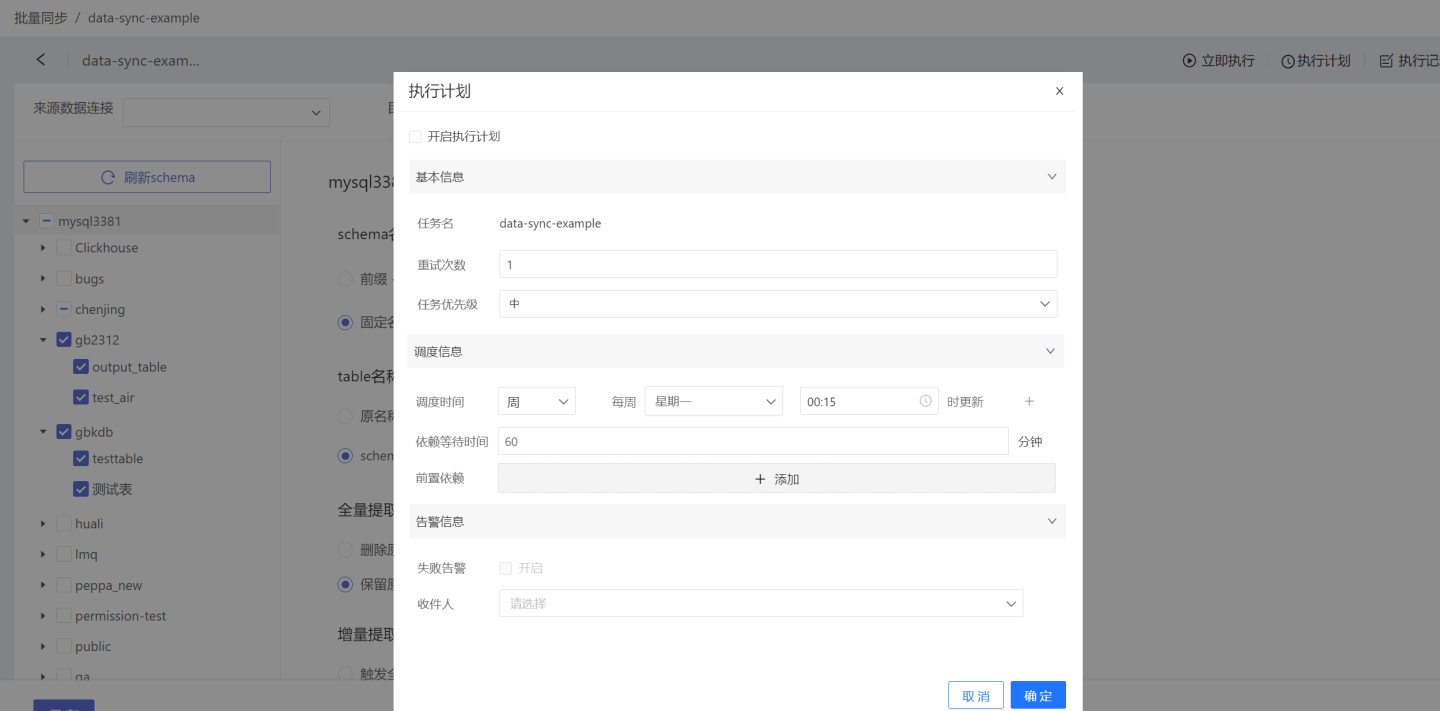
- Basic Information: Set the number of retries during execution and the priority of the task. Task priority is divided into high, medium, and low levels. High-priority tasks are processed first.
- Scheduling Information:
- Set the scheduling time for the task, which can include multiple scheduling times. Support for setting execution plans by hour, day, week, and month.
- Hour: Set the specific minute of each hour for updates.
- Day: Set the specific time of day for updates.
- Week: Set the specific time of day for updates on selected days of the week.
- Month: Set the specific time of day for updates on selected days of the month.
- Custom: Set the update time points according to your own needs.
- Set the pre-dependencies for the task, which can include multiple pre-dependent tasks.
- Set the dependency wait time.
- Set the scheduling time for the task, which can include multiple scheduling times. Support for setting execution plans by hour, day, week, and month.
- Alert Information: Enable failure alerts. When the task execution fails, an email notification will be sent to the recipient.
Tip
Each data synchronization execution, whether successful or failed, will be recorded in the Execution Records.
FAQ
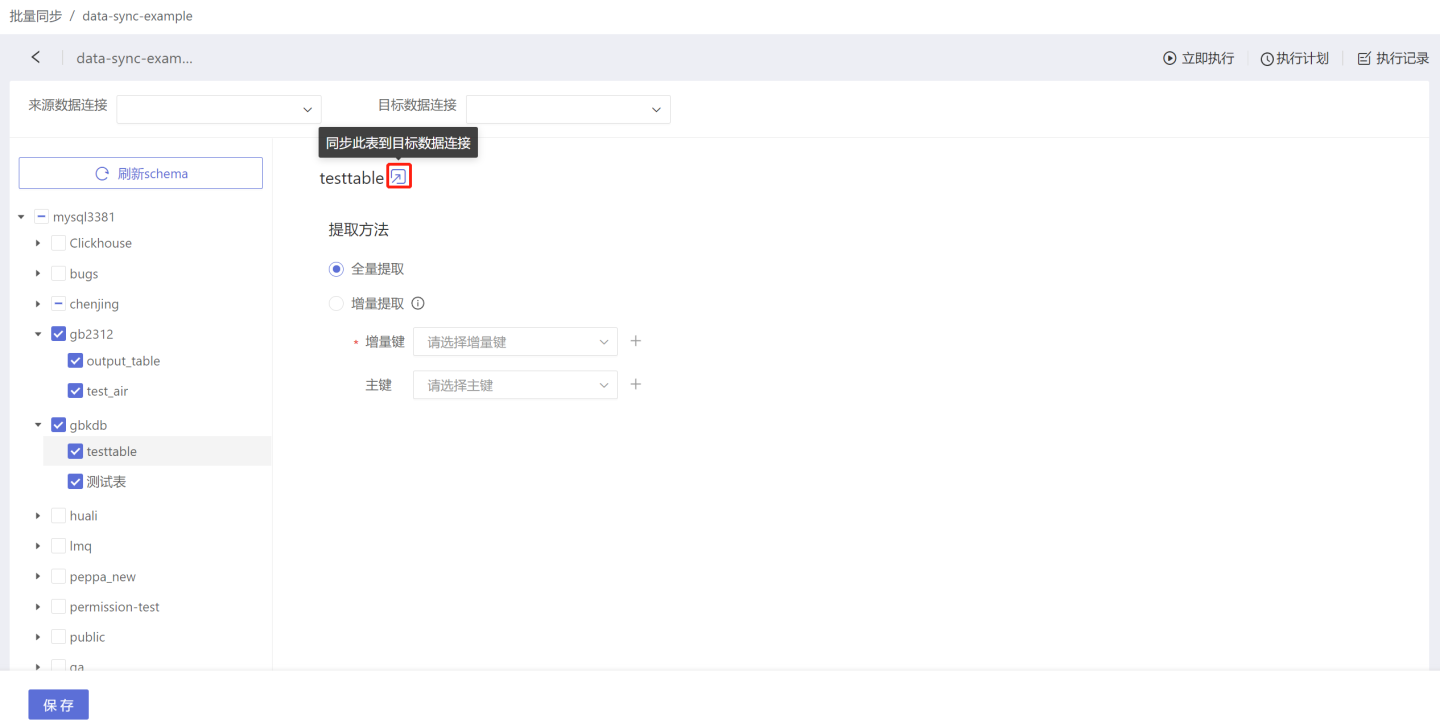
- Single Table Quick Sync Data integration supports single table quick sync. When performing a full extraction on a few tables, after setting the destination data connection, locate the corresponding table and click the icon to complete the table sync.