数据集成
数据集成提供 ETL(Extract-Transform-Load,抽取-转置-加载)功能,对不同来源的数据进行抽取、过滤、转换格式、添加计算列、关联、合并、聚合等处理后,输出到用户指定的数据源中,供后续探索分析用。
数据处理流程
数据集成项目数据处理流程大致分为三部分:连接数据、清洗和转换数据、输出数据。
数据集成页面如图所示,左侧红框区域是节点区域,所有节点通过拖拽的方式进入中间蓝框画布区。画布区内连接节点,完成节点间数据流传递,最终流向输出节点。点击画布中的节点可以对节点进行设置。画布右上方是项目执行按钮。 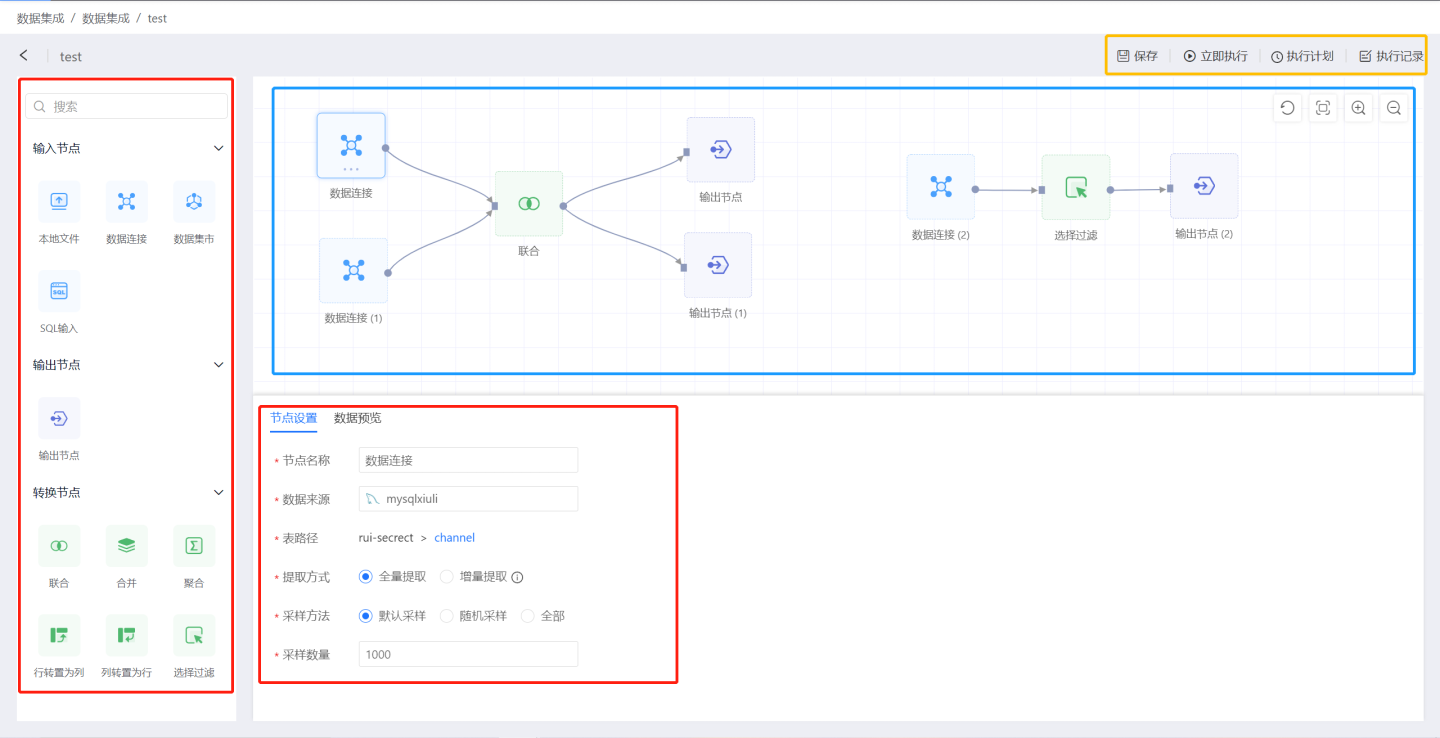
数据集成项目创建过程
下面讲述数据集成项目创建过程,可以按照下面的指导进行项目创建。
创建项目。 在数据集成页面点击右上角的
新建项目,弹出新建项目的操作框,在弹窗中输入项目名称,在默认输出路径中选择数据连接作为输出节点的默认输出路径。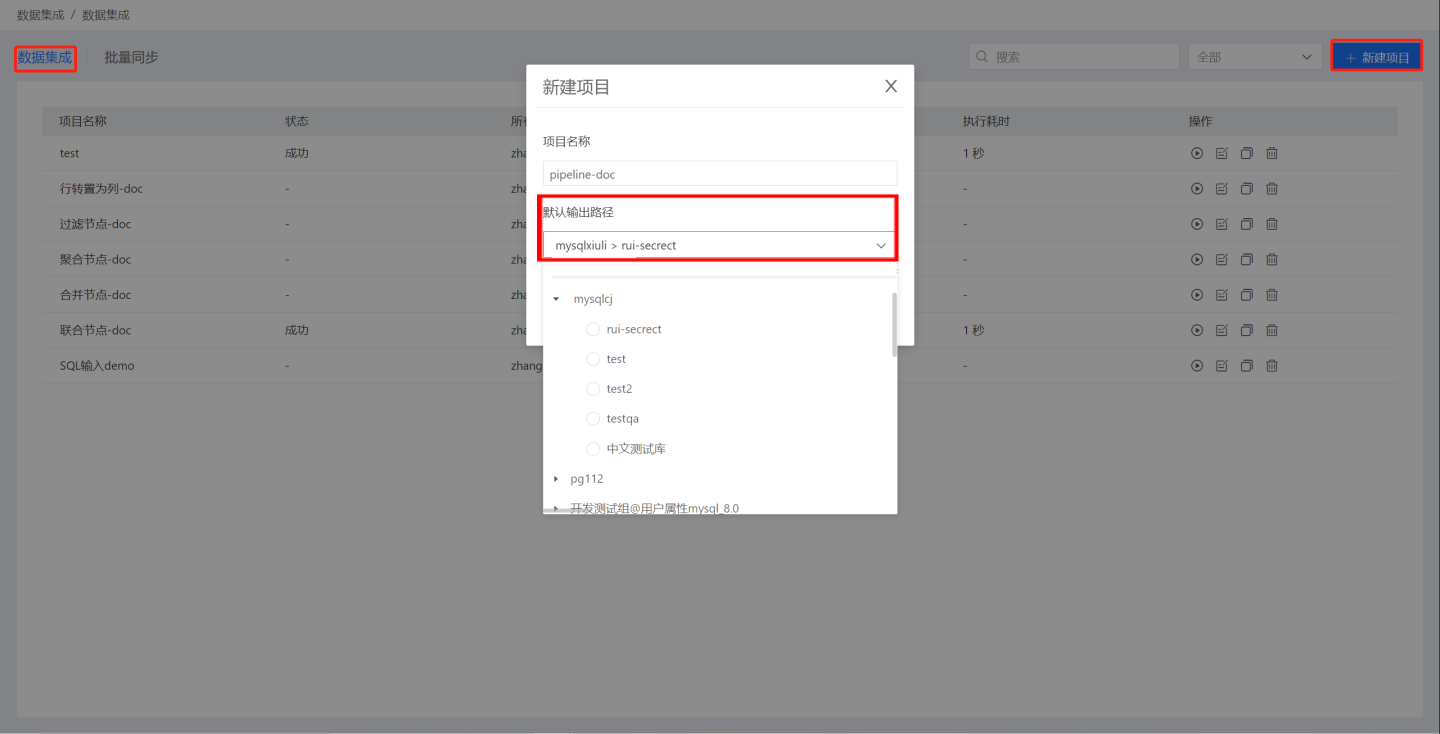
创建输入节点。 选择输入节点类型,拖入到画布中,选择数据来源。支持本地文件、数据连接、数据集市、SQL 输入四种输入节点。
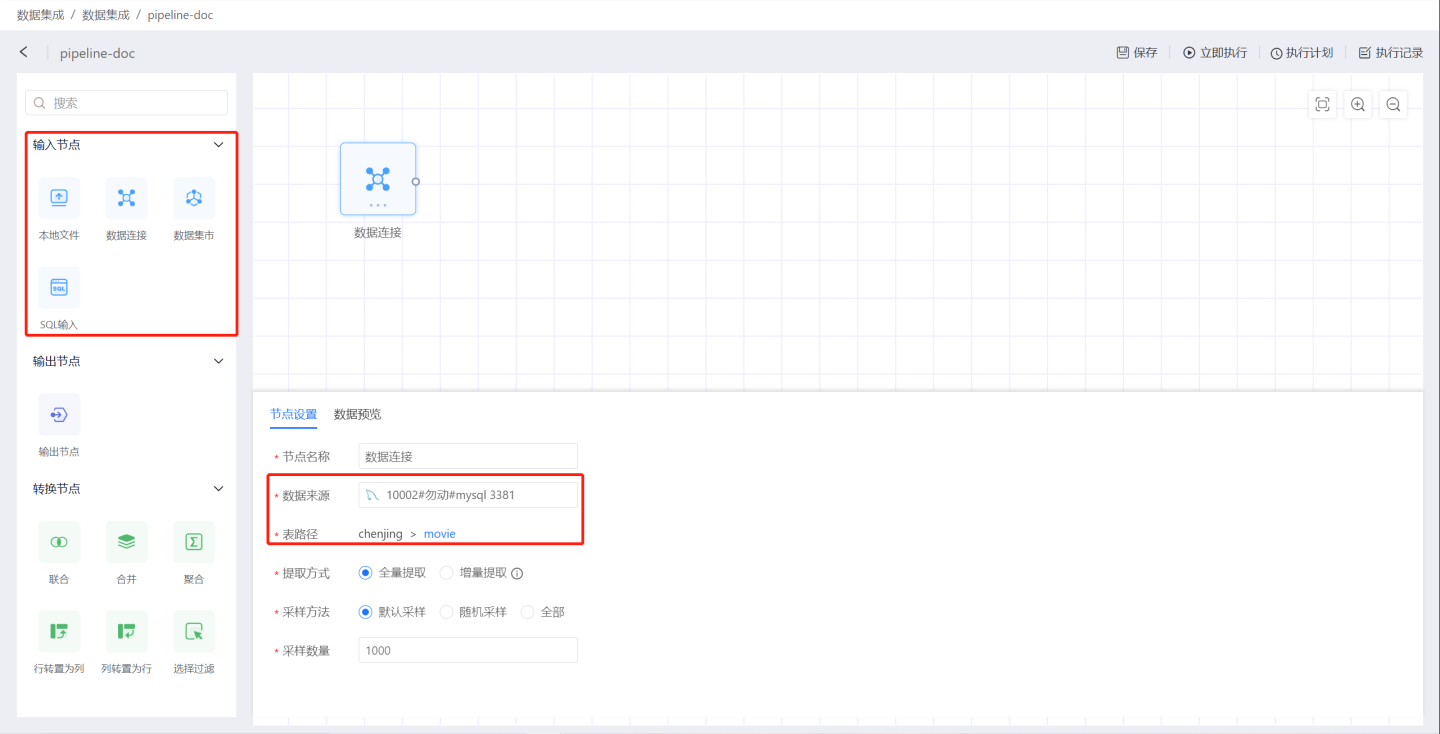 配置输入节点。设置节点名称、提取方式、采样方法,然后预览数据是否符合设置要求。示例中选择全量提取,默认采样方式,采取1000条数据。详细配置项说明请参见输入节点。
配置输入节点。设置节点名称、提取方式、采样方法,然后预览数据是否符合设置要求。示例中选择全量提取,默认采样方式,采取1000条数据。详细配置项说明请参见输入节点。添加转换节点。 选取转换节点,拖入画布中,连接上游数据源,对数据进行转换操作。支持联合、合并、 聚合、行转置为列、列转置为行、选择过滤等转换操作。
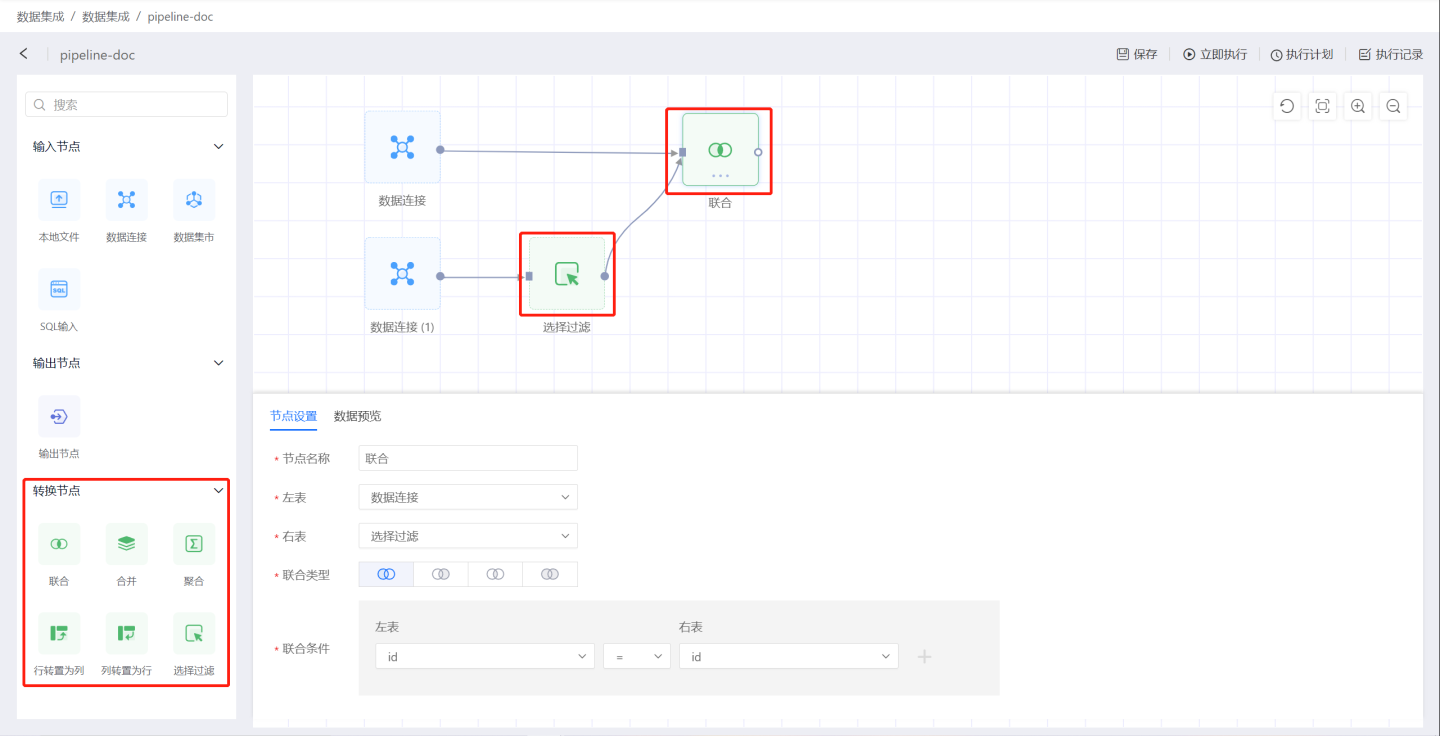
创建输出节点,存放数据。 拖入输出节点到画布中,并且与上游数据连接,设置数据输出存放的位置及表名。
 配置输出节点。设置验证 schema,表操作方式,更新方法,加载签 SQL,加载后 SQL。详细配置项说明请参见输出节点。
配置输出节点。设置验证 schema,表操作方式,更新方法,加载签 SQL,加载后 SQL。详细配置项说明请参见输出节点。按照上述步骤完成了一条数据处理流的搭建。点击输出节点的三点菜单执行,可以在查看数据处理结果。
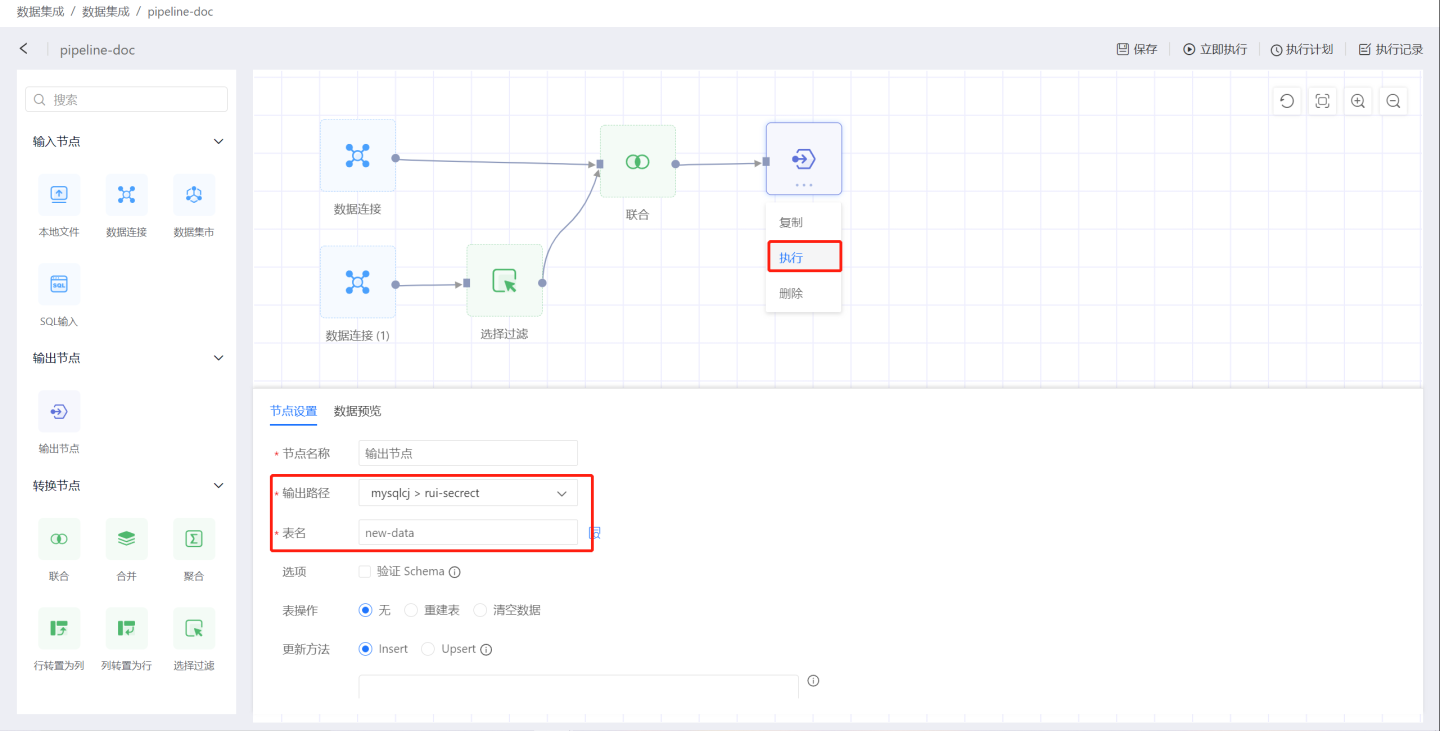
在项目中搭建其他数据处理流。
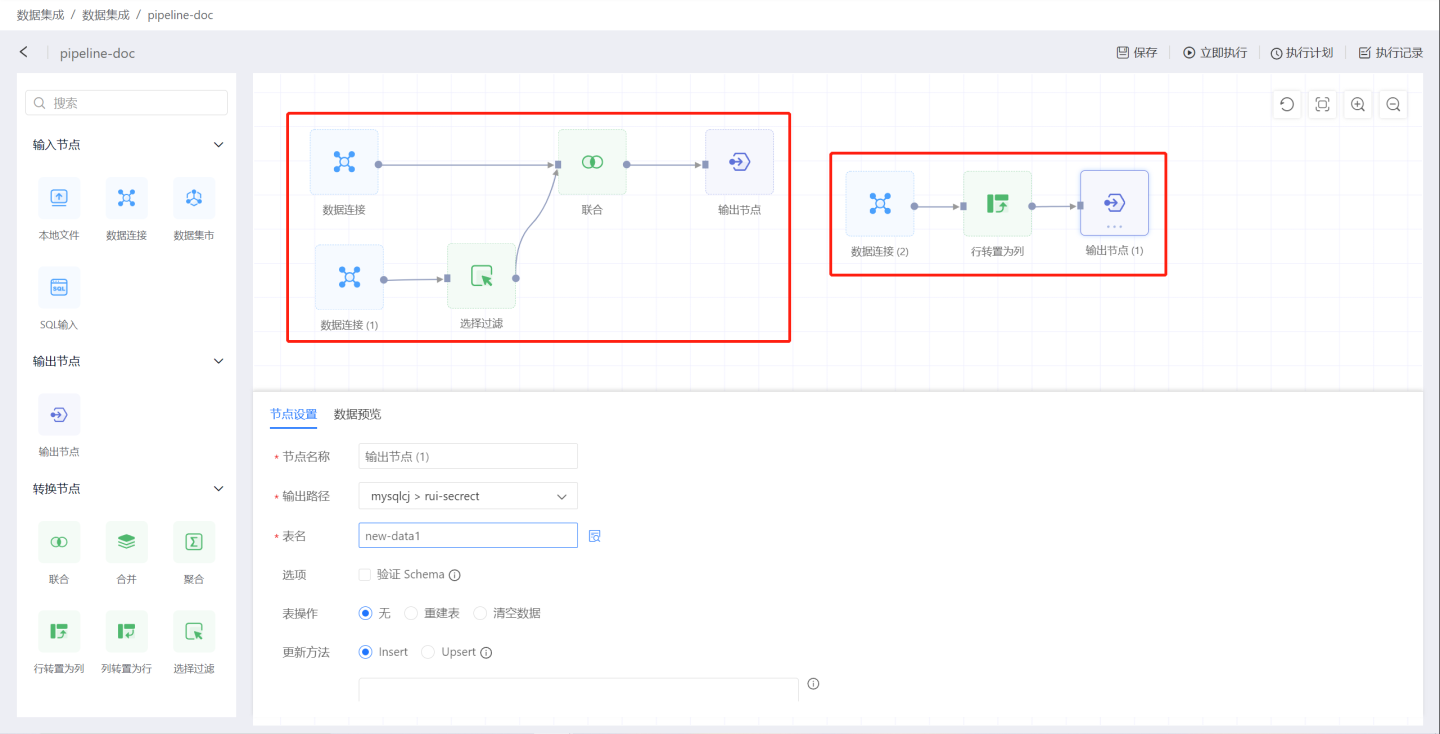
上述示例简单的展示了在数据集成中创建数据处理过程,下面详细介绍数据处理过程中的各节点的功能及配置。
输入节点
数据集成的数据来源是通过输入节点实现的,一个输入节点可以连接多个转换节点或输出节点。 下面详细介绍输入节点的功能和配置。
输入类型
输入节点支持四种类型:本地文件、数据连接、数据集市和 SQL 输入。
本地文件
添加本地文件为输入节点时,支持上传 csv、excel 两种格式的文件。
csv 格式的文件
上传 csv 格式的文件时,可以按照本地文件的格式,设置文件的分隔符、编码,按照需求设置表头、选择行列、设置行列反转等。
excel 格式的文件
上传 excel 格式的文件时,可以在多 sheet 的文件中选择需要的 sheet,再按照需求设置表头、选择行列、设置行列反转等。
数据连接
添加数据连接中的表为输入节点时,分为内置数据连接和用户数据连接两大类:
内置连接:即衡石系统内嵌的引擎数据连接。
用户连接:即用户自己创建的数据连接以及当前账户有权限访问的被授权数据连接,用户可以选择连接中的一个表作为输入节点。
提示
如果用户对表仅有查看名称权限,在预览数据时,添加按钮置灰,无法将其作为输入节点。
数据集市
可以选择数据集市中的数据集作为输入节点,将数据集的成果导出到输出源中,方便客户探索使用。
SQL 输入
SQL 输入节点是指使用 SQL 语言定义的输入节点的数据内容。 首先选择数据连接,然后使用 SQL 语言定义数据对象。
数据提取方式
数据导入分为全量提取和增量提取两种方式。
全量提取
全量提取每次会提取输入节点中全部的数据。
增量提取
增量提取需要选择增量字段,提取时只会提取增量字段值大于当前已导入数据中该增量字段最大值的数据。
提示
增量提取时,增量字段必须是数字或者时间类型,粒度从大到小,如:年>月>日或日期时间字段>唯一 id。 增量提取时数据预览只会显示大于输出表中增量字段最大值的数据。如果输入表中没有大于增量字段最大值的数据,则预览数据为空。
数据分批提取
当提取的数据量比较大时,数据导入时间可能超过了源数据库的查询时间,导致数据提取失败。此时可以通过配置项 ETL_SRC_MYSQL_PAGE_SIZE 设置一次提取数据的最大上限,当超过该上限时数据进行分批提取。目前只有 MySQL 数据源支持分批提取。
请联系技术人员配置 ETL_SRC_MYSQL_PAGE_SIZE。
数据采样
数据采样是一个调试功能,便于预览本次数据处理从输入节点中提取的数据,采样数量的多少不影响运行时实际提取的数据量。
如果采样数量大于0,但预览数据为空,则表明提取的数据为空,节点执行时,不会有数据加载到数据表中。
采样方法分为默认采样、随机采样、全部三种方式。
默认采样:即按照数据在数据库中的存储位置,按顺序抽取采样数量中指定的数量。
随机采样:即不关注数据库中的存储位置,随机抽取采样数量中指定的数量。
全部:采样方法选择“全部”时,抽取数据库中的全部数据,不能再手动设置采样数量。
输出节点
数据处理后通过输出节点存放到指定的数据库中。下面详细介绍输出节点。
基本信息
输出节点基本信息包括节点名称、输出路径、表名。
节点名称:指画布中输出节点的名字,支持修改。
输出路径:数据存放的路径。默认为新建项目时选择的目的地,可以进行修改。目前支持MySQL、Apache Doris、StarRocks、PostgreSQL、Greenplum、Oracle、SQL Server、ClickHouse、Dameng、Saphana、Presto、Amazon Redshift、Amazon Athena、Alibaba Hologres、TDSQL MySQL、TDSQL PostgreSQL和 AnalyticDB MySQL 作为输出节点存放路径。
表名: 输出节点执行后数据存放在数据库中的名称,默认表名为输出节点。
提示
当前用户必须具有输出目录或输出表的读写(RW)权限,项目才能执行成功。
输出设置
输出设置包含:验证 schema、表操作、更新方法、加载前 SQL、加载后 SQL。在输出节点中的执行顺序为 加载前 SQL->验证 Schema->表操作->更新方法->加载后 SQL。
验证 Schema
验证 Schema 会验证输入字段和输出表字段是否匹配。
选中
验证 Schema时,只有 schema 匹配,输出节点才会运行,否则,输出节点执行过程中会报错。匹配规则为:- 两边字段数量和名称要一样,数量不一样或名称不一样,都算不匹配。
- 名称一样的字段,原始类型转成衡石类型要一样。其中,衡石类型(数字/文本/日期/布尔/json)在后端是用 type 字段来标识的。
未选中
验证 Schema时,对输出表会进行如下处理:- 对于输入表缺少的字段,输出表字段填充为 null。
- 对于输入表多出的字段,会在输出表增加该字段,并填充新行,对于输出表中已有的行,则填充为 null。
- 如果字段名称相同,字段类型不兼容,比如输出表字段类型为数字,输入表字段类型为字符串,项目执行失败。
- 如果字段名称相同,字段类型兼容,比如输出表字段类型为文本,输入表类型为数字,项目执行成功。
表操作
表操作定义在输出表已存在的情况下,对输出表进行的操作。新建表时,该项不起作用。
无:表示对输出表不进行任何操作,保留原样。
重建表: 删除原有的输出表,然后按照输入字段 Schema 重建表。
清空数据:清空表中的数据。
提示
- 重建表在实际操作过程中,先在输出路径下建一张临时表存放数据处理结果,当数据处理完成时,删除原有输出表,将临时表更名为原有输出表。但是在 TDSQL-MySQL 数据源中,因为不支持临时表重命名操作,所以只能先删除原有输出表,当数据处理过程发生异常情况时,新的输出表没有数据,所以使用 TDSQL-MySQL 数据源时请谨慎选择。
更新方法
定义输入的数据如何更新到输出表中。
Insert:将数据插入输出表中,即追加到输出表中。
Upsert:Upsert = Update + Insert,对已有的行进行更新,对新行进行插入。
提示
选择 Upsert 时,必须设置键字段,用于识别在输出表中已存在的行。对于已存在的行,根据键字段来更新现有的行。对于不存在的行,直接插入到输出表中。
键字段
键字段用来做主键和分布键。键字段有两个功能。
- 增量更新时用来做主键。
- 建表时用来做主键和分布键。 在建表时如果设置建表属性,优先使用建表属性的配置,键字段即使设置也不生效。
建表属性
在数据同步表创建过程中自定义分区字段和索引字段,对数据进行分散存储。 建表属性仅在第一次建表时生效。 目前支持建表属性的数据源包括 Greenplum、Apache Doris、StarRocks 和 ClickHouse。 示例:
DISTRIBUTED BY (username)
PARTITION BY RANGE (username)
( START (varchar 'A1') EXCLUSIVE
END (varchar 'A8') INCLUSIVE,
DEFAULT PARTITION extra
);加载前 SQL
将提取的输入数据加载到输出表之前执行的 SQL,是输出节点执行的第一个配置。
加载后 SQL
将提取的输入数据加载到输出表之后执行的 SQL,是输出节点执行的最后一个配置。
转换节点
转换节点是 ELT 中 T 的部分,使数据整合能力更加完善,帮助企业实现敏捷的业务预处理的需求。在数据处理流程中加入转换节点,以可视化的方式,低门槛地完成对数据进行各类清洗和转换操作,完成灵活的数据加工需求。
联合
联合节点实现了两个数据源的联合处理,如图所示,连接待合并的数据源,然后选择联合类型、联合条件,就完成了联合节点操作,通过数据预览查看数据处理结果。 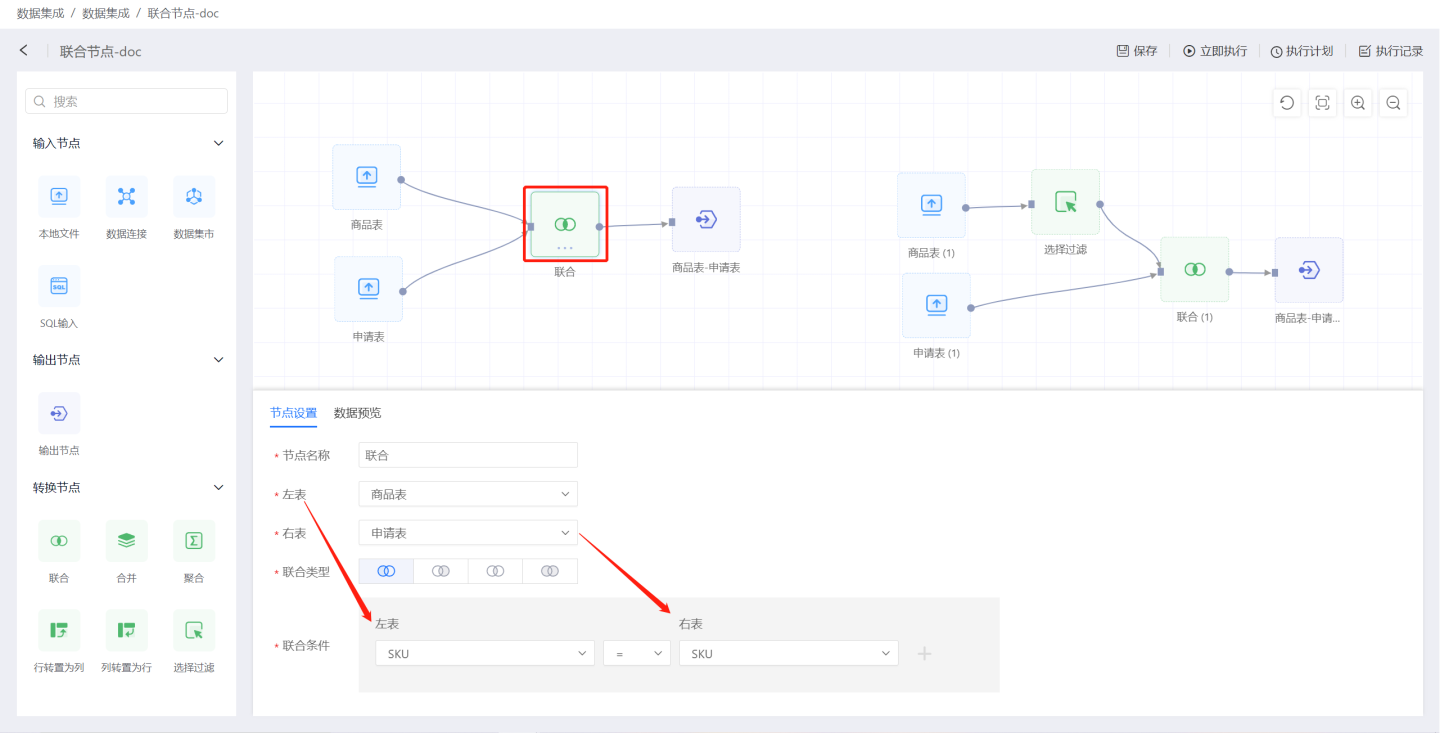
联合节点配置内容说明:
- 节点名称:默认为
联合,支持用户修改。 - 左表:待联合操作的数据源,约定为左表。
- 右表:待联合操作的数据源,约定为右表。
- 联合类型:支持左连接、右连接、内连接、外连接四种连接类型。
- 联合条件:可以设置一个或多个联合条件。
提示
联合节点仅支持对两个数据源进行联合操作。
合并
合并节点将多个数据源信息合并成一个表信息。 如图所示,将1月到3月的订单表的节点连接到合并节点生成季度订单表。 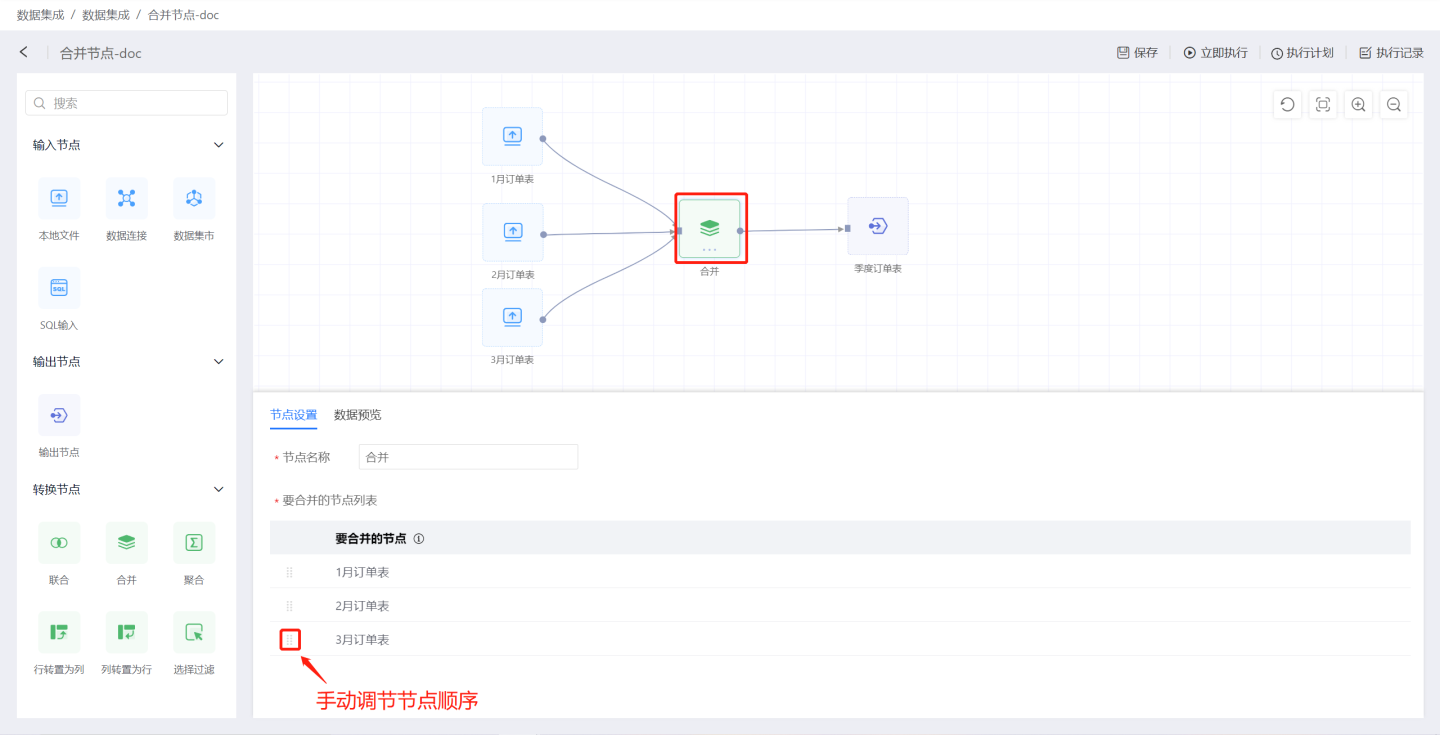
合并节点配置内容说明:
- 节点名称:默认为
合并,支持用户修改。 - 合并节点列表:待合并数据节点,按照连接顺序排序。支持手动调整顺序。
合并规则:
- 以合并节点列表中第一个节点为基础数据,该节点的字段名称、字段类型、字段顺序将作为输出数据的字段名称、字段类型、字段顺序。
- 从第二个节点开始,按照以下规则与第一个节点进行合并。
- 当字段名与第一个节点的字段名相同、类型均相同时,将该字段内容填充到输出数据对应字段中。
- 当字段名与第一个节点的字段名相同,但类型不同,则尝试对类型进行转换,转换成功,则将该字段内容填充到输出数据对应字段中,转换失败,则输出数据对应字段填充 NULL。
- 当字段名与第一个节点的字段名不同,则该字段被丢弃。
- 当不存在第一个节点中的字段时,对应的输出数据的字段填充 NULL。
- 支持手动调整合并节点顺序。
聚合
聚合节点指对输入的数据源进行聚合操作。 如图所示,将1月订单表中的订单价格和快递费进行聚合运算生成订单金额表。
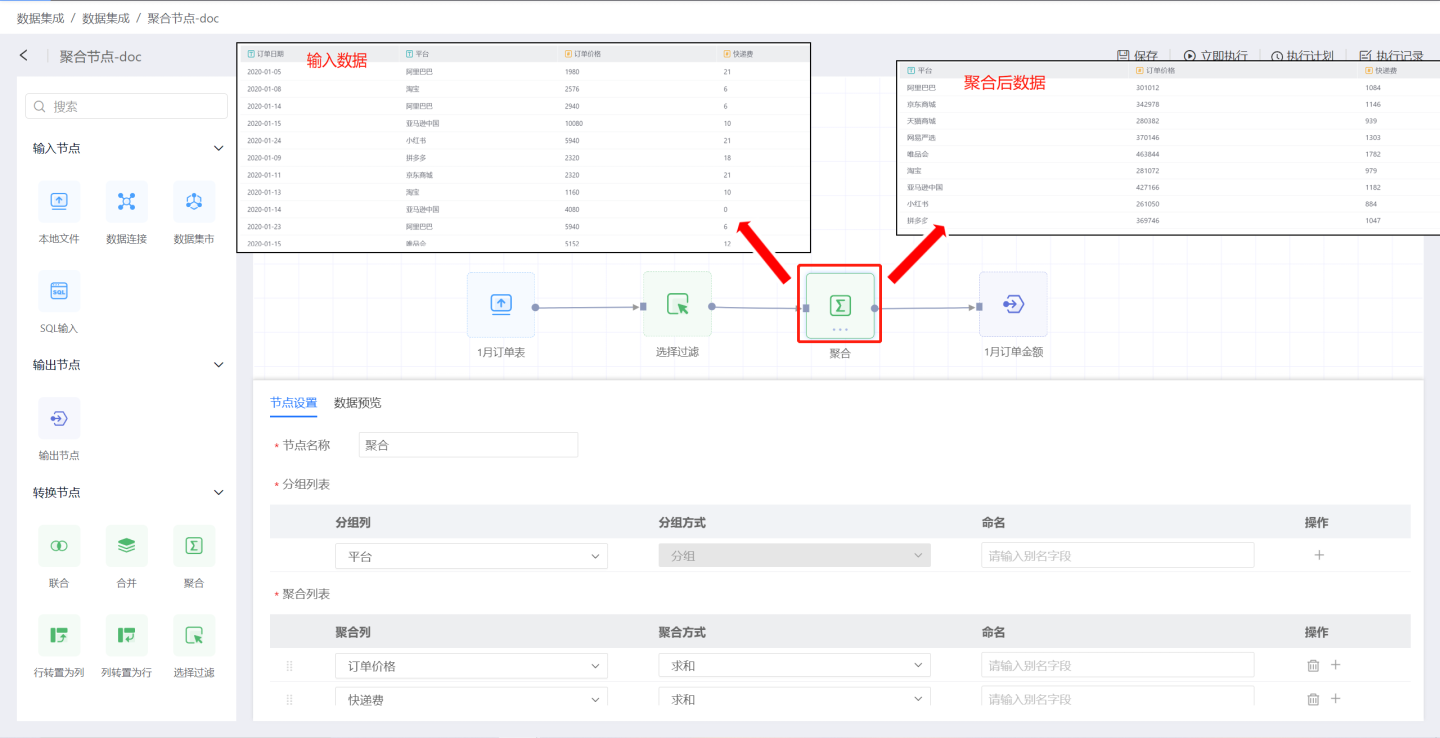 聚合节点配置内容说明:
聚合节点配置内容说明:
节点名称:默认为
聚合,支持用户修改。分组列表:保留输入数据中的字段。 分组列表将输入数据中的字段添加到输出数据中,可重新命名字段。 支持添加多个字段。
聚合列表:对输入数据中的字段进行聚合操作。 数字类型的字段支持平均值、求和、最大值、最小值、计数、去重等聚合操作。非数字类型的支持最大值、最小值、计数、去重等聚合操作。
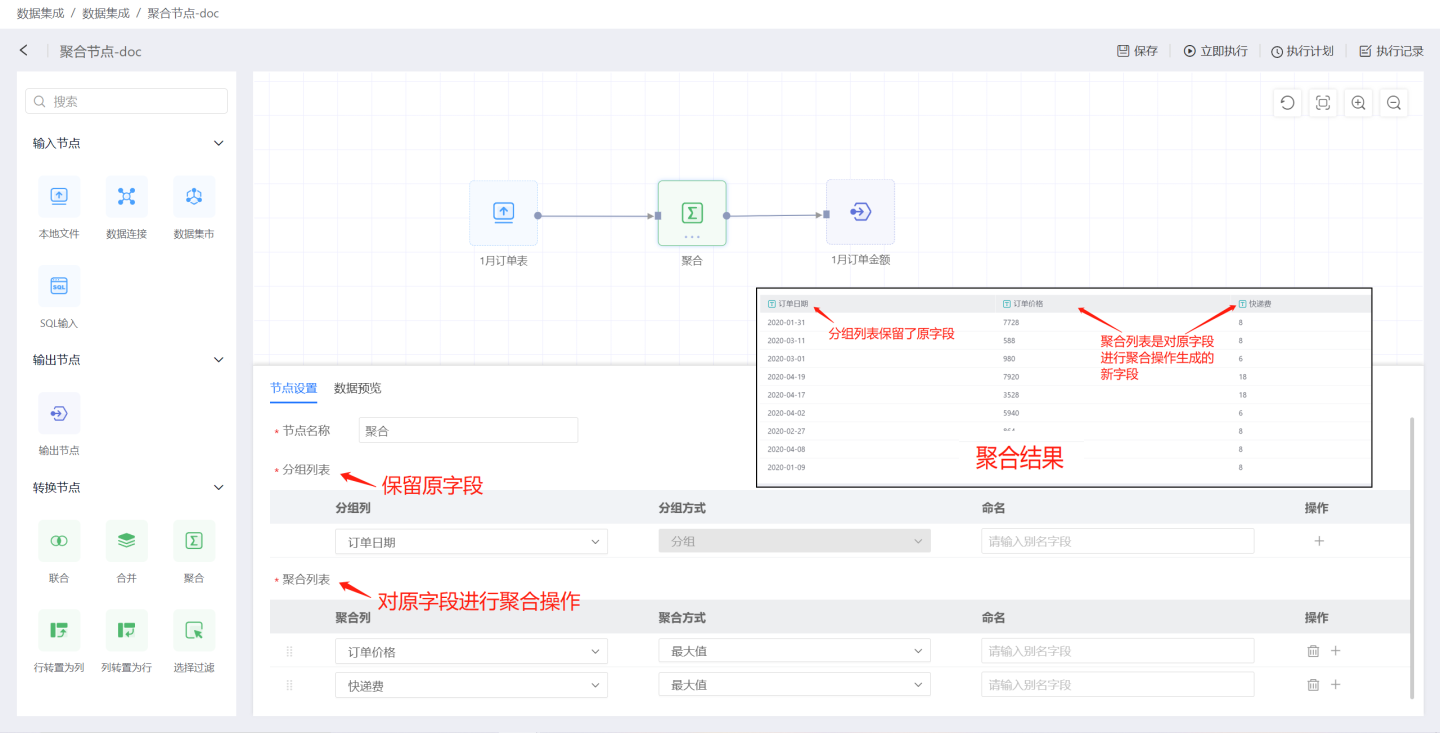
提示
聚合列表中的字段展示在分组列表字段后面。
选择过滤
选择过滤节点是对输入的数据进行选择和过滤操作。 如图所示,通过选择过滤节点从订单中选择各平台的每笔订单平均价格,并通过过滤功能最后筛选出淘宝平台上的相关信息。 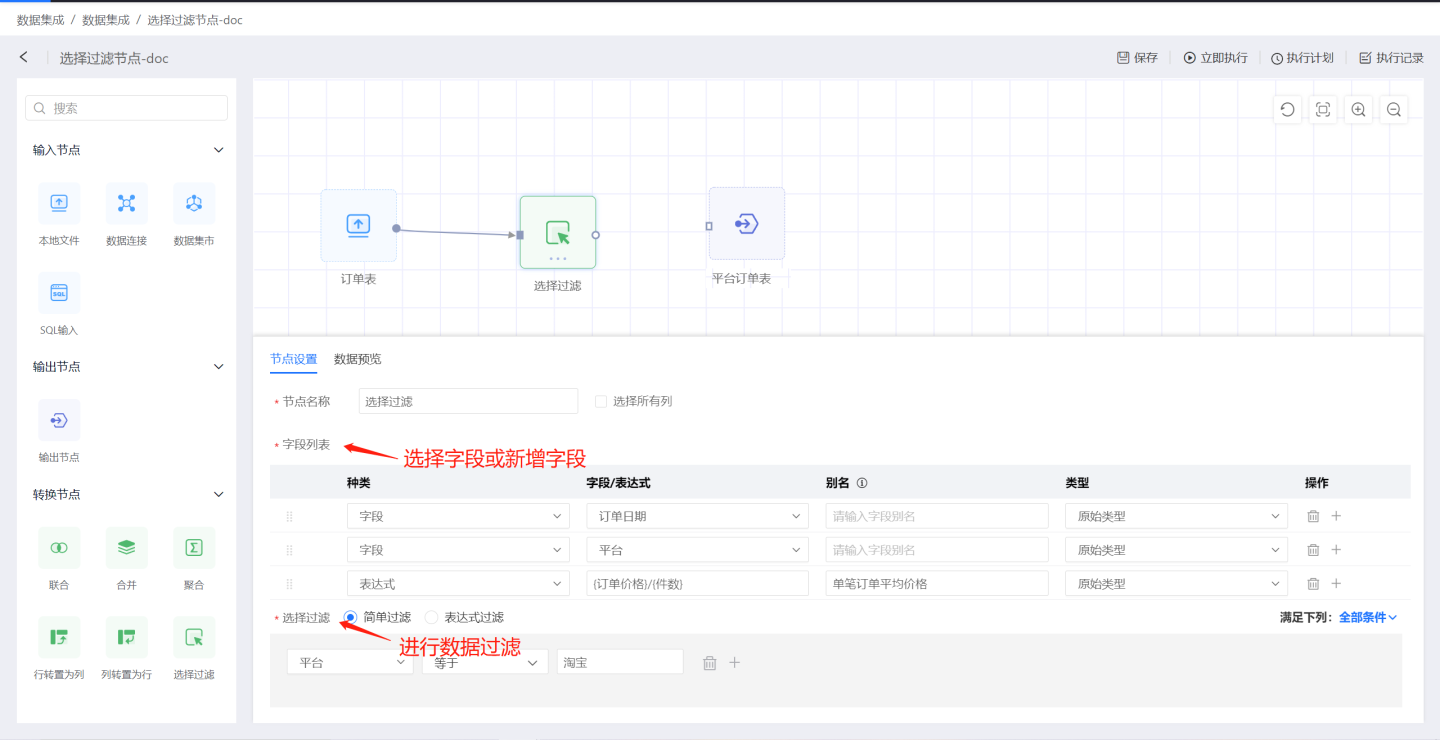
选择过滤配置内容说明:
节点名称:默认为
选择过滤,支持用户修改。选择所有列: 勾选时,将输入数据中所有列添加到输出数据,但是不在字段列表中展示。
字段列表:自主添加列字段。支持添加原有字段和使用表达式新增字段。
- 字段:添加输入数据中的原字段,可修改别名、字段类型。如果已经勾选了
选择所有列,再添加字段时,请修改别名,否则会发生字段名重复的情况。 - 表达式:使用表达式的方式新增字段。
- 字段:添加输入数据中的原字段,可修改别名、字段类型。如果已经勾选了
过滤方式
- 简单过滤: 用户通过选项设置过滤条件。当有多个过滤条件时,可以设置条件选取方式‘全部条件’或‘任一条件’。 全部条件指筛选的数据需要满足所有的过滤条件。 任一条件指筛选数据只要满足其中一个条件即可。
- 表达过滤: 用户通过表达式设置过滤条件,更加灵活的进行数据筛选。过滤表达式必须返回布尔值。 在表达式编辑区右侧是函数列表,供表达式使用。
选择过滤节点典型使用场景。
场景1:通过
选择所有列添加字段,并设置过滤条件。不使用字段列表增加字段。 如图所示,仅勾选选择所有列,字段列表不添加字段。使用简单过滤,过滤出平台为小红书的数据。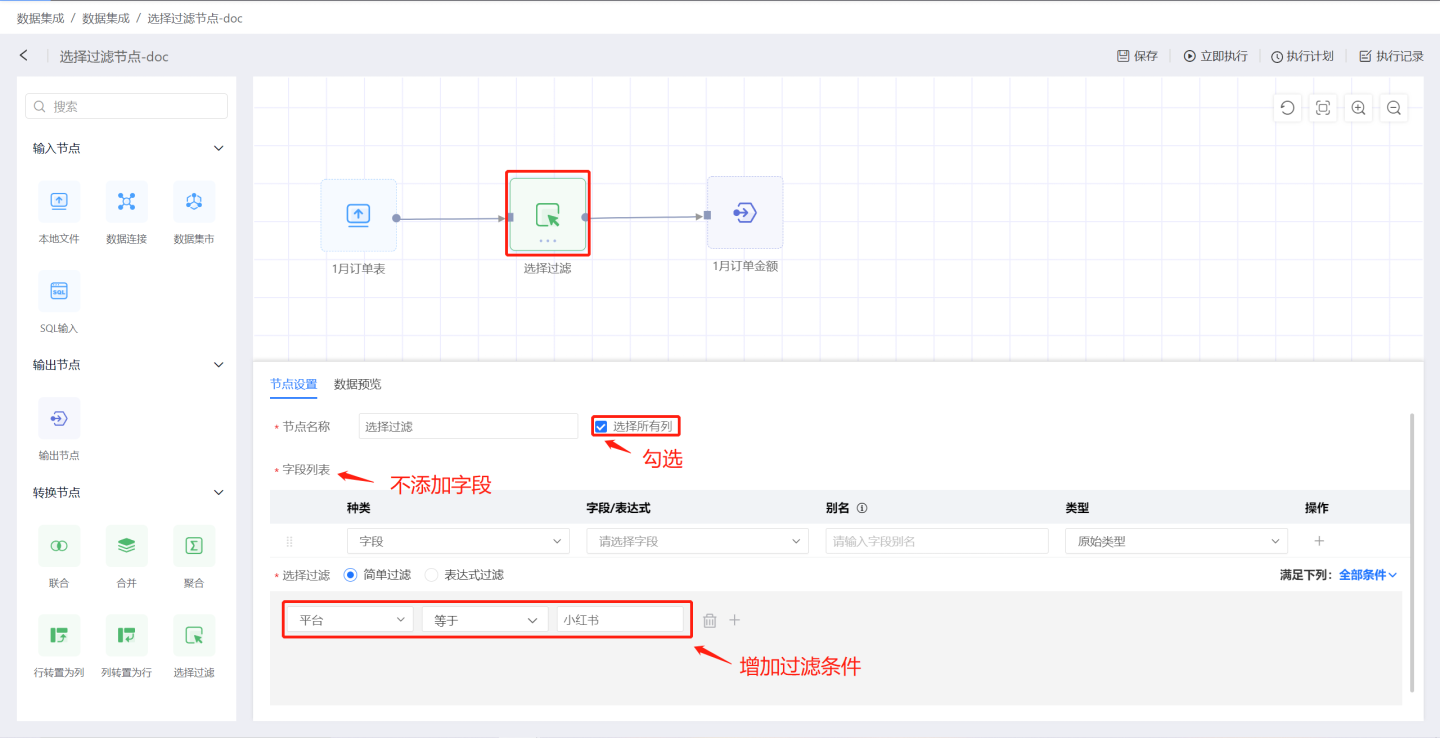 输出结果如图所示,包含了输入数据中所有字段信息,并筛选出平台为小红书的数据。
输出结果如图所示,包含了输入数据中所有字段信息,并筛选出平台为小红书的数据。 
场景2:在
字段列表中添加字段,并对字段进行过滤。 如图所示,在字段列表中选取原有字段订单日期和平台,使用表达式新建字段商品单价。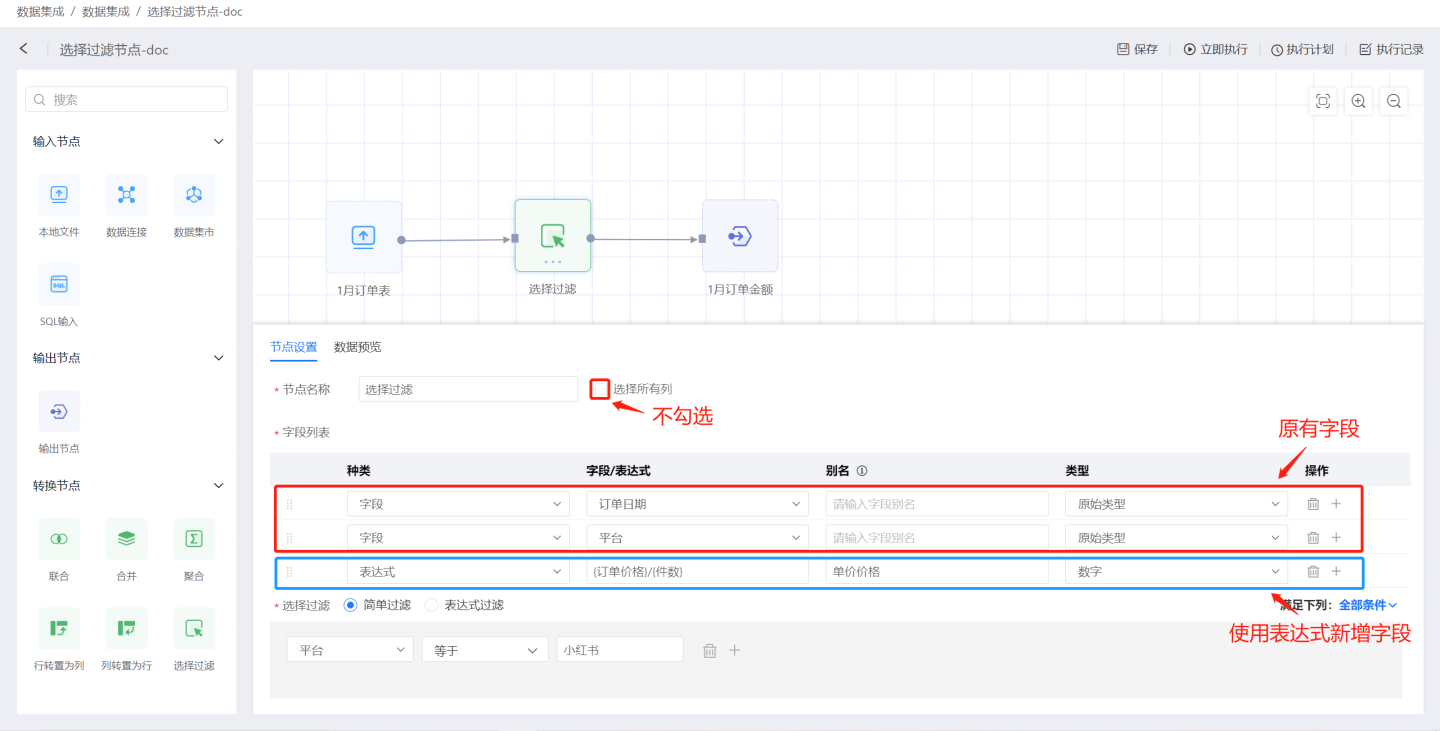 输出结果如图所示,仅有包含了字段列表中创建的3个字段,并根据过滤条件筛选出平台为小红书的数据。
输出结果如图所示,仅有包含了字段列表中创建的3个字段,并根据过滤条件筛选出平台为小红书的数据。 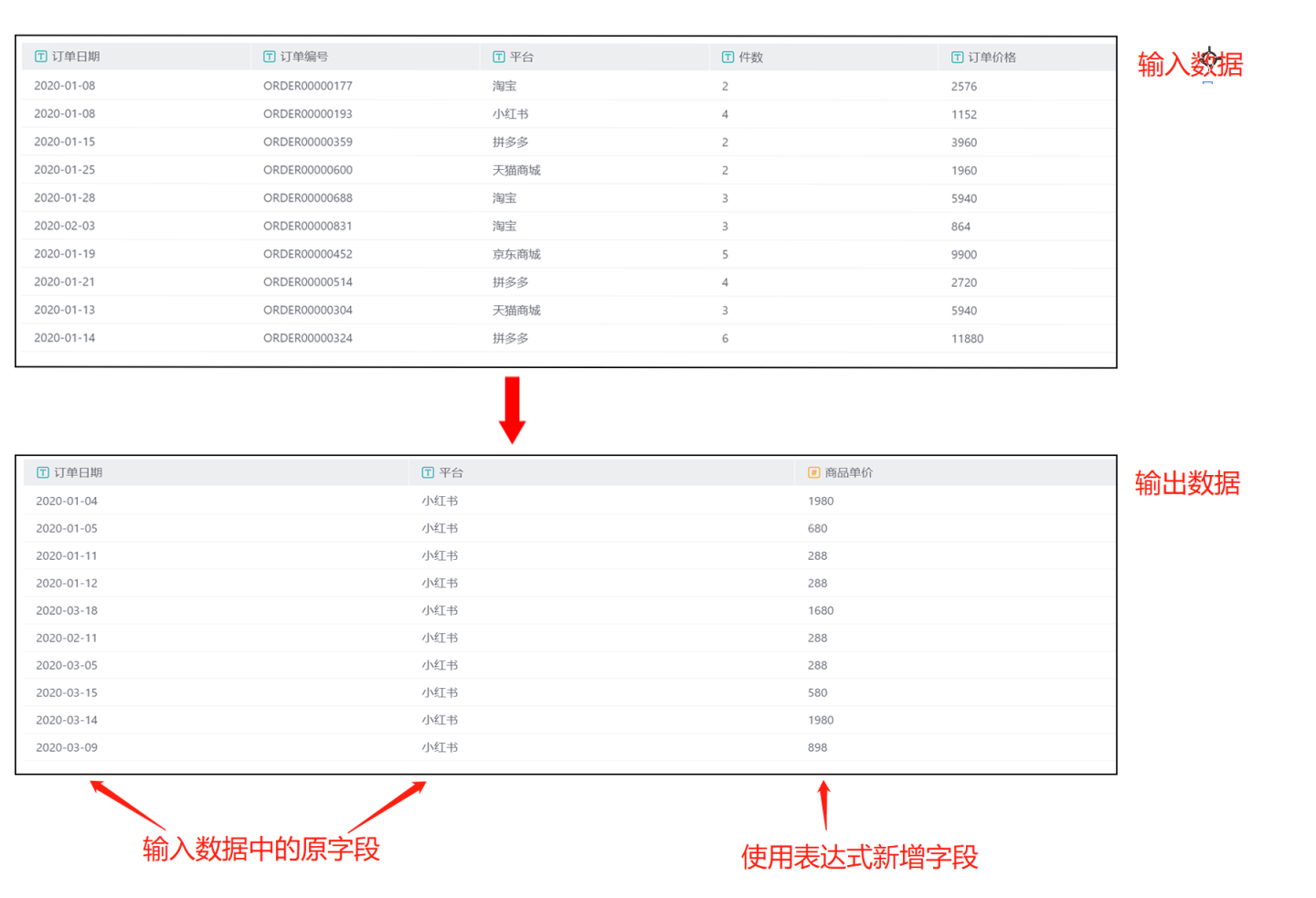
场景3:通过
选择所有列和字段列表添加字段,并设置过滤条件。 如图所示,勾选选择所有列,并在字段列表中增加原字段订单日期和平台,修改字段别名和类型,使用表达式新建字段商品单价。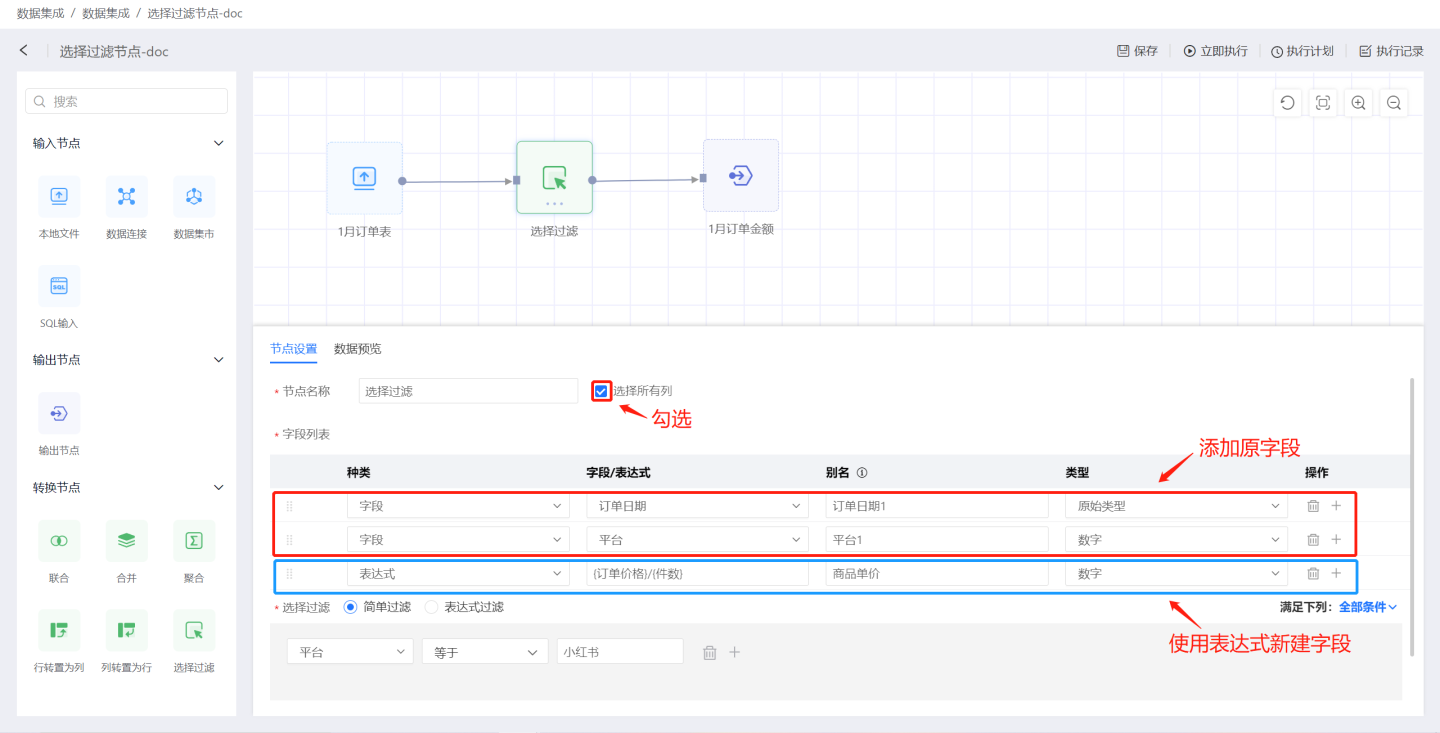 输出结果如图所示,包含了输入数据中全部字段,此外还包含了字段列表中创建的3个字段,根据过滤条件筛选出平台为小红书的数据。 字段列表中
输出结果如图所示,包含了输入数据中全部字段,此外还包含了字段列表中创建的3个字段,根据过滤条件筛选出平台为小红书的数据。 字段列表中订单日期和平台是添加的原字段,与选择所有列中的字段名称冲突,所以需要修改别名。平台1进行了数字类型转换,转换失败,所以使用 null 进行填充。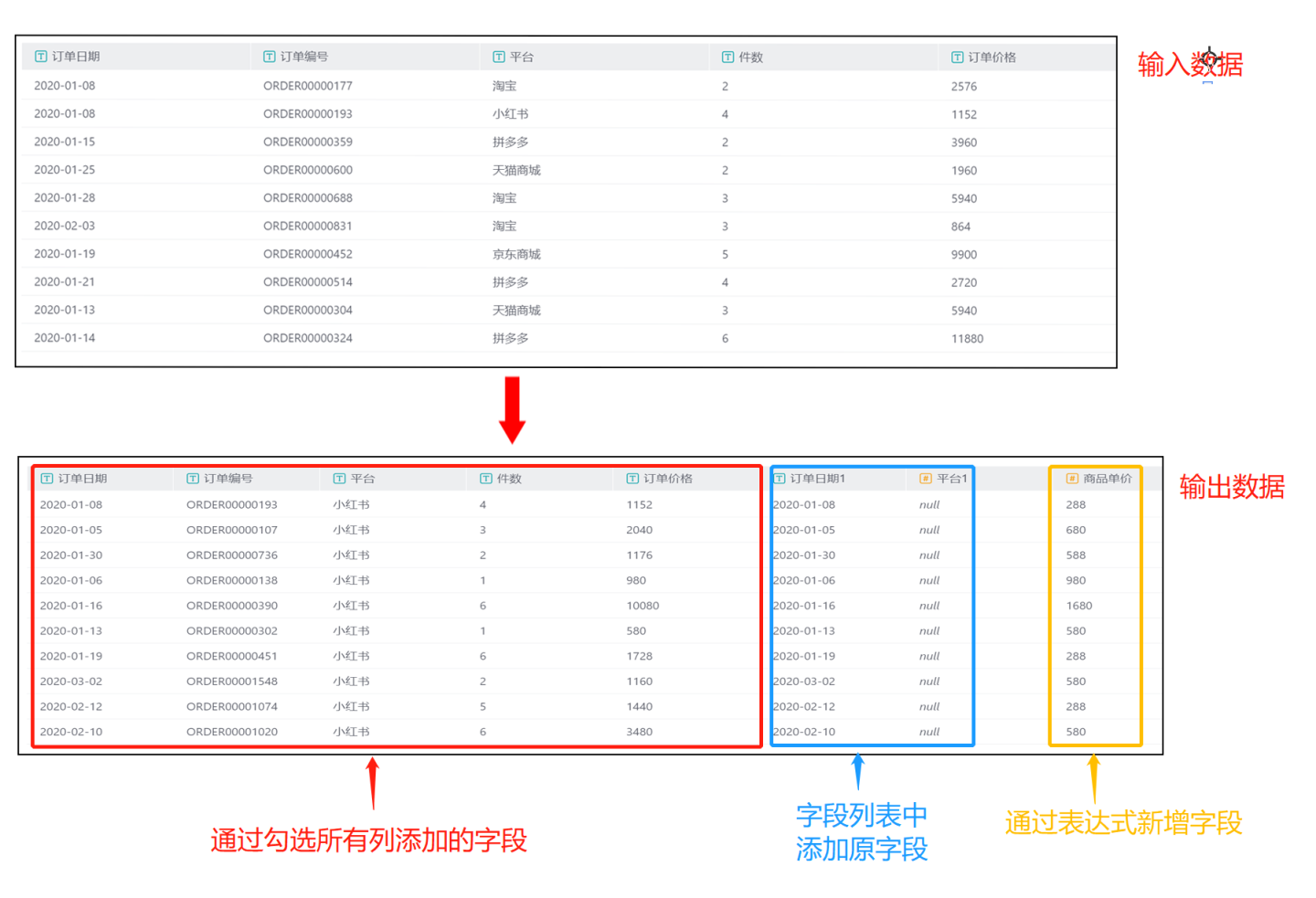
行转置为列
行转置为列是将输入数据中的某一行的值转换成列进行展示。如图所示,将平台字段中的淘宝、天猫商城、京东商城值转成列名,查看这三个平台订单费用总和情况。 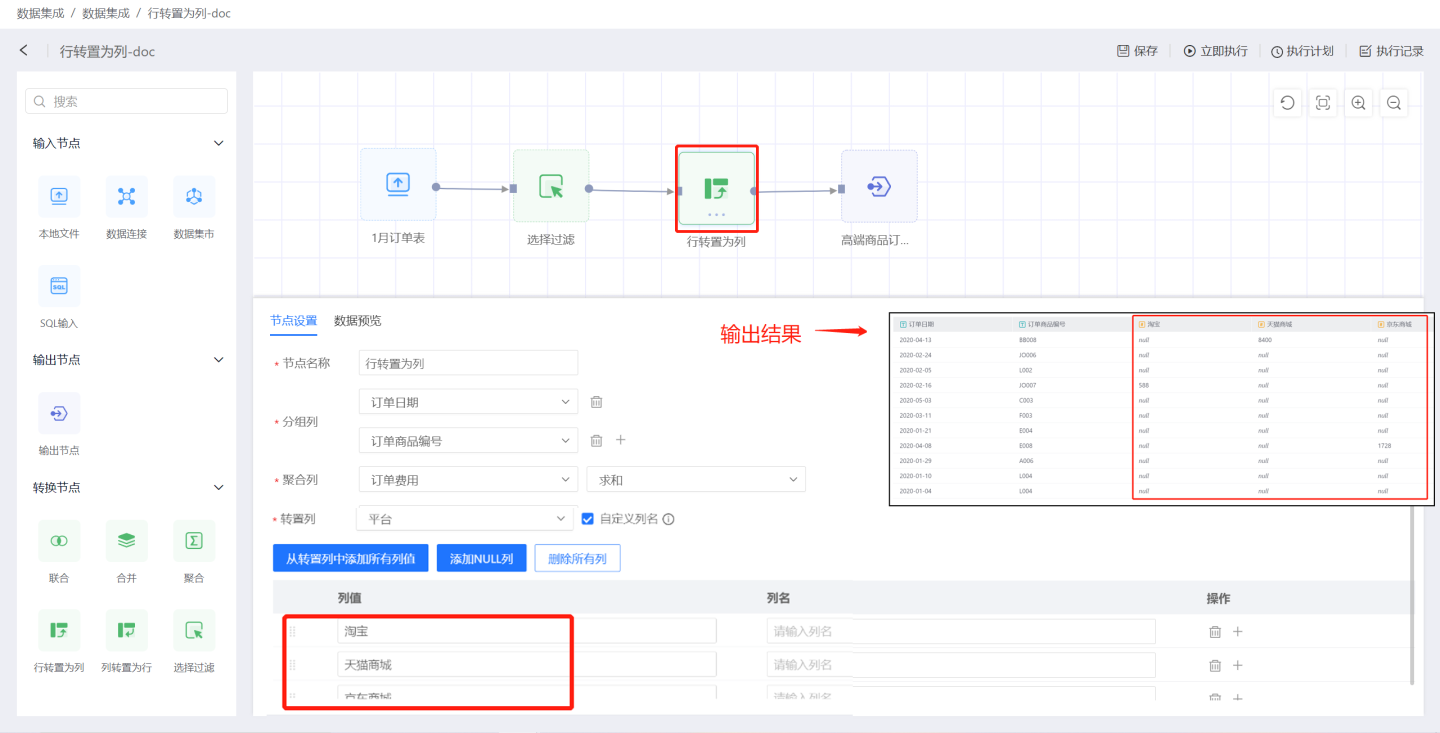
行转置为列节点配置内容说明:
- 节点名称:默认为
行转置为列,支持用户修改。 - 分组列:将输入数据中的原字段添加到输出数据中,可添加一个或多个字段。
- 聚合列:聚合列的值用于填充转置后的列。 聚合列为数字类型时支持平均值、求和、最大值、最小值、计数、去重等聚合操作。为非数字类型时支持最大值、最小值、计数、去重等操作。
- 转置列:需要转置为列的字段。默认情况下该字段的值都将以列的方式进行呈现。 支持用户自定义列名。用户可以自行添加列值字段,也可以通过快捷按钮进行操作。
- 从转置列中添加所有列值 将转置列字段所有列值展示出来,可通过删除按钮选择自己需要的列值进行转换,还可以修改别名。
- 添加 NULL 列 添加 NULL 值列。
- 删除所有列 删除列表中展示的所有列信息。
数据集成行转置为列节点典型使用场景。
- 场景1:使用默认方式,转置列中所有值都以列的方式进行展示,不自定义列名。 示例中节点配置添加分组列
订单日期和订单商品编号,转置列中将平台所有列值转换成列名,使用聚合列中订单费用的和来作为转置列的值。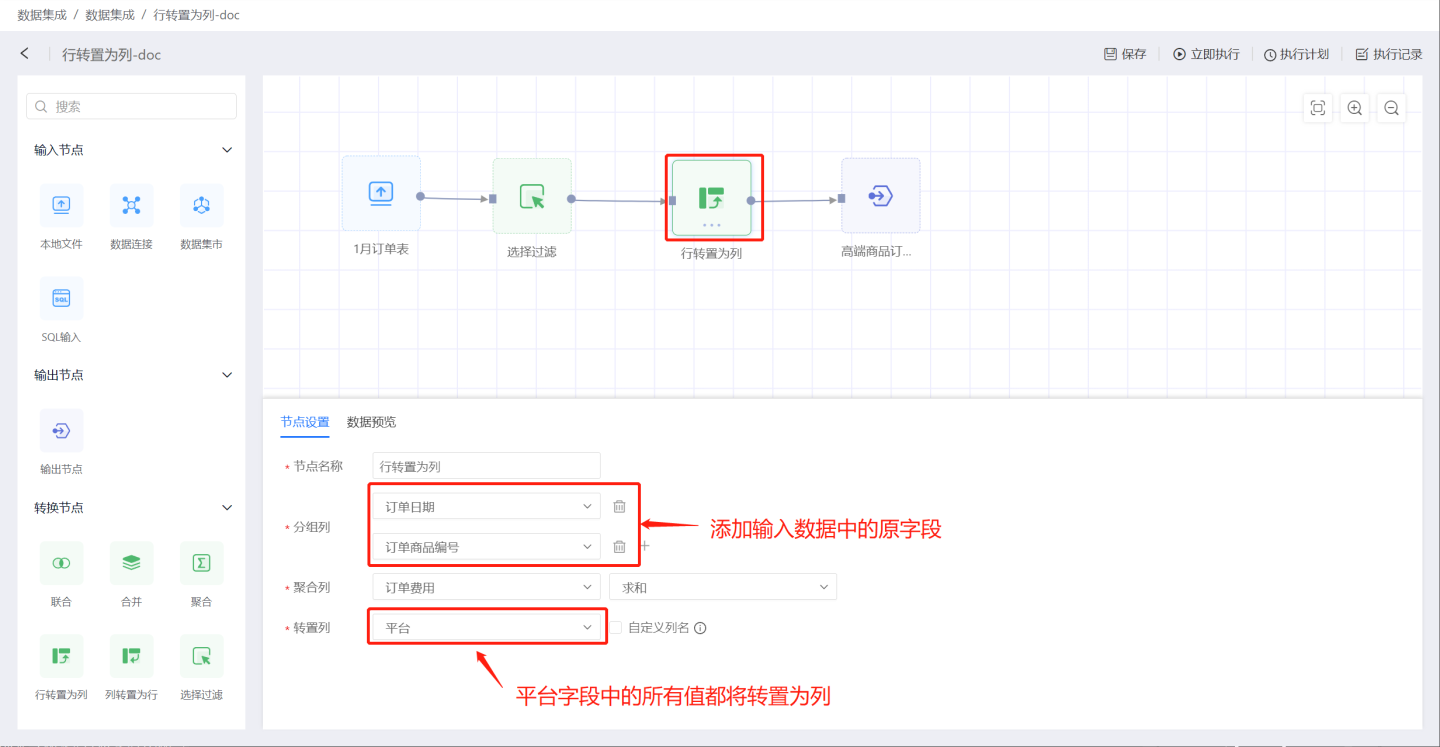 输出结果中包括原数据中
输出结果中包括原数据中订单日期和订单商品编号两列内容,平台中所有值转换为列(红色框部分),这些列的值使用订单费用的总和进行填充(蓝色框部分)。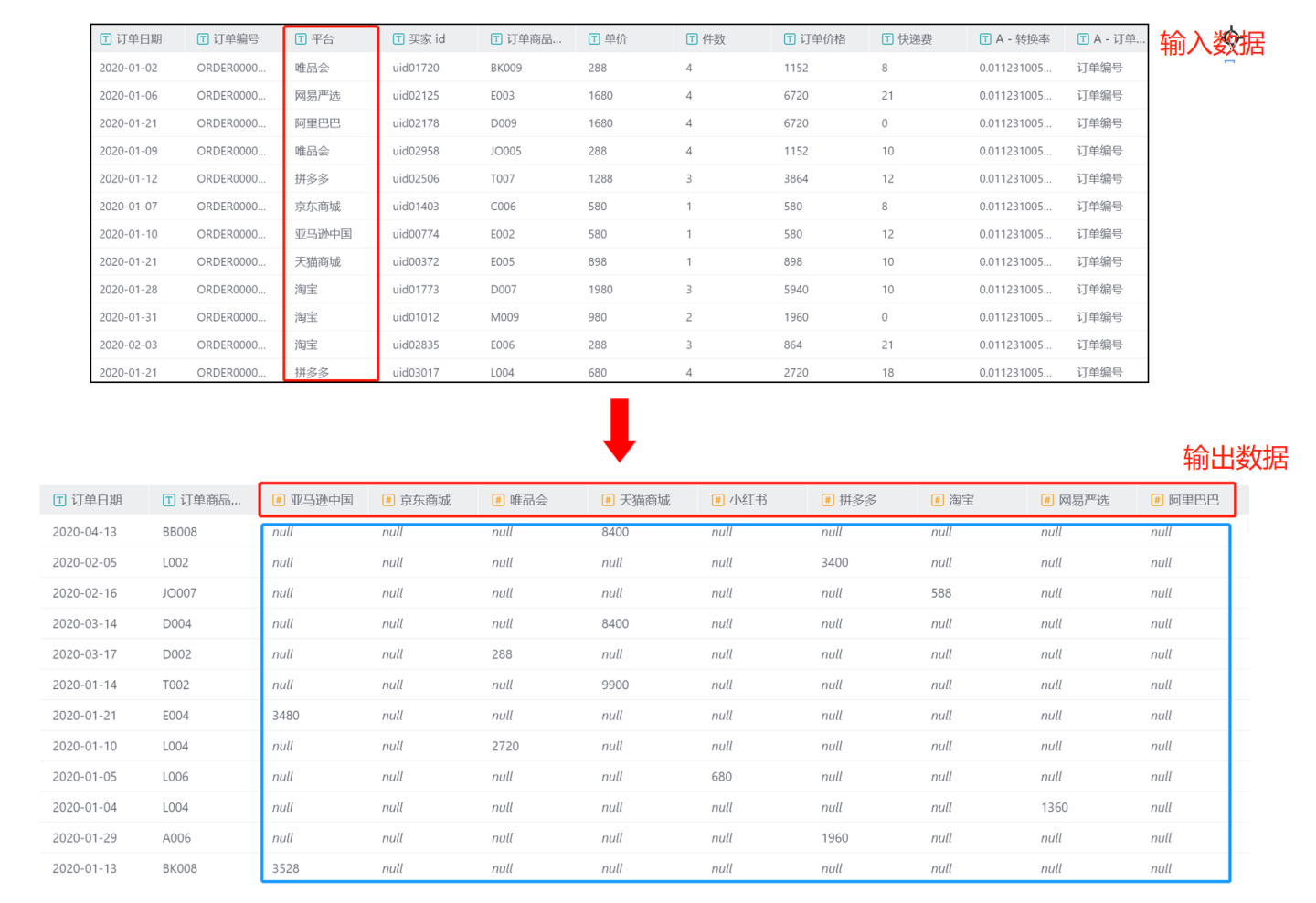
- 场景2:自定义添加转置列的列值。添加转置列值中的列值,同时添加非转换列中的列值。 示例中手动添加平台中的列值
淘宝、天猫商城、京东商城、空值和微店。空值和微店不是原有转置列中的值。 输出结果中包括原数据中
输出结果中包括原数据中订单日期和订单商品编号两列内容 ,包含平台中淘宝、天猫商城、京东商城三个列值,并用订单费用的总和进行填充。空值和微店是非转置列中的列值,这两个字段在原字段中没有订单费用相关信息,所以用 null 填充。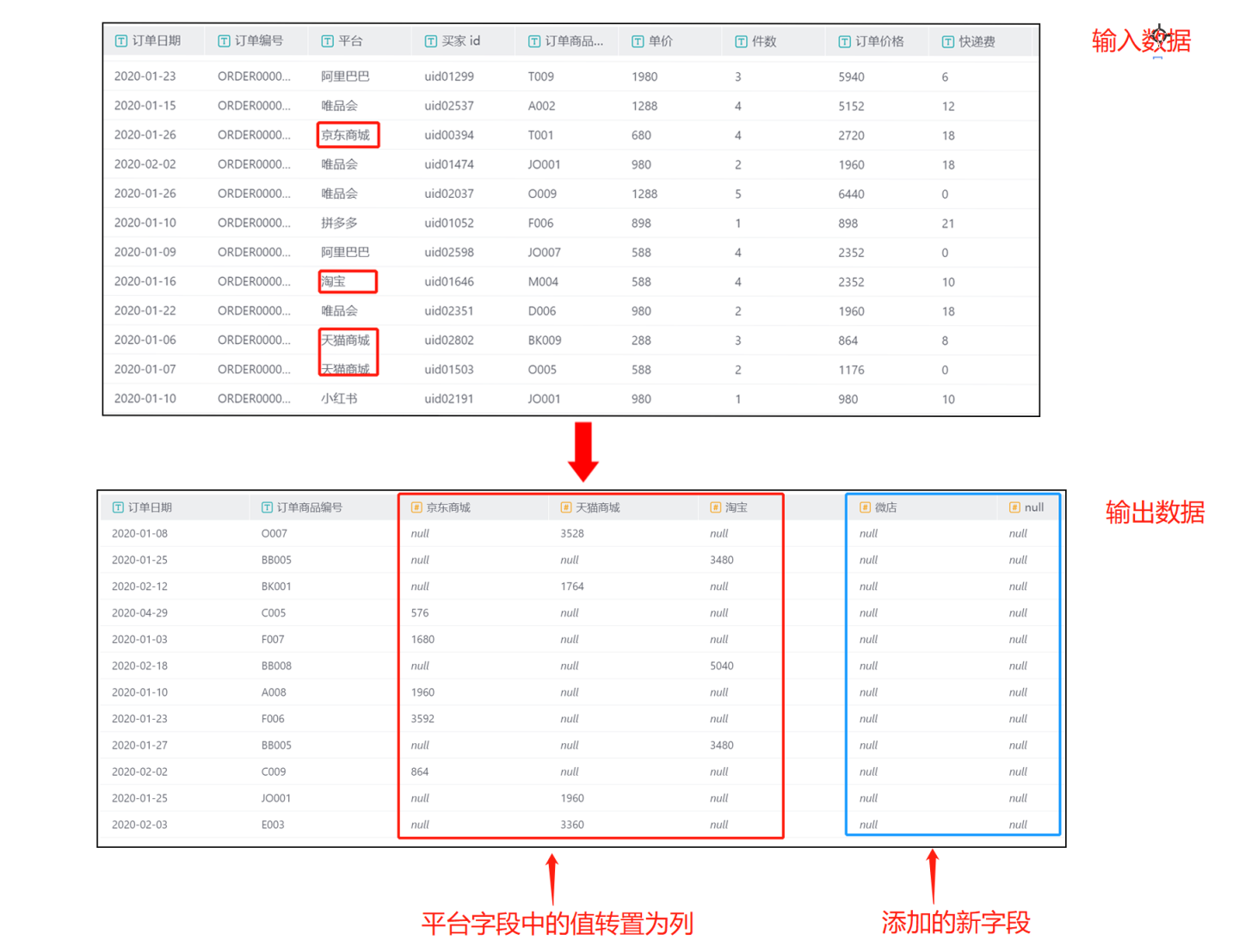
列转置为行
列转置为行是对输入数据中有共同特点的某几列数值将其进行汇总,转换成行进行展示。 如图所示,机器人、机械手、辅机、水电气都是部件的一部分,将其整理到部件列进行展示。 
列转置为行节点配置内容说明:
- 节点名称:默认为
列转置为行,支持用户修改。 - 转置分组列:
- 分组列名称:转置列转为行后的字段名称。 分组列类型包括文本、数字和日期三种类型。 转置列即待转为行的列,可以修改分组值,支持添加多个转置列。
- 转置数值列:转置列转为行后,其值所在的新列名。
数据集列转置为行节点典型使用场景。
- 场景1: 将具有共同特点的列转换成组进行展示,并修改转换后的分组值。 示例中将
机器人、机械手、辅机、水电气、自动化等列,转换为行存储在新列部件中,这些列的值存放到新列个数中。 其中水电气、自动化两个列在转换后修改名称为水电气装备、自动化组件。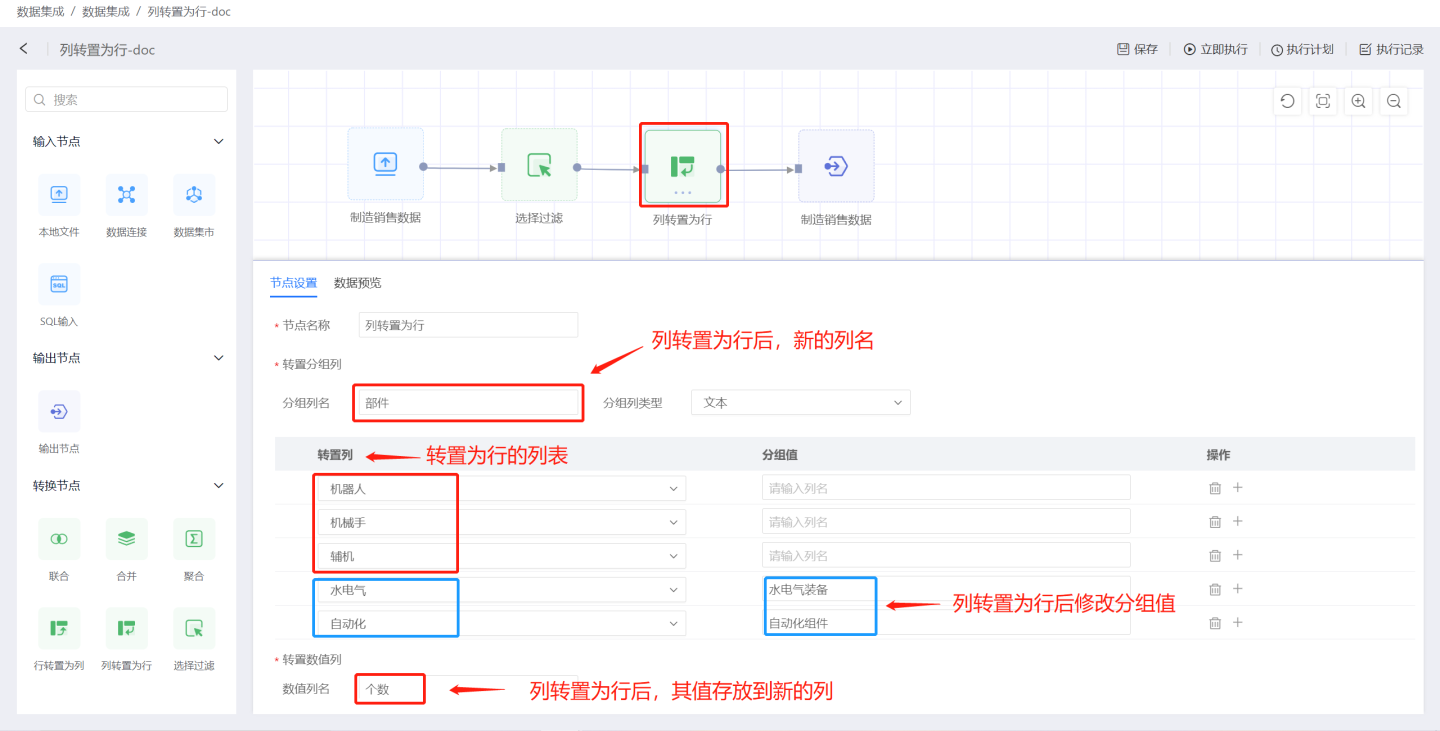 输出结果如图所示,转置后,
输出结果如图所示,转置后,机器人、机械手、辅机、水电气、自动化等列转置为行后存放在部件列中,机器人、机械手、辅机、水电气、自动化等列的值存放在个数列中。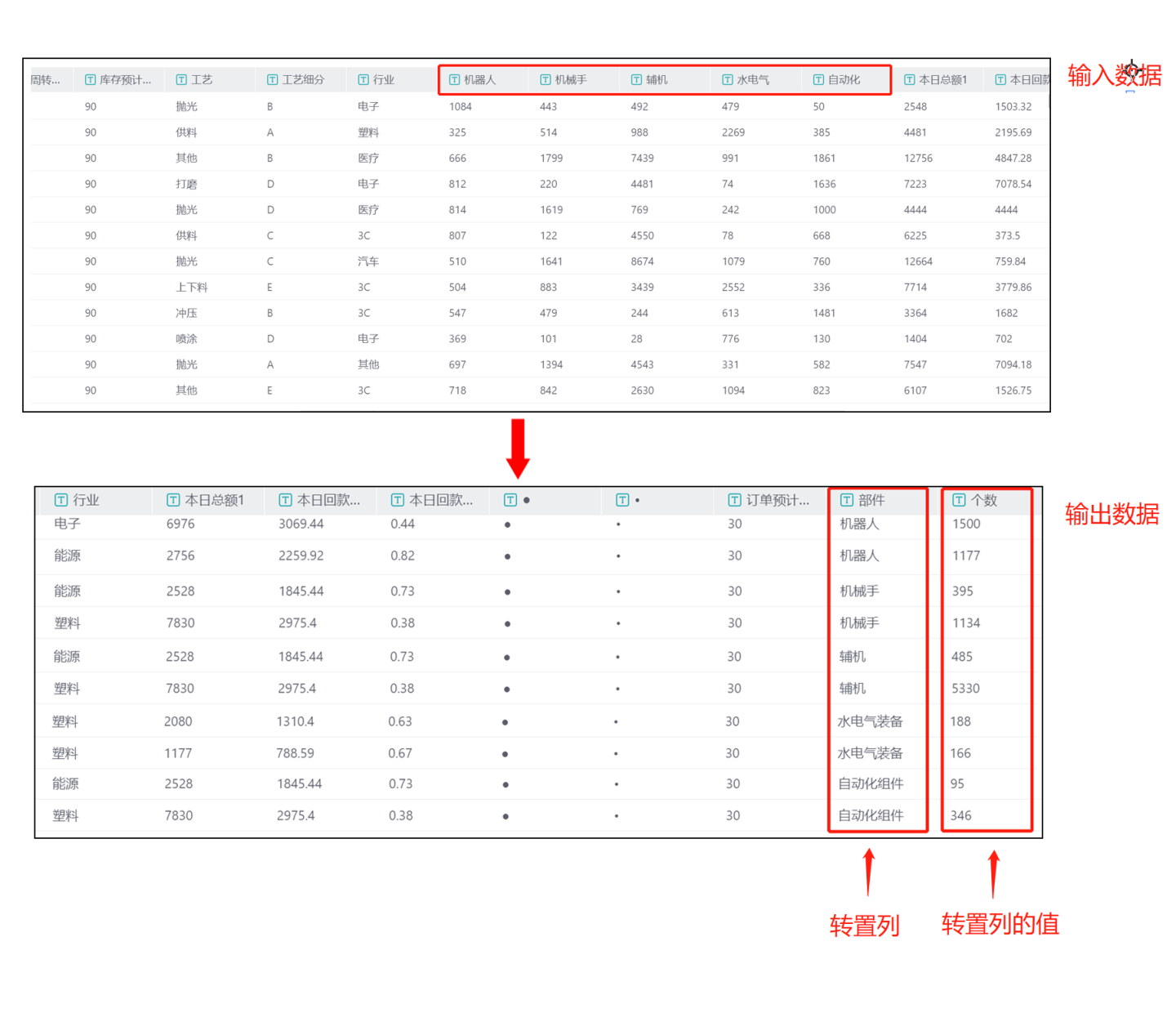
项目执行
数据集成项目中的数据节点都创建完成后,可以执行项目。每个项目支持立即执行和执行计划两种触发方式。
立即执行
点击立即执行后,项目会立即加入执行队列进行处理,按钮变为停止执行。
提示
根据执行队列任务排队情况,点击立即执行后项目可能处于排队中和执行中两种状态。 排队中:正在排队中的项目,点击停止执行,取消此次执行。 执行中:正在执行中的项目,操作按钮被禁用,不能取消执行,只能等待此次执行完成。
执行计划
点击右上角的执行计划,进入执行计划设置页面,设置计划的基本信息、调度信息、告警信息。
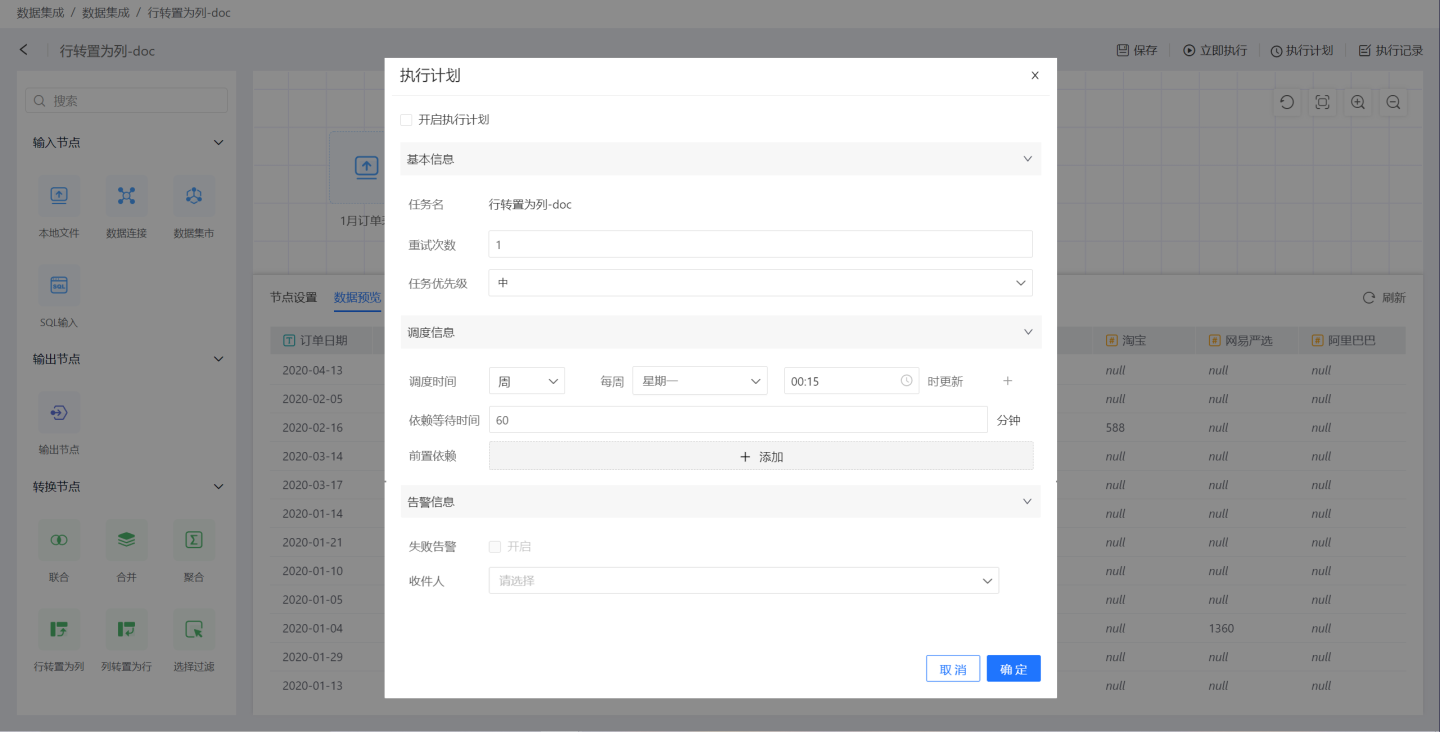
- 基本信息:设置执行时重试次数及任务的优先级。任务优先级分高、中、低三个级别。高级别的任务优先处理。
- 调度信息:
- 设置任务的调度时间,可设置多个调度时间。 支持按小时、天、周、月的方式设置执行计划。
- 小时:可设置每小时的第几分钟更新。
- 天:可以设置每天具体的时间点更新。
- 周:可以设置每周的周几的具体时间点更新,可以多选。
- 月:可以设置每月的第几天的具体时间点更新,可以多选。
- 自定义:可以自行设置更新的时间点。
- 设置任务的前置依赖,可设置多个前置依赖任务。
- 设置依赖等待时间。
- 设置任务的调度时间,可设置多个调度时间。 支持按小时、天、周、月的方式设置执行计划。
- 告警信息:开启失败告警,当任务执行失败后,会以邮件形式通知到收件人。
执行记录
点击项目右上角的执行记录可以看到项目的全部执行记录。
项目日常操作
数据集成项目支持新建、编辑、立即执行、复制、删除、筛选、搜索等操作。立即执行即项目的立即执行功能,这里不再展开说明。 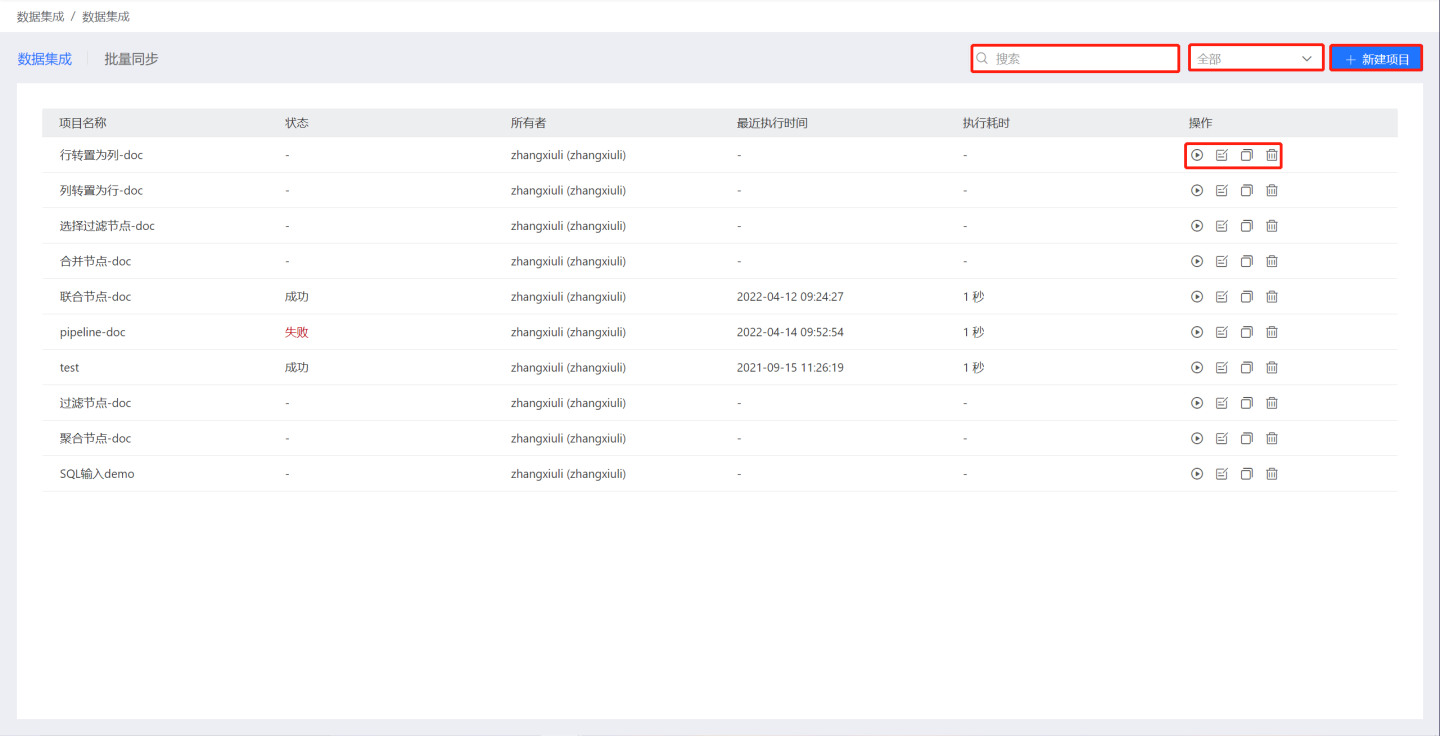
新建项目
点击右上角的新建项目,弹出新建项目的操作框,在弹窗中输入项目名称,在默认输出路径下拉框中的可选数据连接中选择项目的默认输出路径。
需要注意:
仅支持PostgreSQL、Greenplum、Amazon Redshift、MySql、Dameng、Amazon Athena、Hologres类型的数据连接作为输出路径。
作为数据集成的输出路径的可选连接,owner 在创建连接时必须勾选支持数据集成输出选项,否则无法存放输出表。
编辑项目
点击操作列中对应项目的编辑按钮,在弹出的编辑框中,可以修改项目的名称以及默认的输出路径.
删除项目
点击操作列中对应项目的删除按钮,会弹出一个确认框,点击确定删除项目。
筛选项目
项目筛选支持按照项目的执行状态分类筛选,执行状态的下拉框中包含:
- 全部
- 成功
- 失败
- 排队中
- 已取消
- 运行中
支持在选择指定筛选条件下搜索包含关键字的项目,例如,在所有项目中搜索包含关键字“数据集”的失败项目。
FAQ
- 画布区中的节点有红色闪电提示表示节点执行错误,红色叹号提示表示配置错误,请检查节点配置并修改。
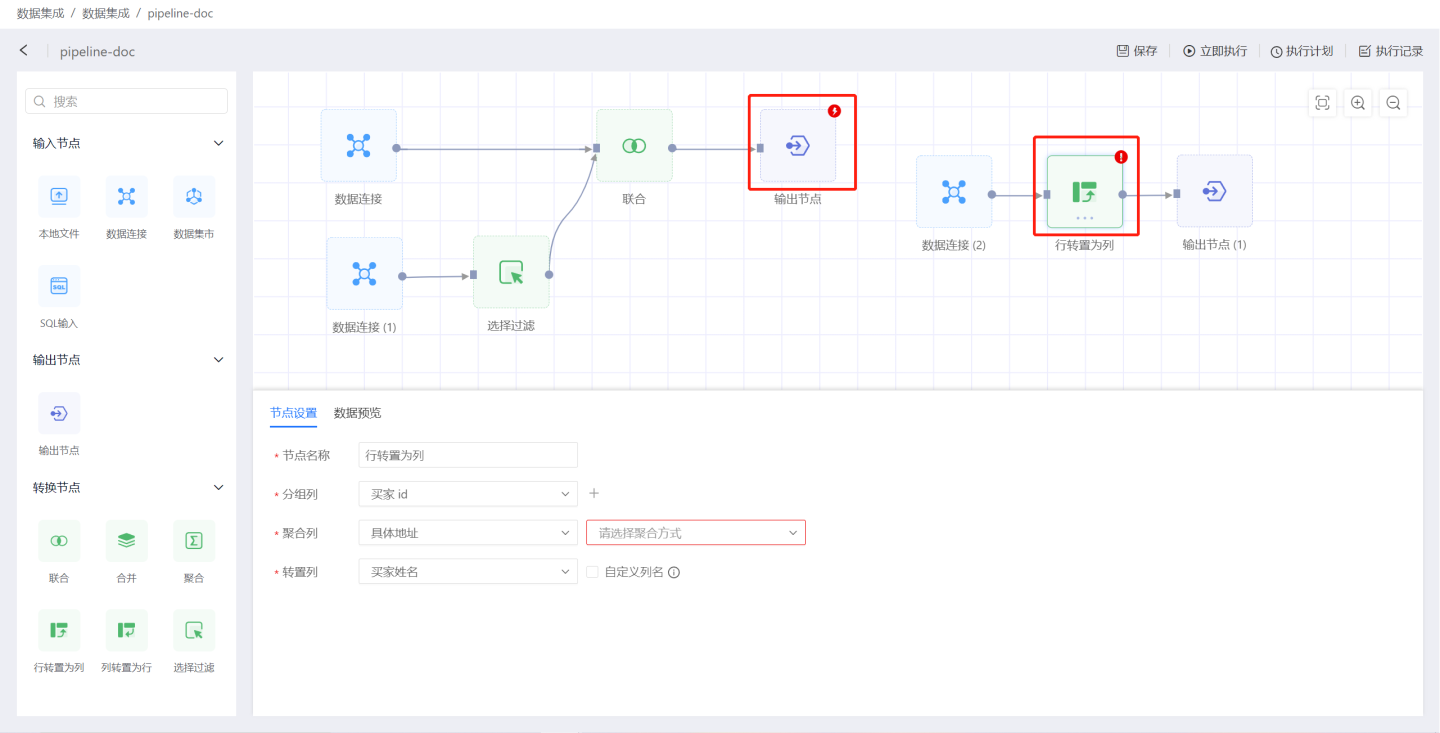
- 输出节点数据处理过程是:
加载前 SQL->验证 Schema->表操作->更新方法->加载后 SQL。 - 一个项目中如果某个节点执行失败,整个项目停止执行。
- 输入节点数据提取为空时,后续步骤不执行。