How to Introduce the Results of the Dataset Market in HENGSHI SENSE Visualization Creation
HENGSHI SENSE provides centralized dataset management, i.e., the functionality of a dataset marketplace:
Dataset Market, supporting the establishment of hierarchical dataset markets, authorizing data by user, user group, and organizational structure, and distributing data to the right people. It supports unified management of calculated fields and calculated indicators, enabling the statistical logic of key KPIs within the enterprise, ensuring consistent algorithms across departments, and saying goodbye to data inconsistencies. Comprehensive data permission settings support various permission models for data connection permissions and row permissions, meeting different permission management scenarios.
This section uses the coffee analysis data as an example to detail the subsequent usage features after users establish datasets in the data mart after the data mart function is provided.
Before using the documentation in this section, please first understand the restrictions on the visibility of datasets for different user roles:
| User Role | Dataset Market Visibility | Create Folder in Dataset Market | Create Dataset in Dataset Market Folder |
|---|---|---|---|
| System Admin | Invisible | ----- | ----- |
| Data Admin | Visible | Unable to Create, No Prompt | ----- |
| Data Analyst | Invisible | ----- | ----- |
| Data Viewer | Invisible | ----- | ----- |
| System Admin + Data Admin | Visible | Can Create | Can Create Any Dataset |
| System Admin + Data Analyst | Invisible | ----- | ----- |
| System Admin + Data Viewer | Invisible | ----- | ----- |
| Data Admin + Data Analyst | Visible | Unable to Create, No Prompt | ----- |
| Data Admin + Data Viewer | Visible | Unable to Create, No Prompt | ----- |
| Data Analyst + Data Viewer | Invisible | ----- | ----- |
| System Admin + Data Admin + Data Analyst | Visible | Can Create | Can Create Any Dataset |
| System Admin + Data Admin + Data Viewer | Visible | Can Create | Can Create Any Dataset |
| System Admin + Data Analyst + Data Viewer | Invisible | ----- | ----- |
| Data Admin + Data Analyst + Data Viewer | Visible | Unable to Create, No Prompt | ----- |
| System Admin + Data Admin + Data Analyst + Data Viewer | Visible | Can Create | Can Create Any Dataset |
The above table records the visibility of any user to the dataset market, as well as the operations that can be performed in the dataset market.
Users with the System Management + Data Management roles can create folders and data packages in the Dataset Market; users with the Data Management role cannot create new folders or data packages in the Dataset Market, but can create datasets in folders for which they have been granted authorization.
Below, we will use coffee analysis as an example to briefly introduce the entire process from completing data processing in the App Market to using the data package in data visualization to create charts.
Create Folder/Dataset
Users with the System Management + Data Management roles can create folders and datasets in the Data Mart.
Set Permission Management for the Folder or Dataset
After completing the above steps, you can set permission management for the folder or dataset in the three-dot menu on the cover of the App Mart list page:
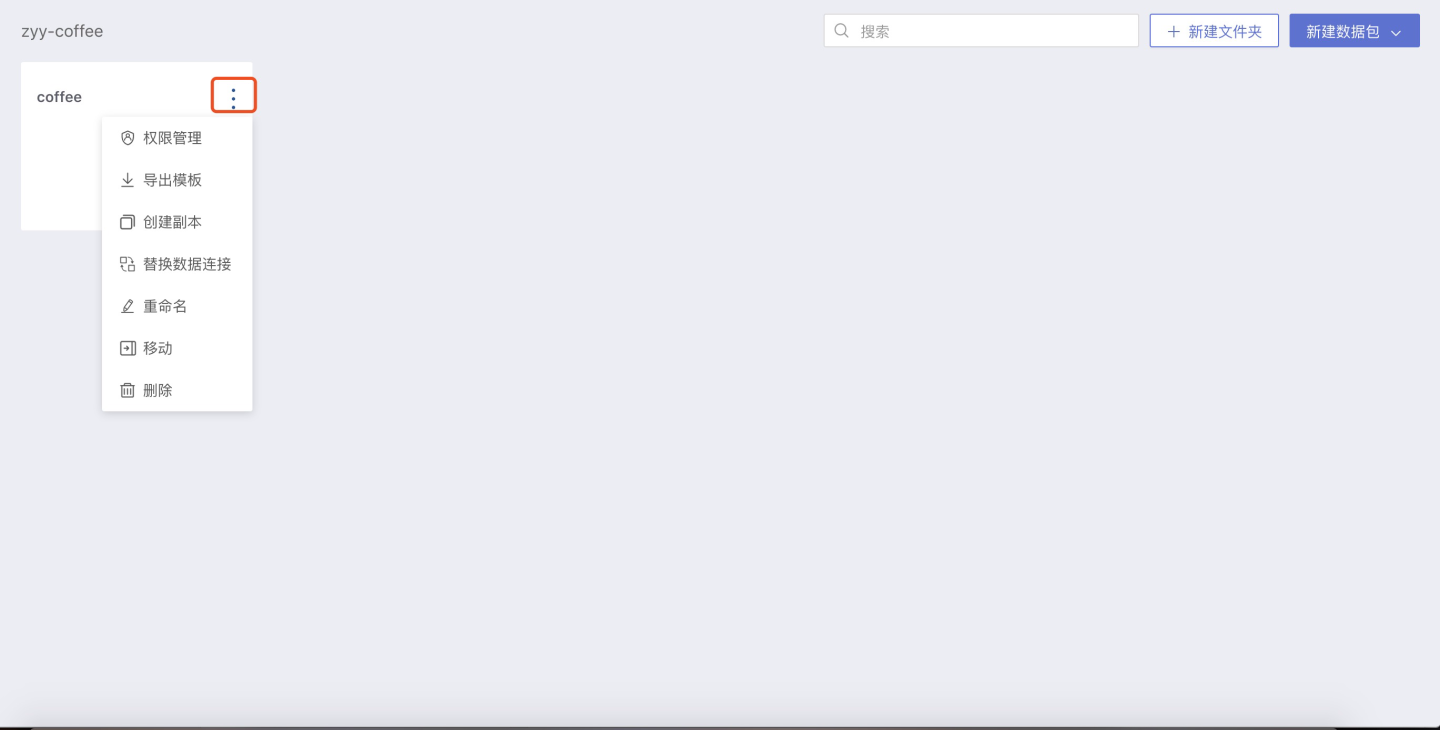
Click Permission Management, and set the management and view permissions for the dataset in the pop-up window:
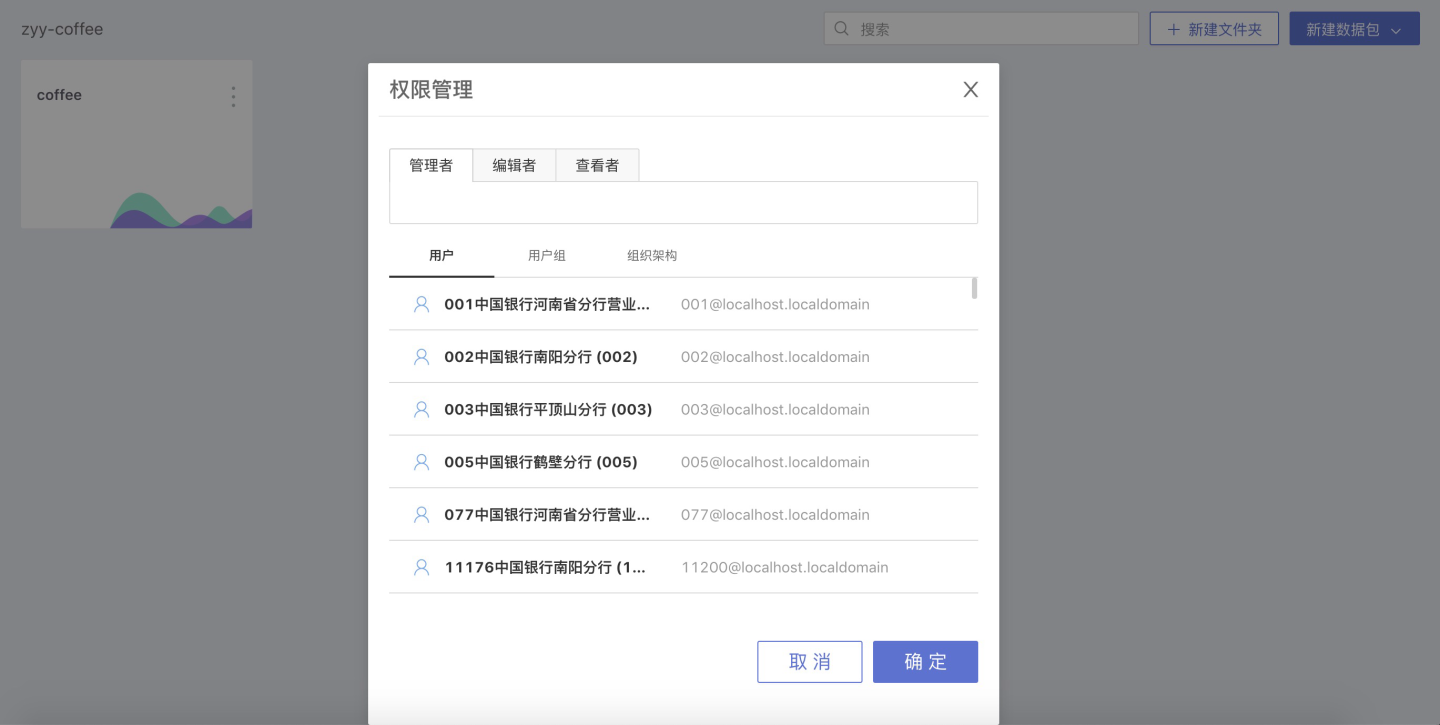
Manager: Has the same permissions as the creator of the folder, can modify the access permissions of the folder, view, use, and edit datasets within the folder and dataset;
Editor: Can only view, use, and edit datasets within the folder and dataset;
Viewer: Can only view and use datasets within the folder and dataset.
Set specific permissions according to the different responsibilities of different departments in each company.
Create a New Folder or Dataset
Within a folder, you can continue to create new folders or datasets. Users with Manager or Editor permissions can create folders and datasets within the folder.
Set Data Permissions for Datasets in the Dataset
On the Settings page of the dataset, you can set which account's permissions to use when users view and use the dataset. Users with Manager or Editor permissions for the folder containing the dataset can set data permissions within the dataset.
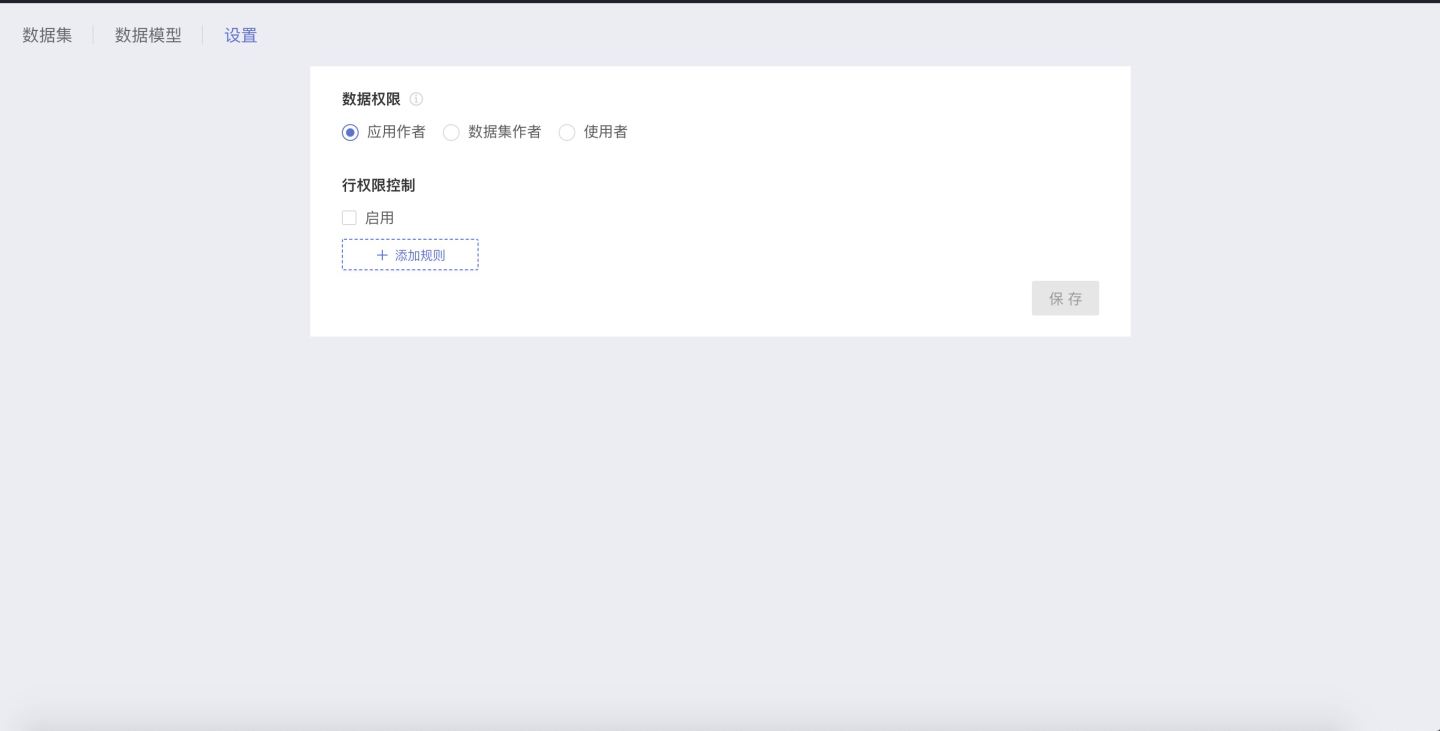
App Author
The app author's data is seen by the people accessing the app, with permission control available.
When different users create datasets in the dataset, they all use the data permissions of the app author on the data connection, regardless of their own permissions on the data connection.
Dataset Author
The dataset author's data is seen by the people accessing the app, with permission control available.
When different users create data in the dataset, they all use their own data permissions on the data connection. When viewing and using datasets, users obtain data according to the dataset author's permissions.
User
The user's own data is seen by the people accessing the app.
When different users create datasets, view, and edit datasets in the dataset, they all use their own data permissions on the data connection.
We recommend users to use the data permissions of the "App Author" when setting data permissions for the dataset. This avoids situations where subsequent dataset replication and multi-table union result in datasets with no data due to different permissions of each person.
When using "Dataset Author" or "User" for data permissions, confusion may easily arise during use:
User A creates Dataset A, User B creates Dataset B;
User C creates copies of Datasets A and B during data processing:
The copied datasets have no data: User C does not have the permissions for the data connection used by Datasets A and B;
The data in the copied datasets is completely inconsistent with Datasets A and B: User C's permissions on the data connection are different from those of Users A and B;
User D performs data processing, and Datasets A and B are combined into a Fusion dataset
The Fusion dataset has no data: User D's permissions for the tables in the data connection where Datasets A and B are located are inconsistent, resulting in no data in the dataset after association;
The data in the Fusion dataset has no overlap with Datasets A and B: User D's permissions for the tables in the data connection where Datasets A and B are located are inconsistent, resulting in completely non-overlapping data in the dataset after association;
After completing the above steps 1~4, the folder tree structure in the Dataset Market, the permission management of folders/data packages, and the data permissions of datasets in the data packages have been set up. That is, specifying which users can access the folder/data package, what operations can be performed on the folder/data package, and which data in the data package can be used.
Next, you need to complete the data processing in the dataset.
- Create Dataset
First, a dataset needs to be created in the Dataset Market:
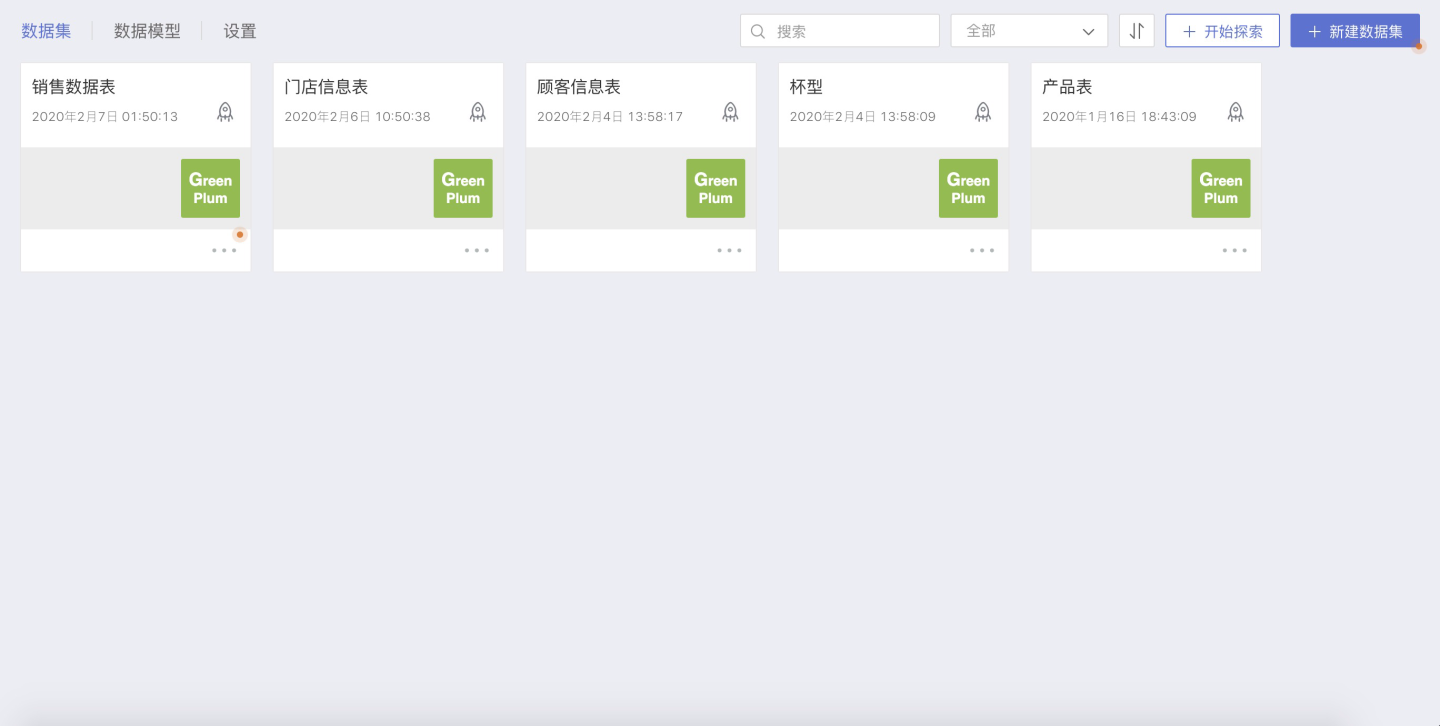
Data Processing
Dataset Data Processing
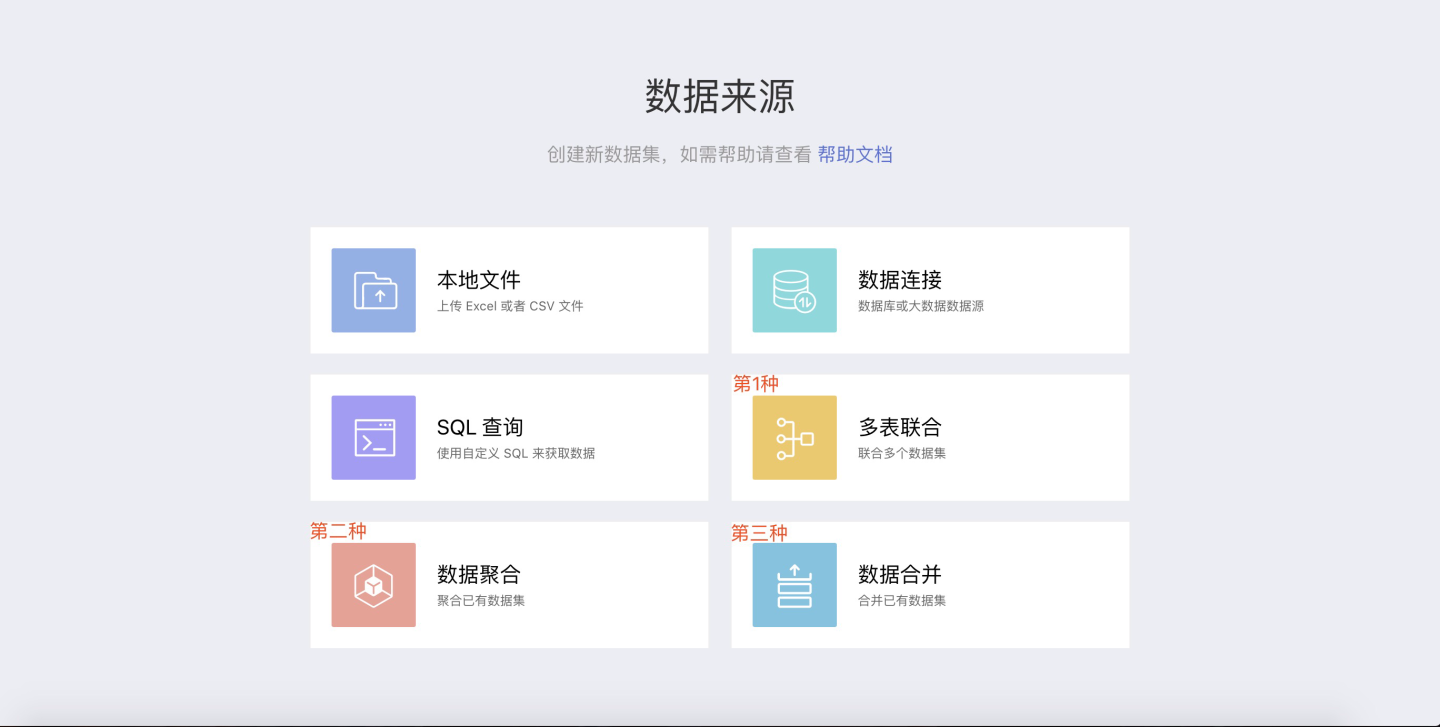
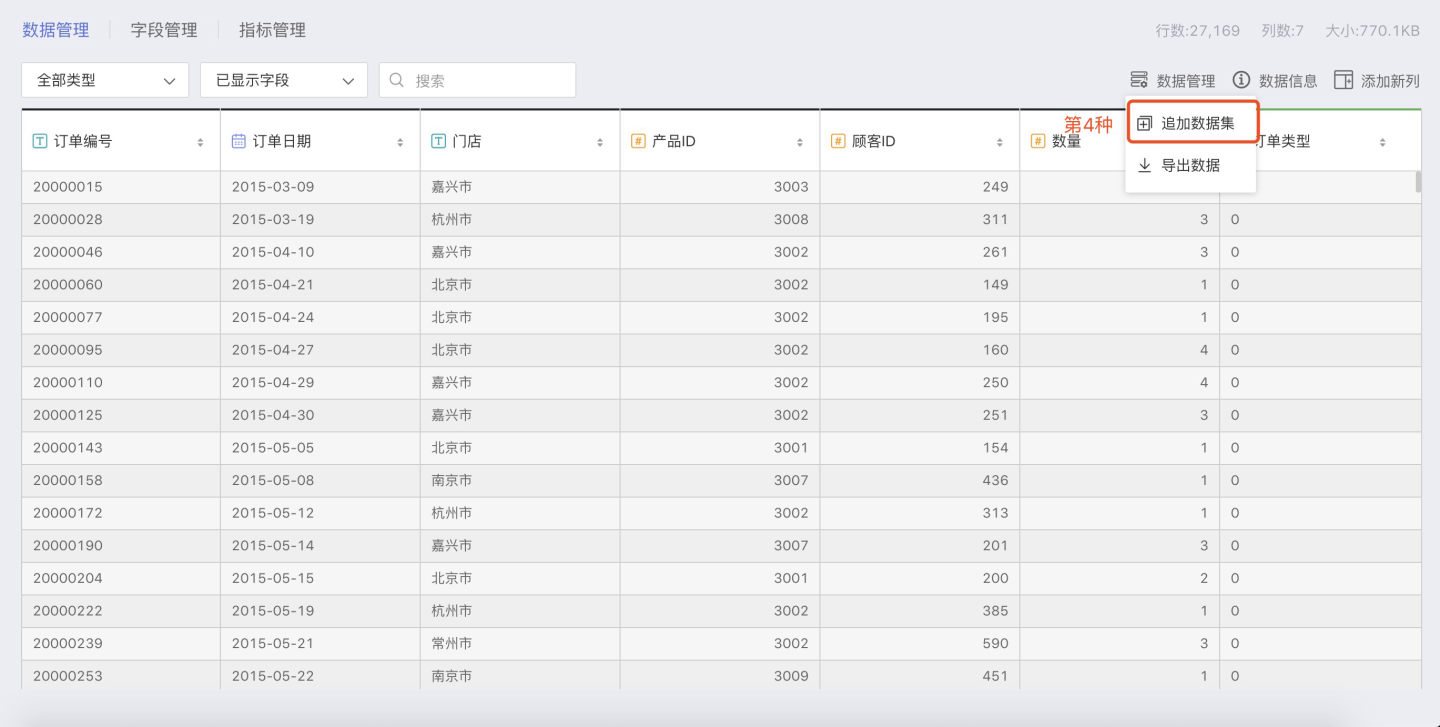
Multi-Table Union
The SENSE system provides a powerful FUSION feature, which allows multiple datasets to be combined into a single wide table by mapping specific fields between them.
Data Aggregation
Based on the already created datasets, new datasets can be created through data aggregation, selecting only the fields of interest from the original dataset, suitable for "data analysis" on datasets with many columns.
Data Merging
When it is necessary to consolidate data from multiple datasets into one dataset, the data merging function can be used. Data merging generates a new dataset.
Data Appending
When it is necessary to consolidate data from multiple datasets into one dataset, the data appending function can be used. Data appending directly modifies the base dataset without generating a new dataset.
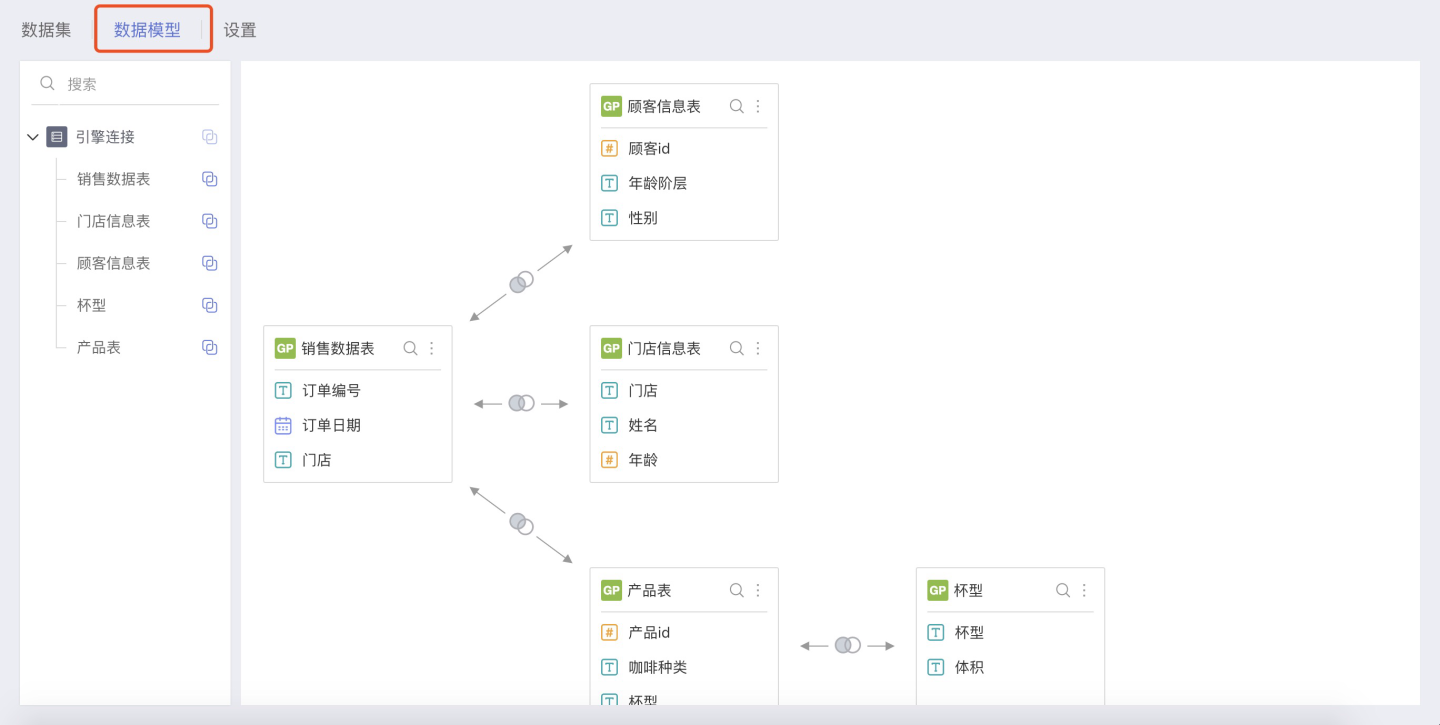
Data Model
The data model, also known as the association analysis model, provides significant freedom and agility for data analysis compared to creating a dataset for each type of association analysis. It allows for the immediate editing of model relationships, which can immediately affect analysis results. For details, see Data Model.
Data Processing within Dataset
Field Management
Field management is a major part of data preprocessing, including: modifying field aliases, batch modifying field names, changing field types and formats, and setting whether to display.
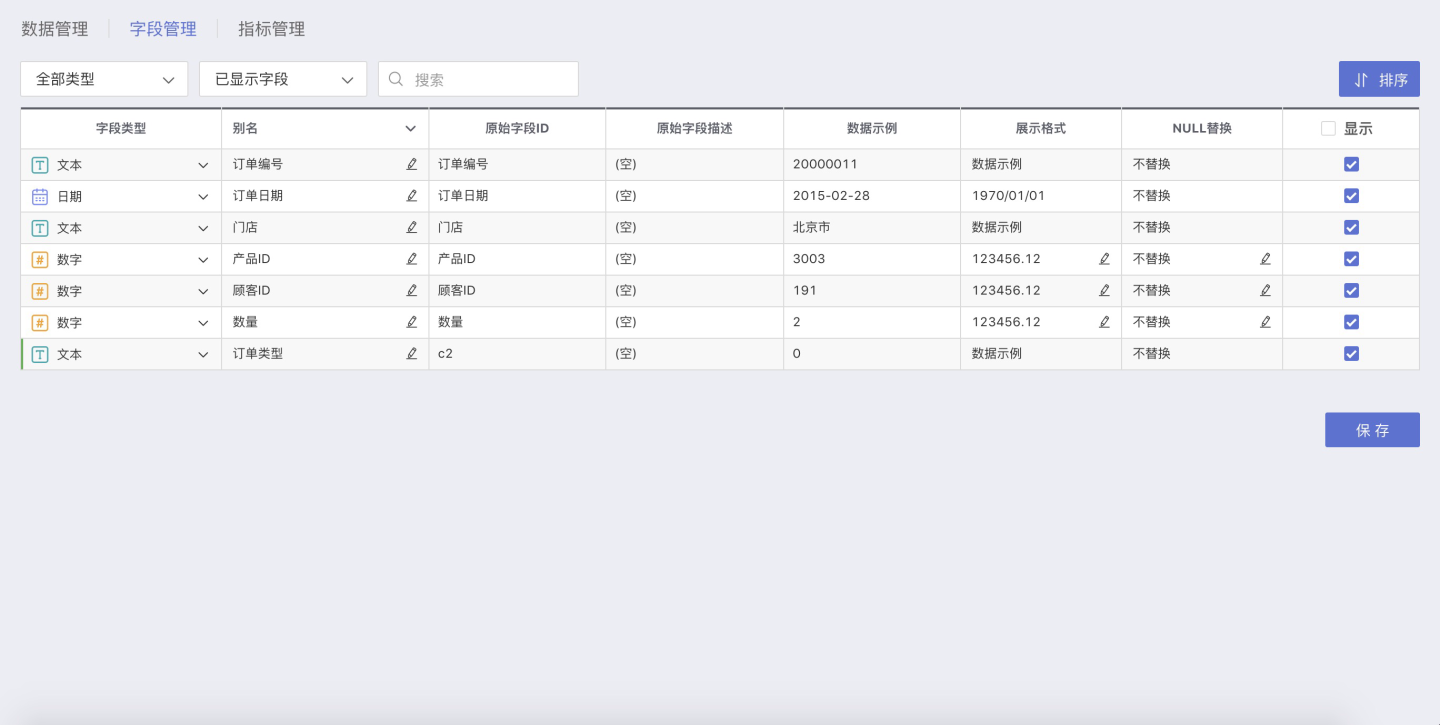
Adding New Columns
Adding new columns involves processing the existing fields in the dataset to ultimately obtain new fields.
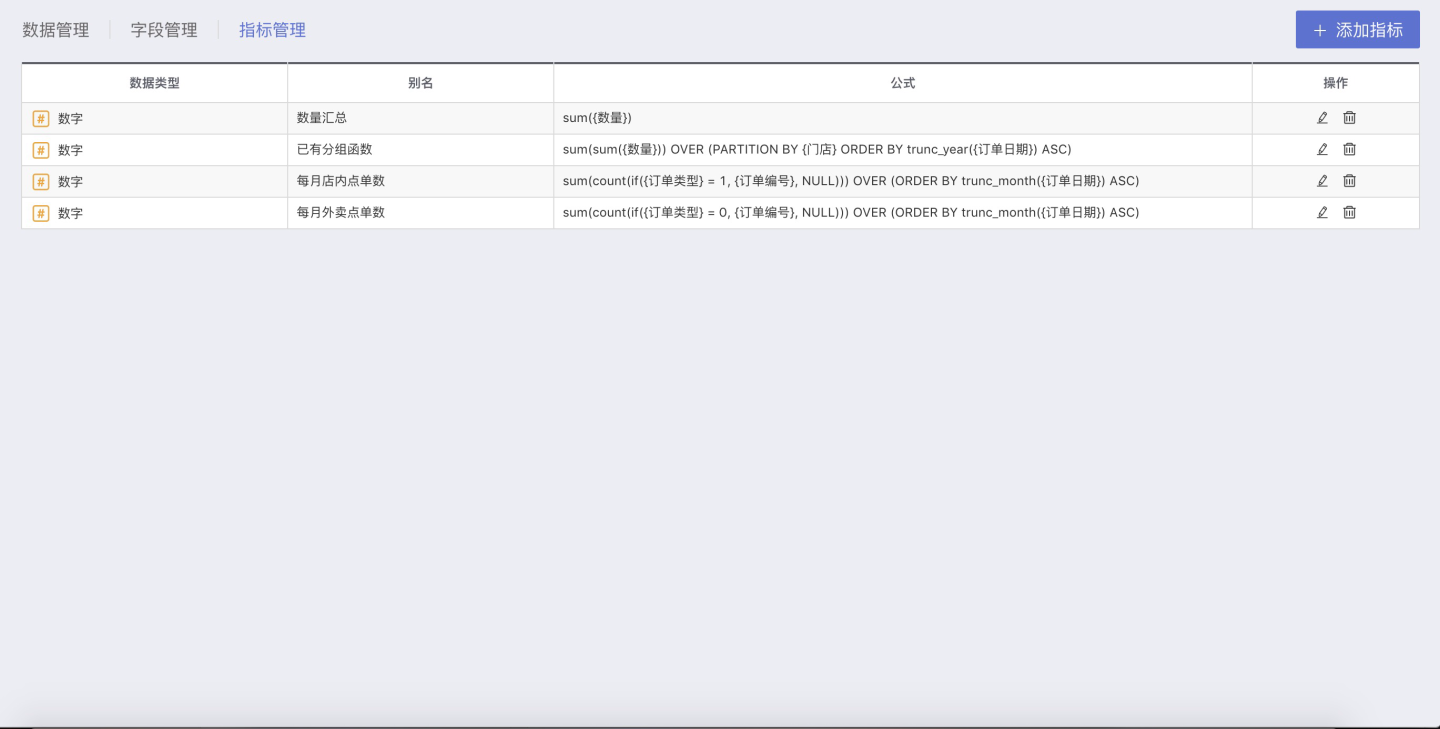
Indicator Management System
After completing data processing, HENGSHI SENSE 3.0 supports unified calculated fields, calculated indicator management, and indicator management. Indicator management involves defining aggregated indicators in the dataset used for data visualization, ensuring that all users use the same set of indicators when visualizing with this dataset, thus avoiding inconsistencies in concepts.
For example: The indicator Sales Volume is defined in indicator management using the formula sum({Sales Performance}*{Sales Quantity}), ensuring that everyone has a consistent concept of the "Sales Volume" indicator, avoiding inconsistencies in data due to different calculation methods with the same name.
Therefore, indicator management helps achieve consistent statistical logic for key KPIs within the enterprise, ensuring uniform algorithms across departments, and saying goodbye to data inconsistencies.
At this point, all operations in the Dataset Market are complete, and data analysis users can use the datasets in the Dataset Market for data visualization in the App Creation area.
In the above permission management, users added under any module (Manager, Editor, Viewer) can see the folder when creating a chart. After clicking "New," expand the data source selection area by clicking the expand box on the left side of the chart type selection.
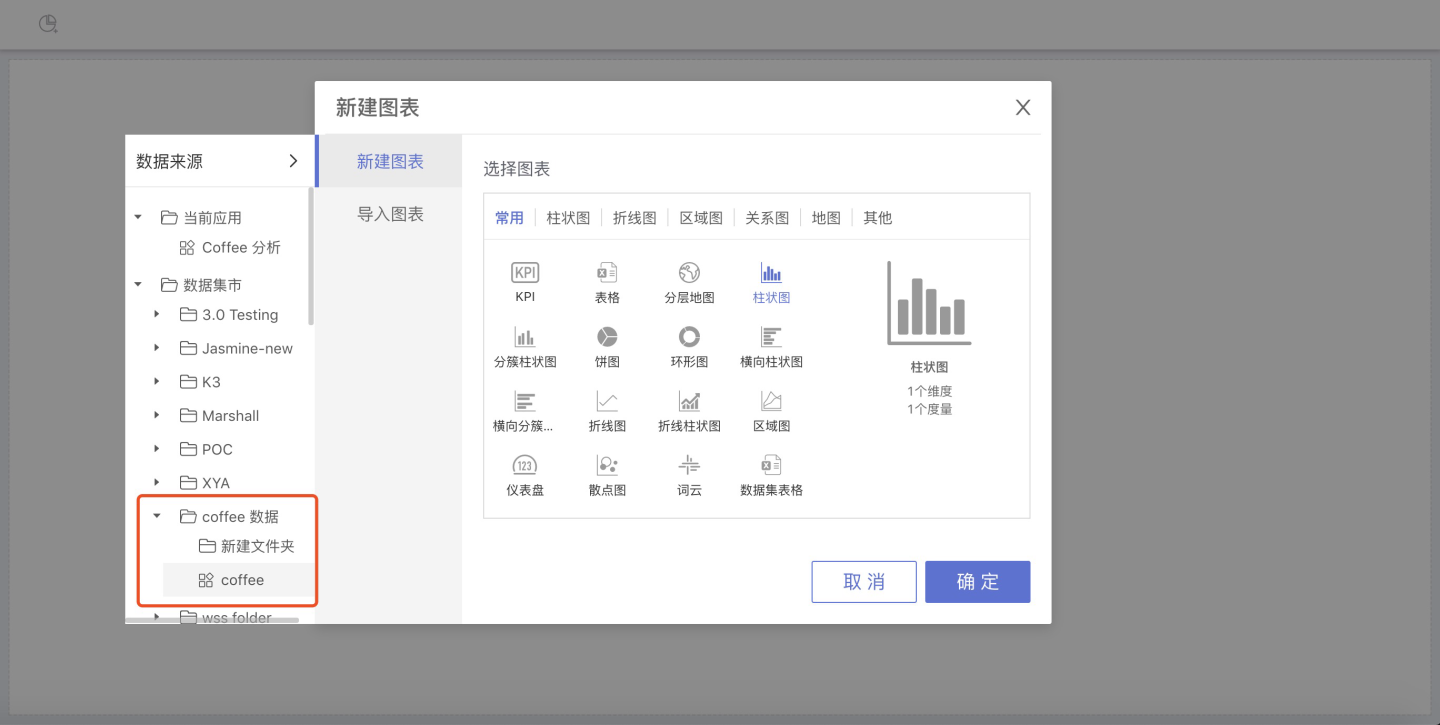
Please note
The data package in the folder must be selected;
When creating a chart, you first need to select the data package.