Acceleration Engine
The system is equipped with a high-speed MPP engine, capable of ad-hoc analysis on data sets with hundreds of millions of records. It can also unify and model heterogeneous data, then perform associated computations.
When the acceleration engine is enabled for a data set, the data from the data set is imported into the engine. Queries on the data set will then directly access the engine table.
Tip
Currently, large-scale imports into the engine are not recommended for big data sources such as Hive, Spark, Impala, Presto, and Max Compute. The import process for large data sets does not support streaming replication and may consume a significant amount of memory, potentially causing the system to freeze. Allowing these data sources to enable the engine is for the convenience of importing small tables, not for large-scale imports, which is not the best practice. It is recommended to use these data sources directly, as our support for direct connections is now comparable to that of the engine.
Enabling the Acceleration Engine
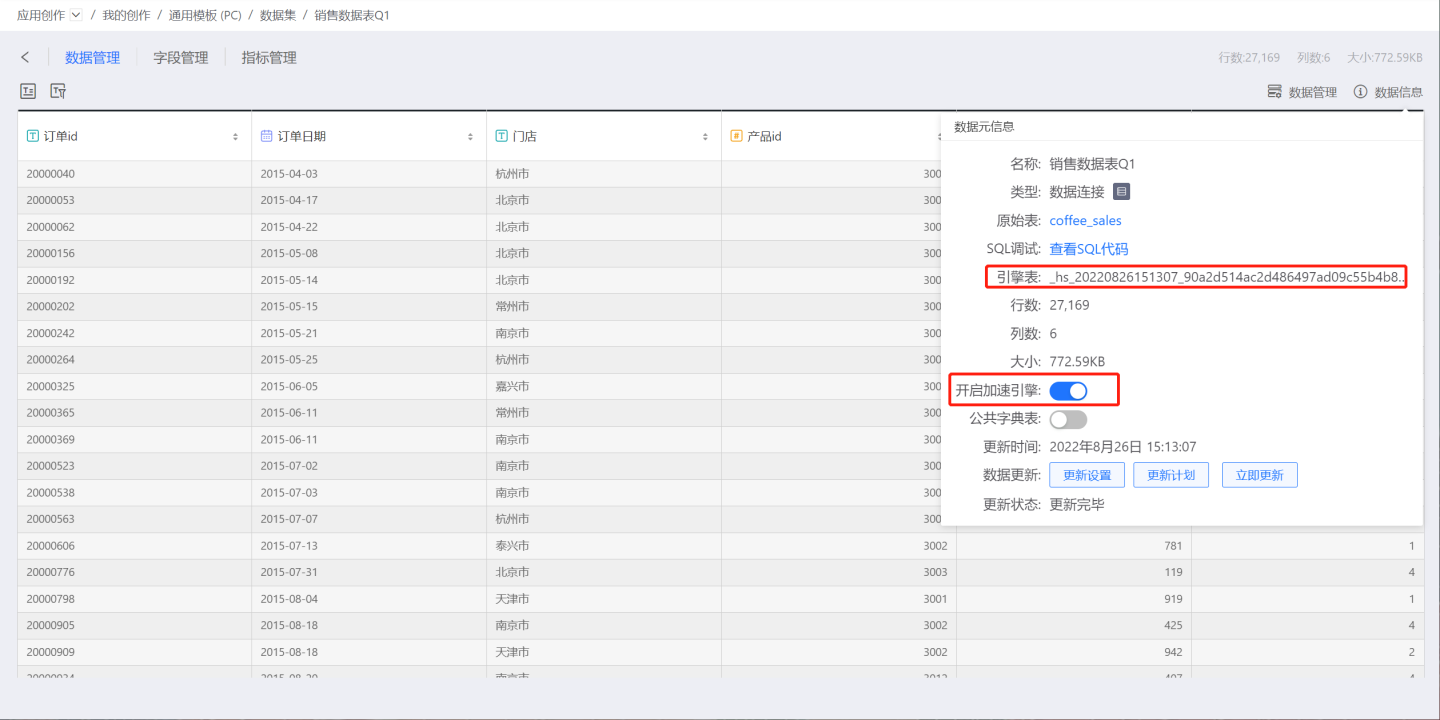
Click on the Data Source Information menu to open the Data Source Information window. Toggle on Enable Acceleration Engine, and the system will prompt "Please wait, data extraction in progress...". At this point, the system will extract the data set into the engine.
After completion, the Engine Table name will be displayed in the metadata, as shown below:
Tip
Enabling the acceleration engine is not supported when the data set size exceeds the system's configured Data Set Cache Size.
Disabling the Acceleration Engine
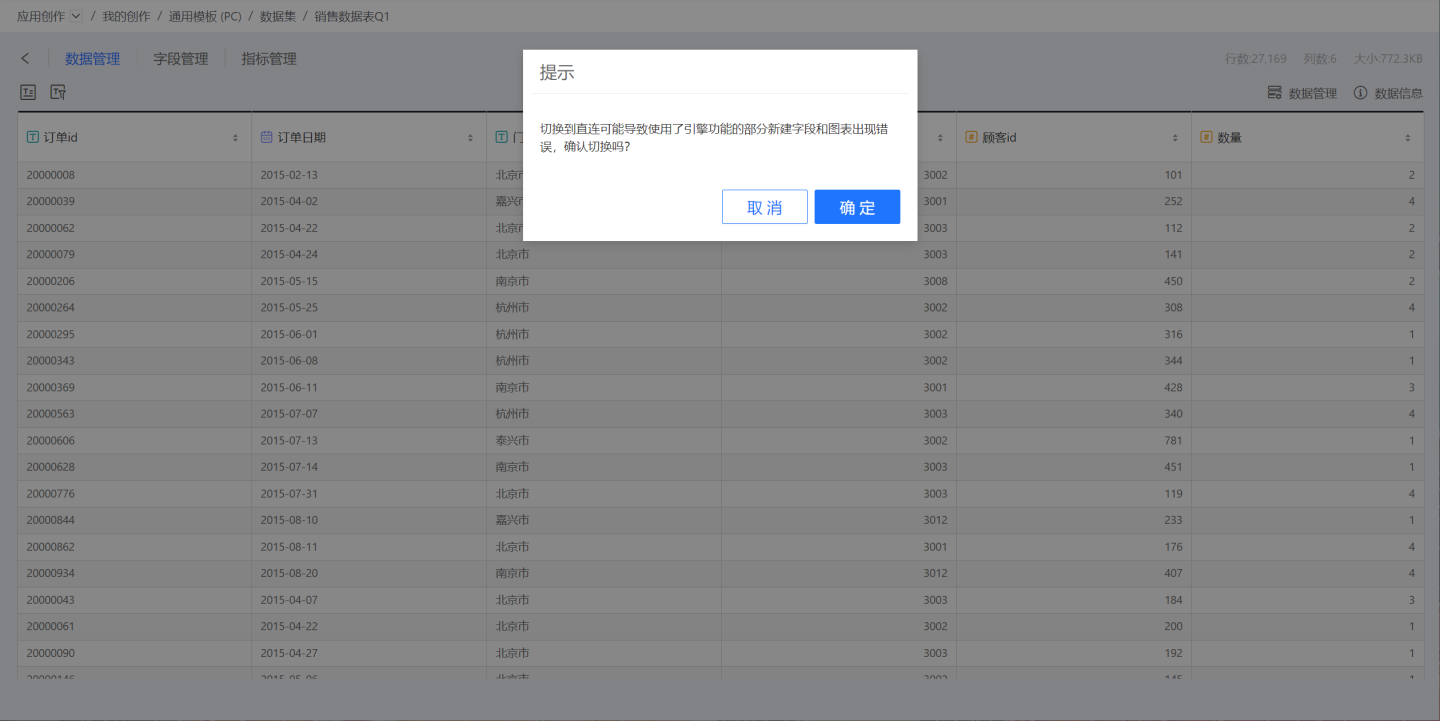
In the Data Source Information window, toggle off Enable Acceleration Engine. After disabling the acceleration engine, the data set will revert to the original direct connection mode. At this point, if new fields use functions supported by the engine but not by the original database, the data set will fail to load. If new metrics use functions supported by the engine but not by the original data, charts using these metrics will error. Therefore, the system will pop up a confirmation window, as shown below. Clicking confirm will disable the acceleration engine:
Note
The acceleration engine cannot be disabled if the application has been published.
Update Schedule
In the Update Schedule, you can set the synchronization frequency between the engine table and the original data set table.
For details, see Update Schedule.
Features Supported Only When the Acceleration Engine is Enabled
- Append Dataset
- Union Dataset
- Multi-table Fusion of Heterogeneous Datasets
- Advanced Calculation: Window functions are not supported in Mysql 5 and below, Tidb, so advanced calculations are not supported. Importing into the engine is required for support.
- Unsupported Functions in Direct Connection Datasets: All functions listed in the engine support documentation are supported. Functions not supported by other data sources require importing into the engine for support.
Types of Acceleration Engines and Related Data Sources
The system supports using built-in engines and external engines.
- The built-in engine is the system's own acceleration engine, including three types: Greenplum, StarRocks, and Apache Doris, with Greenplum being the default. Users can change the type of built-in engine during system installation.
- The external engine is the user's own data source used as an acceleration engine. Currently, data sources that support enabling the acceleration engine include: MySQL, PostgreSQL, Greenplum, Oracle, SQL Server, Spark SQL, TiDB, Amazon Redshift, MaxCompute PostgreSQL, DB2, Hive, Cloudera Impala, Presto, MongoDB, HBase, ClickHouse.
ClickHouse Materialized Views
When the system's acceleration engine is ClickHouse, Multi-table Fusion Datasets can use ClickHouse materialized views when imported into the engine. This materialized view can update the dataset in real-time without the need for a refresh schedule, improving the query performance of associated data.
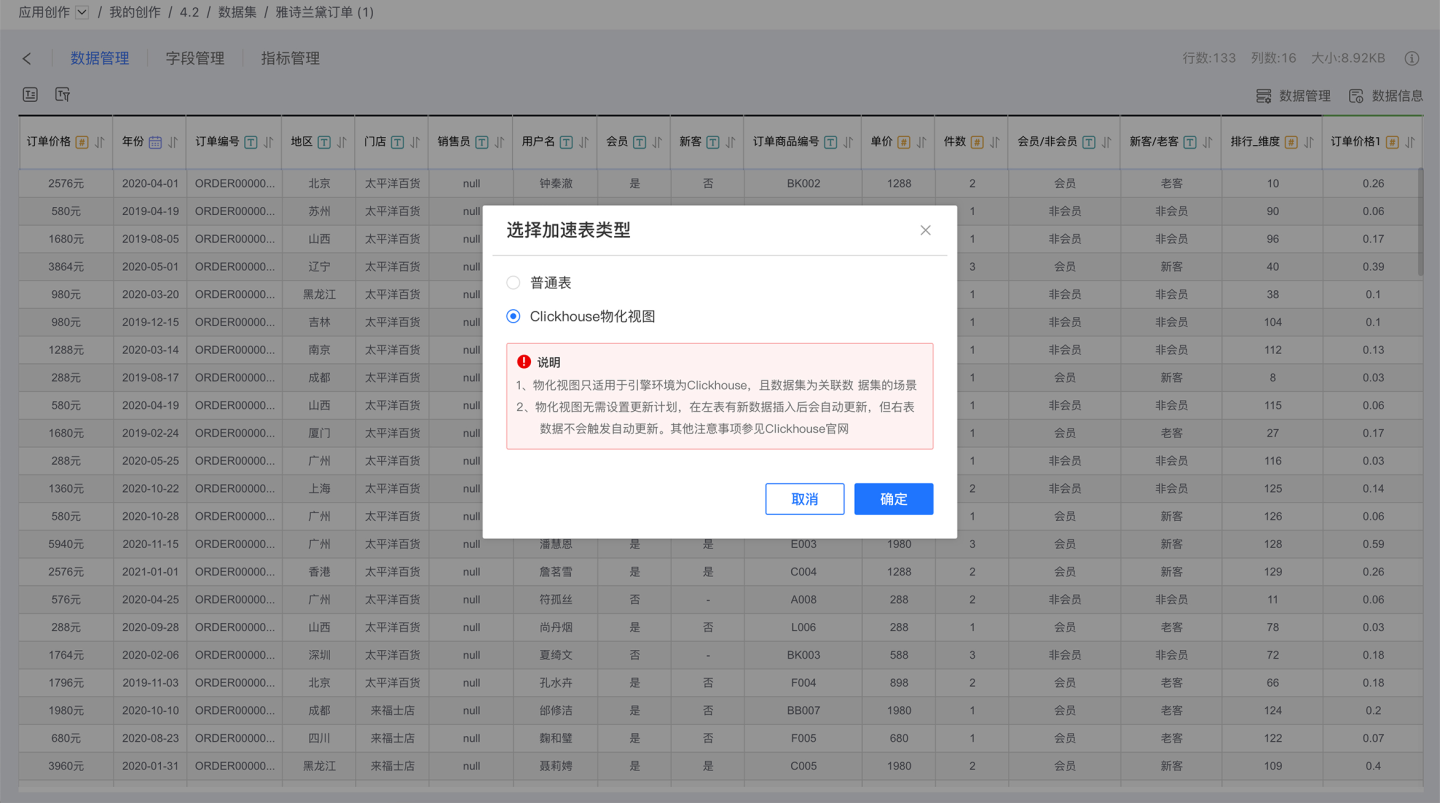
Using ClickHouse materialized views requires that the data source of the multi-table fusion dataset must be ClickHouse and must be in the same cluster as the engine. Due to the implementation mechanism of ClickHouse, the view is only triggered and data is updated when the left table is updated. For more details, please refer to the ClickHouse official documentation.