AI 助手
HENGSHI SENSE 在去分析功能中提供了 AI 助手,用户可以通过问答就能获取到相关数据及图表。在使用前,需要先进行相关配置。
如下图所示,需要系统管理员在设置->功能配置->AI 助手页面进行配置。
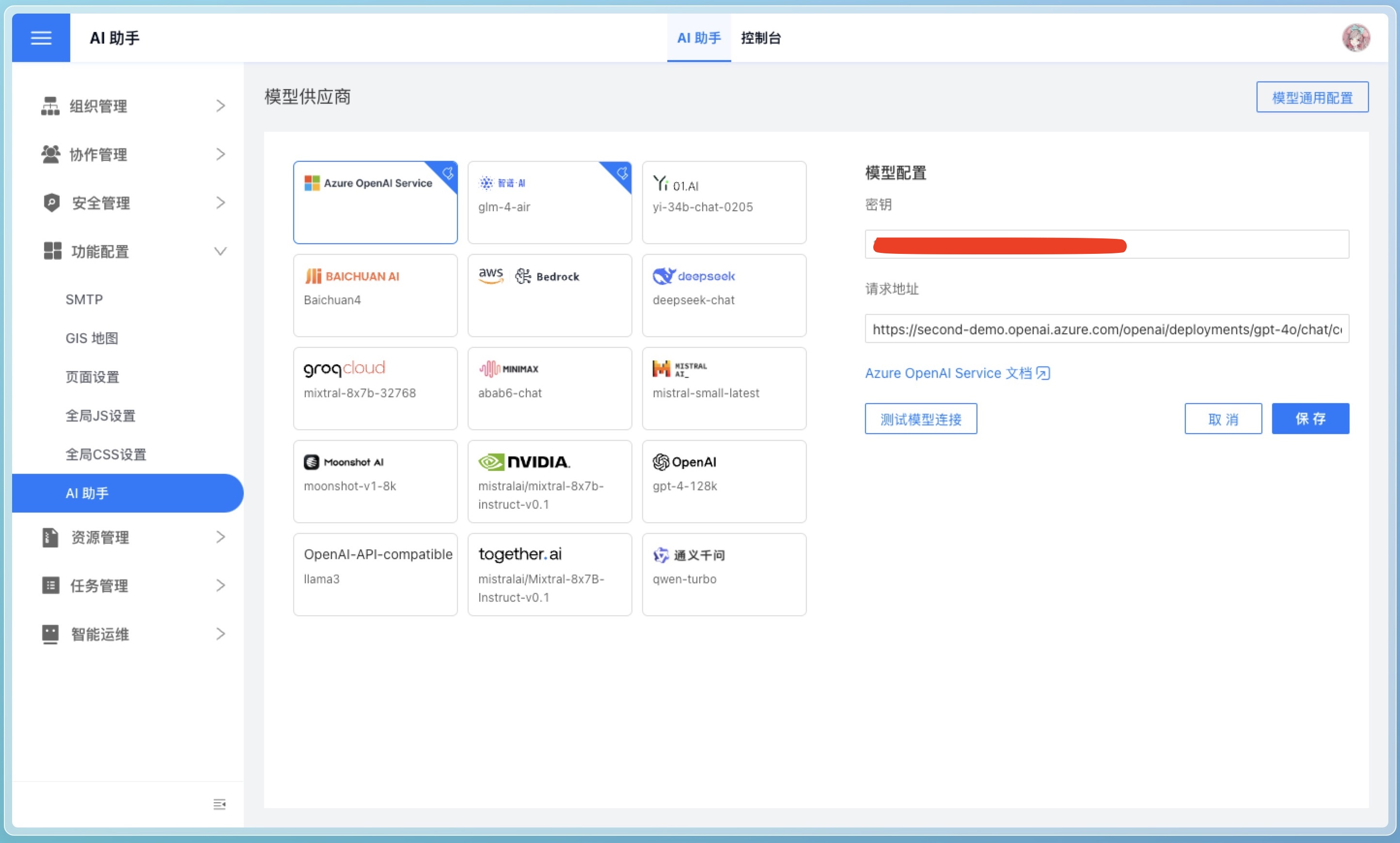
模型供应商
HENGSHI SENSE 不提供 AI 助手模型,需要用户自行向模型供应商申请。我们推荐使用 Azure OpenAI Service、 智谱 AI。
目前 AI 助手支持以下模型供应商:
注意
模型供应商的 API Key 需要用户自行申请,并妥善保管。
其他供应商
在页面中您还能看到我们对下列模型供应商做了支持,但我们目前无法保证这些模型的效果:
注意
大模型使用效果受模型供应商影响,HENGSHI SENSE 无法保证所有模型的效果。如果发现效果不佳,请及时联系 support@hengshi.com 或模型供应商。
OpenAI-API-Compatible
如果需要使用以上列表之外的模型,请选择 OpenAI-API-Compatible 选项,只要是兼容 OpenAI API 格式的模型都可以使用。
以 豆包 AI 为例,可以进行如下配置:
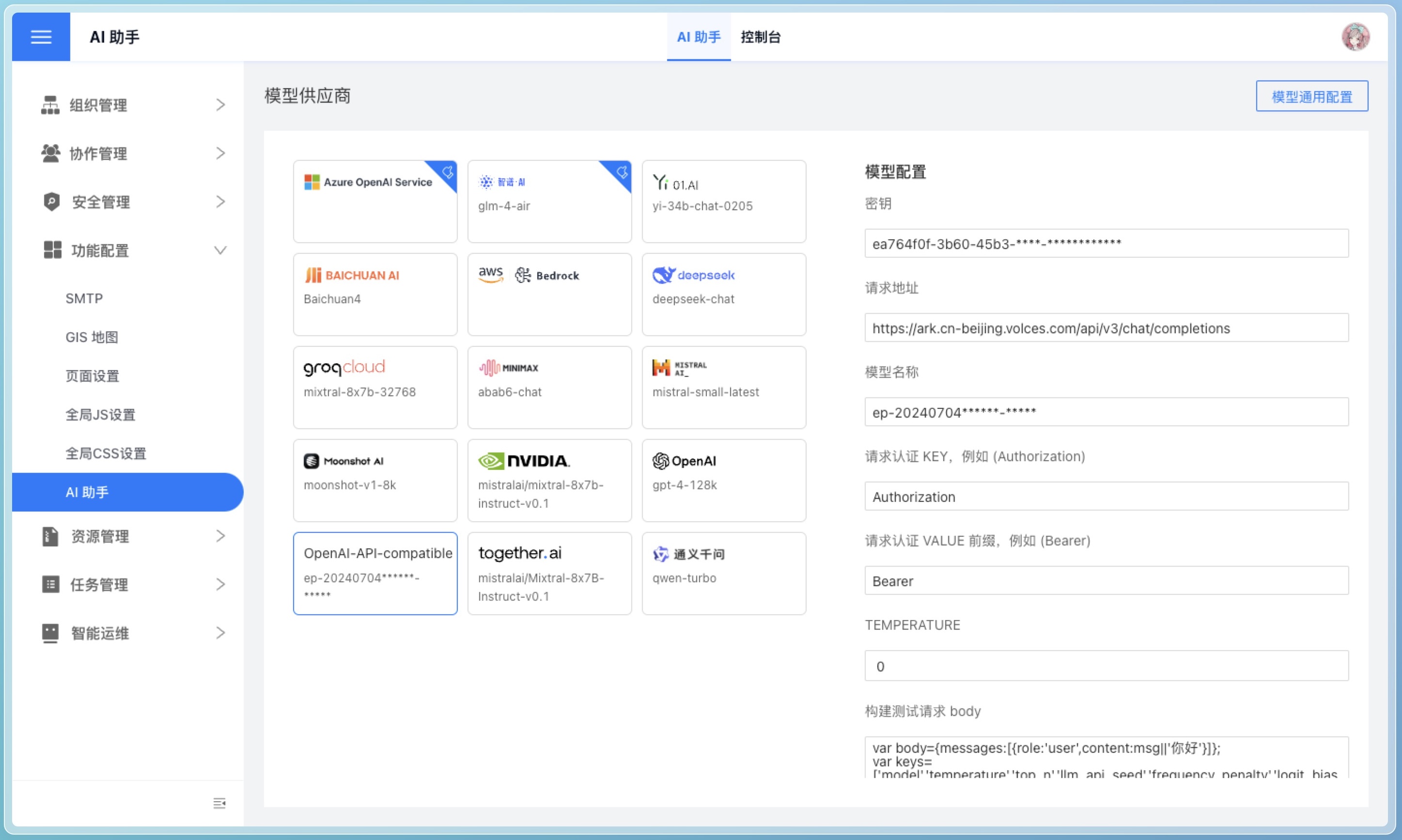
测试模型连接
在配置好模型的 API Key 后,点击 测试模型连接 按钮,可以测试模型连接是否正常。如下图所示,如果连接正常,会显示出模型接口的返回内容。

注意
该测试仅由前端发送请求,可能会存在跨域问题导致请求失败,但不会影响模型的使用。
模型通用配置
下列配置项为 AI 助手系统级配置,不区分模型供应商。
LLM_ANALYZE_RAW_DATA
在页面配置中是 允许模型分析原始数据。作用是设置 AI 助手是否分析原始输入数据。若您的数据比较敏感,可以关掉此配置。
LLM_ANALYZE_RAW_DATA_LIMIT
在页面配置中是 允许分析的原始数据数量(行)。作用是设置分析原始数据的数量限制。依据模型供应商的处理能力、tokens 限制量、具体需求来设置。
LLM_ENABLE_SEED
在页面配置中是 使用 seed 参数。作用是控制是否在生成回复时启用随机种子,以带来结果的多样性。
LLM_API_SEED
在页面配置中是 seed 参数。作用是在生成回复时使用的随机种子数字。配合LLM_ENABLE_SEED使用,可由用户随机指定或保持默认。
LLM_SUGGEST_QUESTION_LOCALLY
在页面配置中是 不使用模型生成推荐问题。作用是指定是否在生成推荐问题时使用大模型。
- true 本地规则生成
- false 大模型生成
LLM_SELECT_ALL_FIELDS_THRESHOLD
在页面配置中是 允许模型分析元信息 (阈值)。作用是此参数设置选择所有字段的阈值。LLM_SELECT_FIELDS_SHORTCUT为 true 此参数才有作用,酌情设定。
LLM_SELECT_FIELDS_SHORTCUT
此参数设置是否在字段比较少的时候不挑选字段,直接选择所有字段参与生成 HQL。配合LLM_SELECT_ALL_FIELDS_THRESHOLD使用,依据具体操作场景确定此配置。一般不需要设置为 true。对速度特别敏感或者想省掉字段选择步骤时可以关掉此配置。但是不选择字段会影响最终数据查询的正确性。
LLM_API_SLEEP_INTERVAL
在页面配置中是 API 调用间隔 (秒)。作用是设定 API 请求之间的休眠间隔,以秒为单位。根据请求频率需求设定。对于需要限制频率的大模型 API 可以考虑设置。
HISTORY_LIMIT
在页面配置中是 连续对话上下文条数。作用是与大模型交互时携带的历史对话条目数量。
LLM_ENABLE_DRIVER
在页面配置中是 使用模型推理意图。作用是是否开启 AI 判断禁用问题,并根据上下文优化问题功能。上下文范围由HISTORY_LIMIT确定。一般需要上下文引用和有禁用问题需求才需要开启。
MAX_ITERATIONS
在页面配置中是 模型推理迭代上限。作用是最大迭代次数,用于控制处理大模型失败循环的次数。
LLM_API_REQUIRE_JSON_RESP
确定 API 响应格式是否必须为 JSON,该配置项只有 OpenAI 支持,一般情况不需要改这个配置。
LLM_HQL_USE_MULTI_STEPS
是否通过多个步骤来优化趋势,同环比类型的问题的指令遵循程度,酌情设定,多个步骤会相对慢一些。
VECTOR_SEARCH_FIELD_VALUE_NUM_LIMIT
分词搜索数据集字段 distinct value 个数的上限,distinct value 匹配过多的部分将不会提取,酌情设定。
CHAT_BEGIN_WITH_SUGGEST_QUESTION
在去分析跳转后,是否会给用户提供几个推荐问题。根据需要开启。
CHAT_END_WITH_SUGGEST_QUESTION
每个问题回合回答后,是否会给用户提供几个推荐问题。根据需要开启。关闭可以节省一部分时间。
向量库配置
ENABLE_VECTOR
启用向量搜索功能。AI助手通过大模型 API 来挑选跟问题最相关的例子。开启向量搜索后,AI助手会综合大模型 API 和向量搜索的结果。
VECTOR_MODEL
向量化模型,基于是否需要向量搜索能力来设置。需要跟VECTOR_ENDPOINT 配合使用。系统自带的向量服务上已经包含的模型是intfloat/multilingual-e5-base。这个模型不需要下载。如果需要其他模型,目前支持选择在huggingface上面的向量模型。需要注意的是,向量服务必须能够保证可以连通huggingface官网,不然模型下载会失败。
VECTOR_ENDPOINT
向量化 API 地址,基于是否需要向量搜索能力来设置。安装好向量数据库相关服务后,默认指向自带的向量服务。
VECTOR_SEARCH_RELATIVE_FUNCTIONS
是否搜索问题相关的函数说明。开启后会搜索问题相关的函数说明,相应的,提示词会变大。这个开关只有在ENABLE_VECTOR开启的情况下才生效。
向量库详细配置见: AI 配置