Multi-Table Joint Dataset
A multi-table joint dataset refers to combining multiple datasets to generate a new dataset.
Create Multi-Table Union Dataset
Follow the steps below to create a multi-table union dataset.
Create a new dataset.
Go to the dataset page, click "New Dataset," and select Multi-Table Union.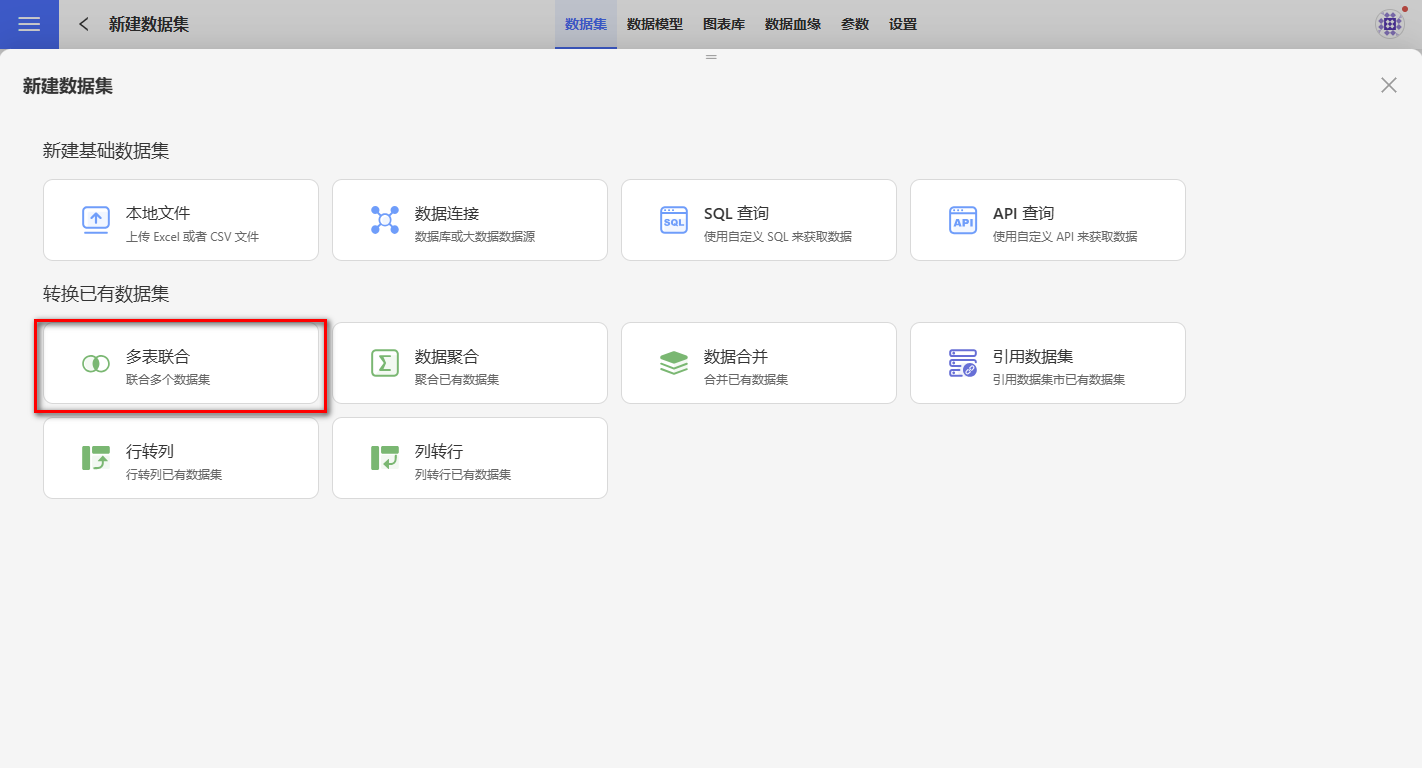
Establish relationships between datasets.
Drag the dataset table columns from the left side to the editing area on the right side of the page. Select the join fields and join mode to establish relationships between datasets. Datasets can be joined using multiple fields. Supported join modes include left join, right join, inner join, and full join. Click "Preview Data" to confirm the results.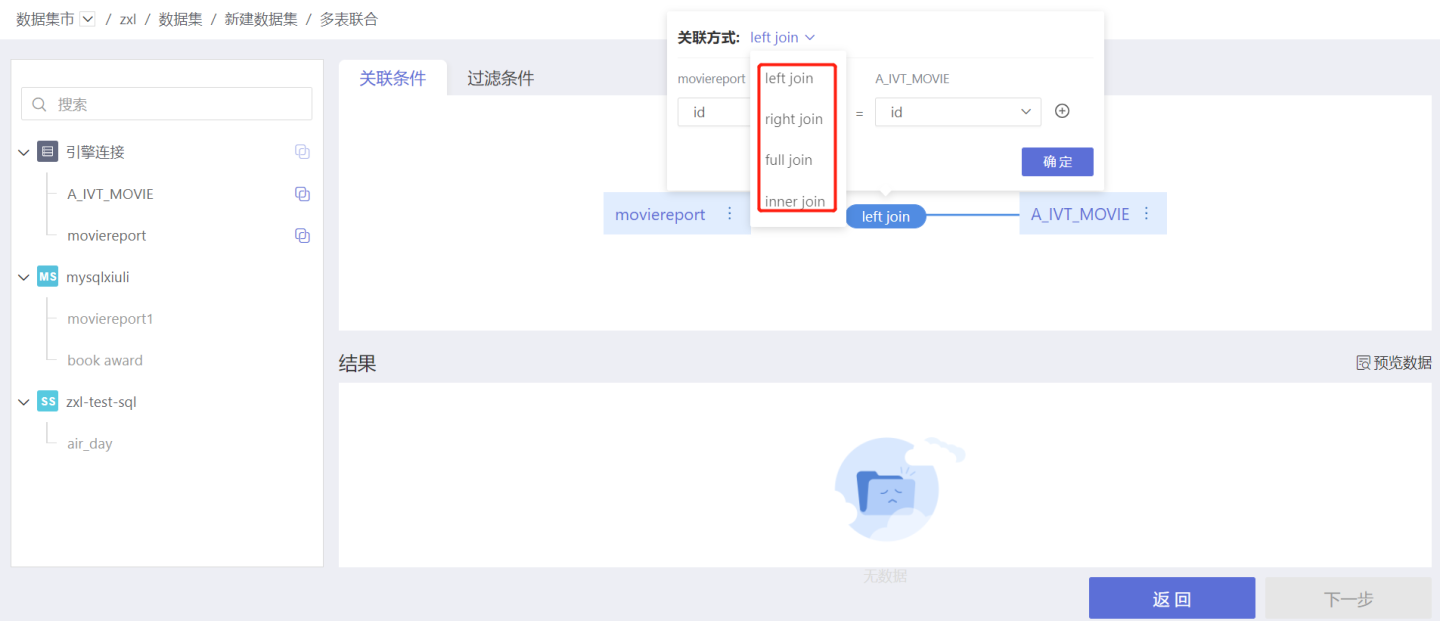
Tips
- Only datasets from the same source support multi-table union. To perform multi-table union on datasets from different sources, you need to enable the Acceleration Engine and perform the union within the engine.
- The supported join modes are consistent with the join types supported by the dataset's data source. Data sources such as MySQL, Amazon Aurora, MemSQL, TiDB, and MongoDB support three join modes: left join, right join, and inner join. Other data sources support four join modes: left join, right join, inner join, and full join.
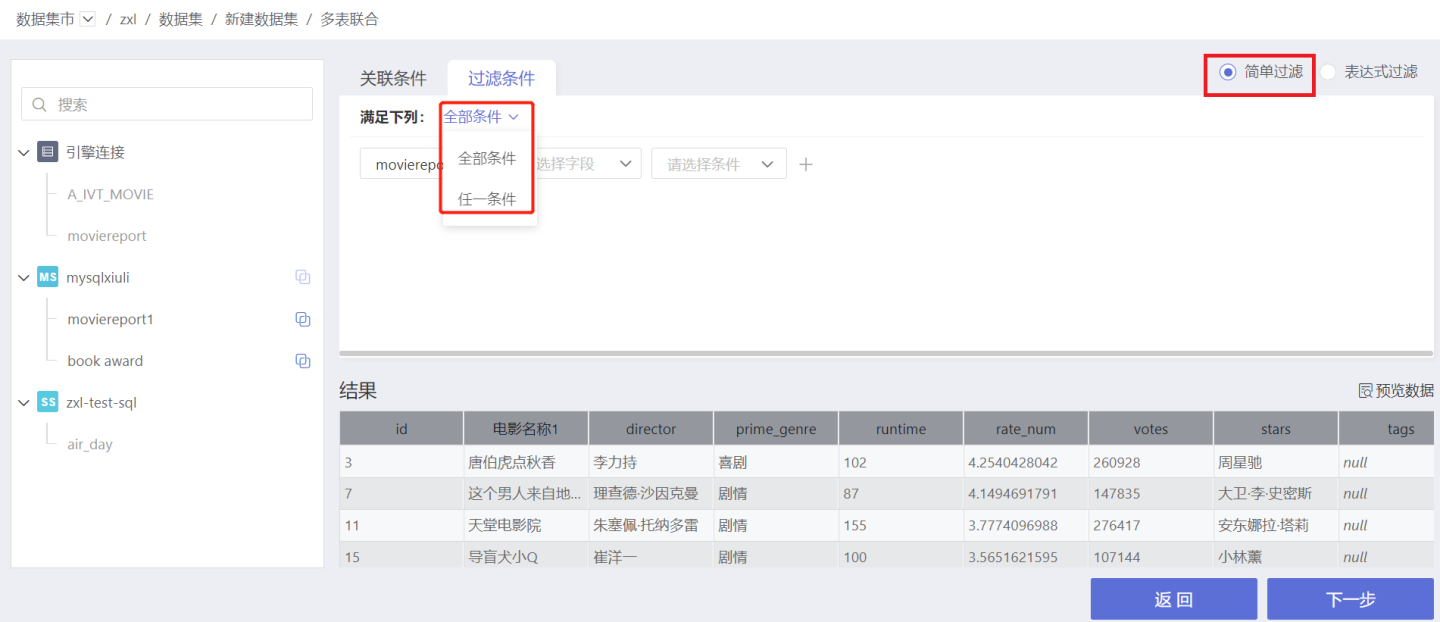
Set filter conditions to refine the data. Supports simple filtering and expression filtering.
- Simple Filtering: Users can set filter conditions through options. When there are multiple filter conditions, you can choose the condition selection mode: "All Conditions" or "Any Condition." "All Conditions" means the filtered data must meet all filter conditions. "Any Condition" means the filtered data only needs to meet one of the conditions.
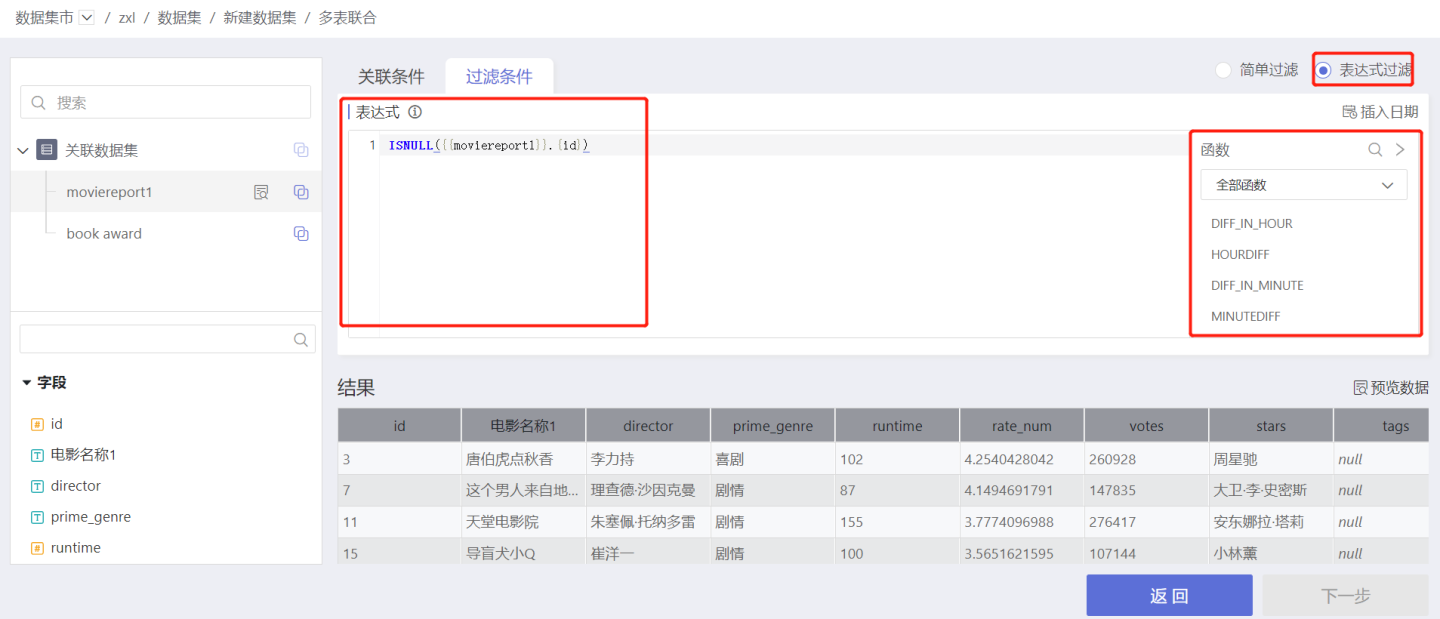
- Expression Filtering: Users can set filter conditions through expressions for more flexible data refinement. Filter expressions must return a Boolean value. On the right side of the expression editing area is a list of functions available for use in expressions.
Configure the data structure of the multi-table union dataset. Set fields to display or hide, and configure field aliases.
The data structure of the multi-table union displays the source dataset for each field. Click "All Fields" on the right side of the interface to view duplicate fields and the number of fields in the generated dataset. Click on a field to view duplicate fields.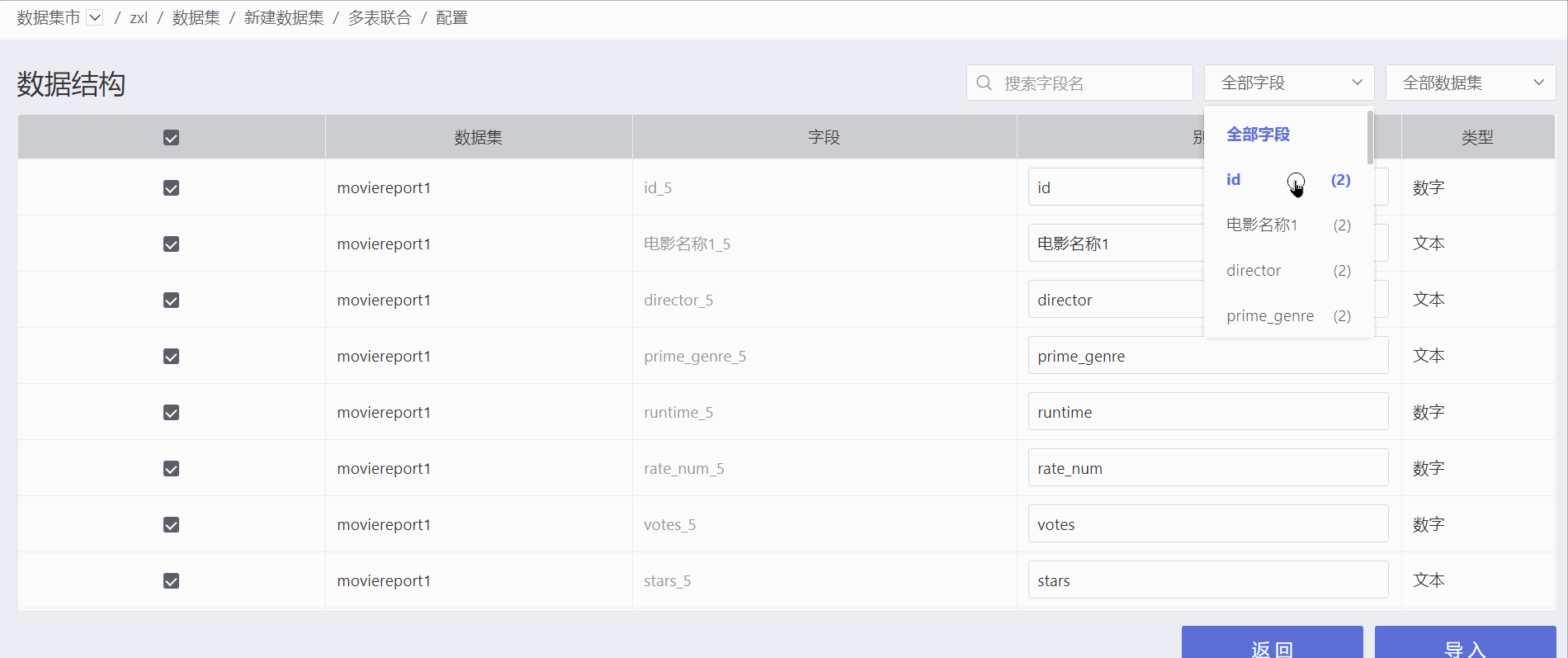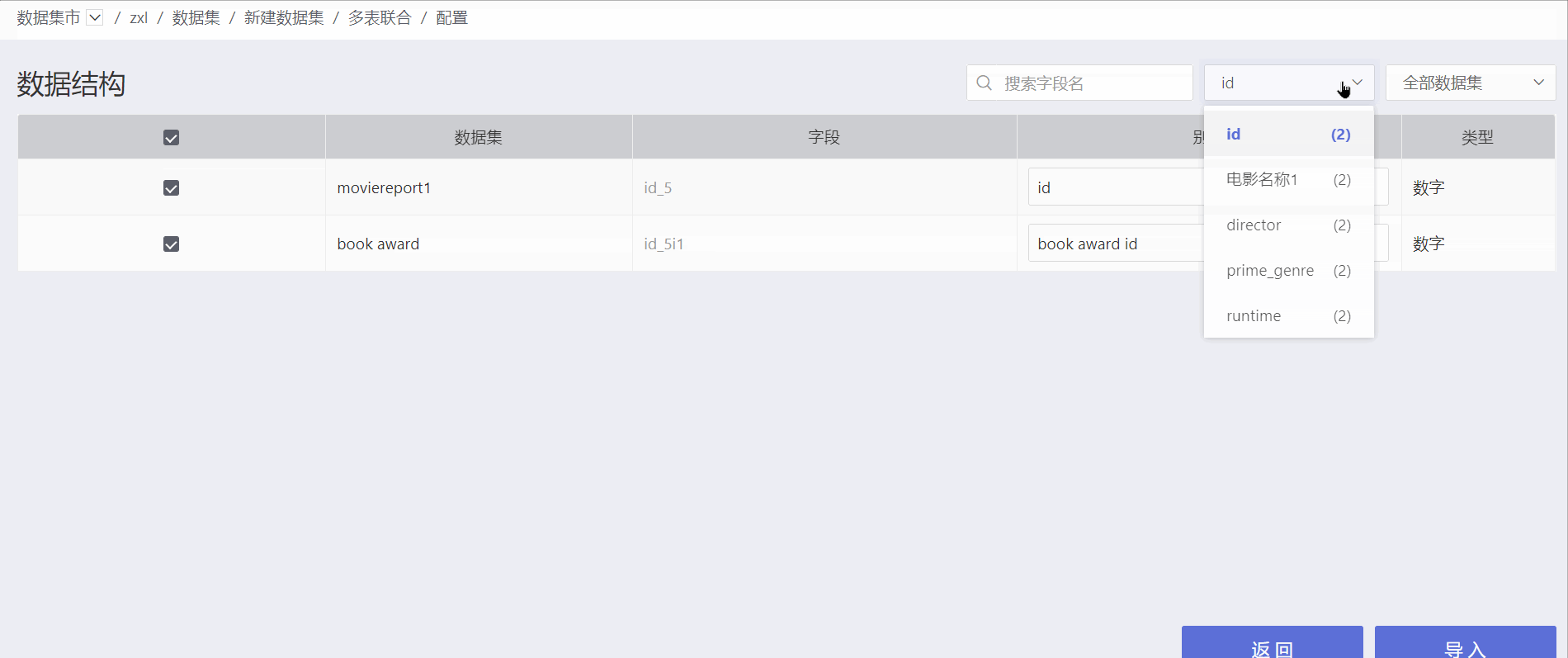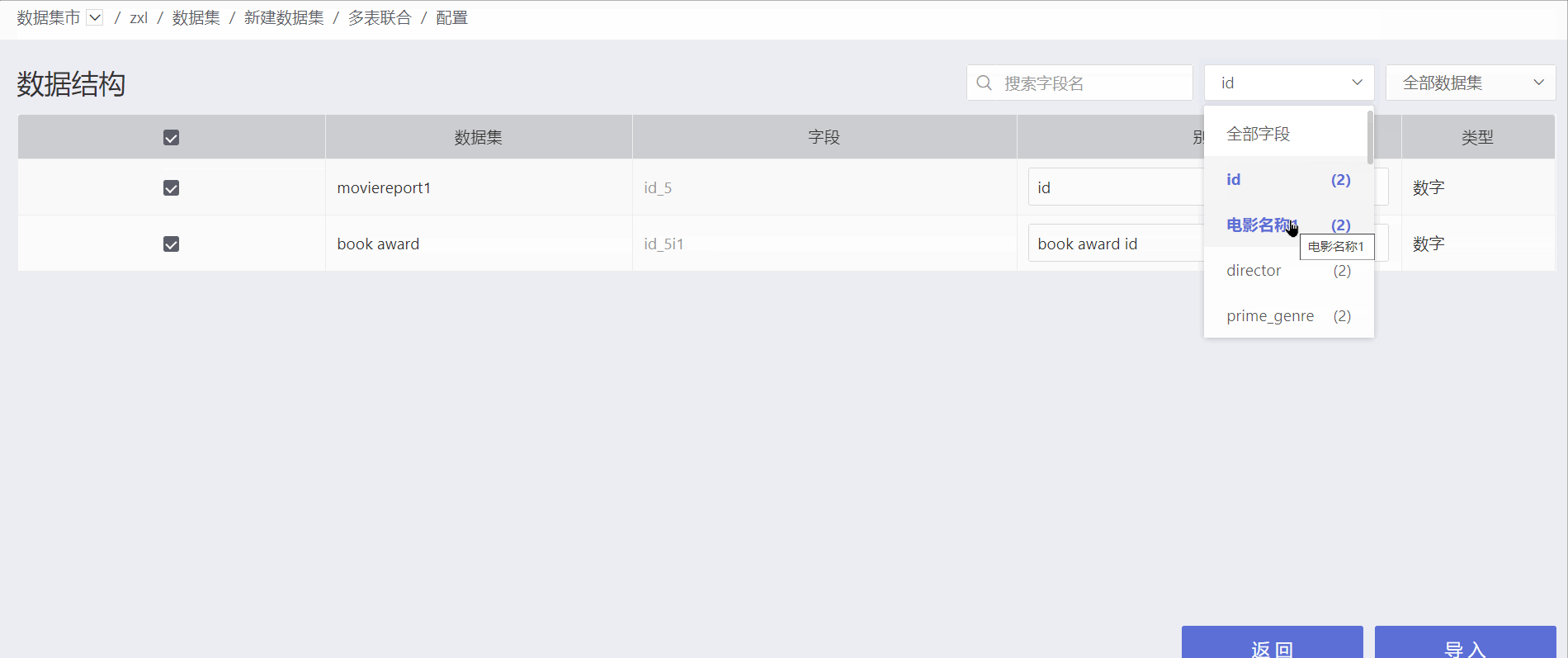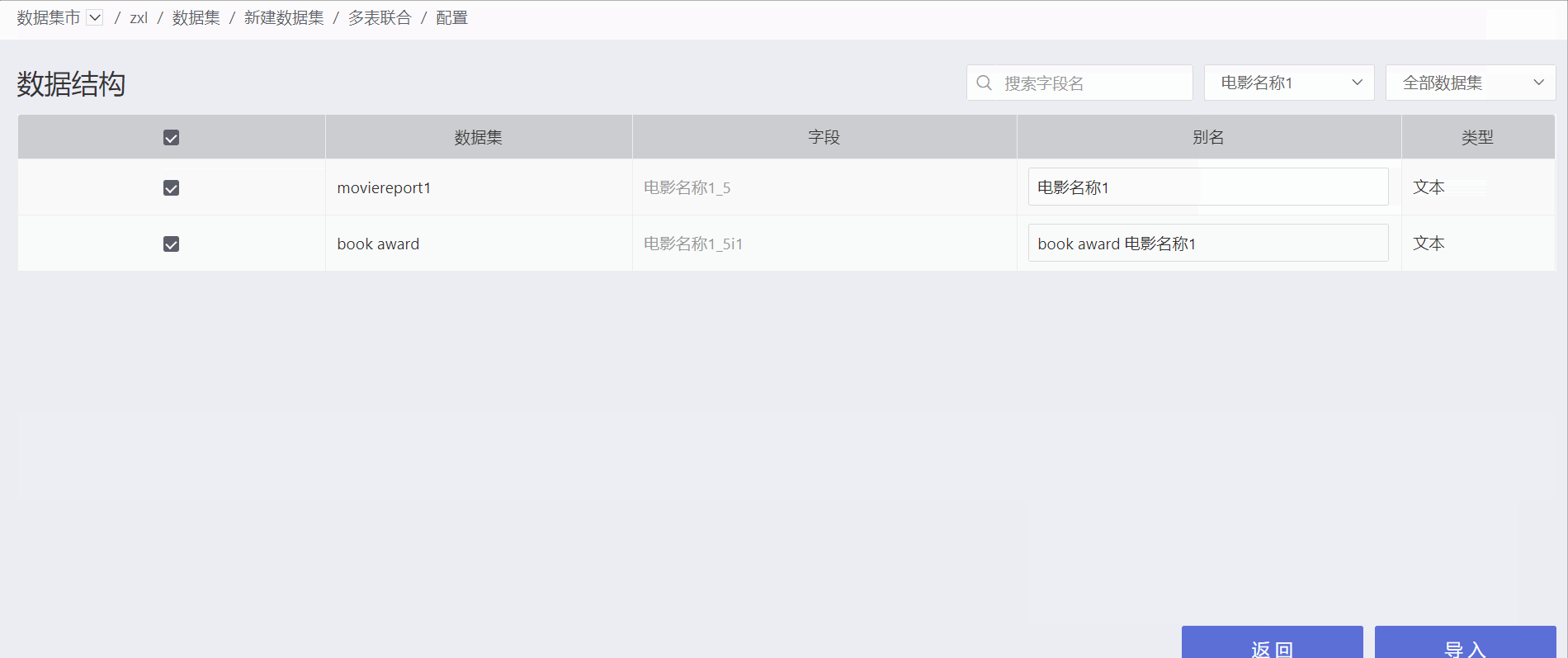
Import the data to complete the dataset creation.
Dataset Reuse
Multi-table join allows the same dataset to be dragged into the canvas multiple times, as shown in the figure below. It supports modifying the dataset name in the canvas, and after saving, the name in the canvas does not change with the dataset's name.
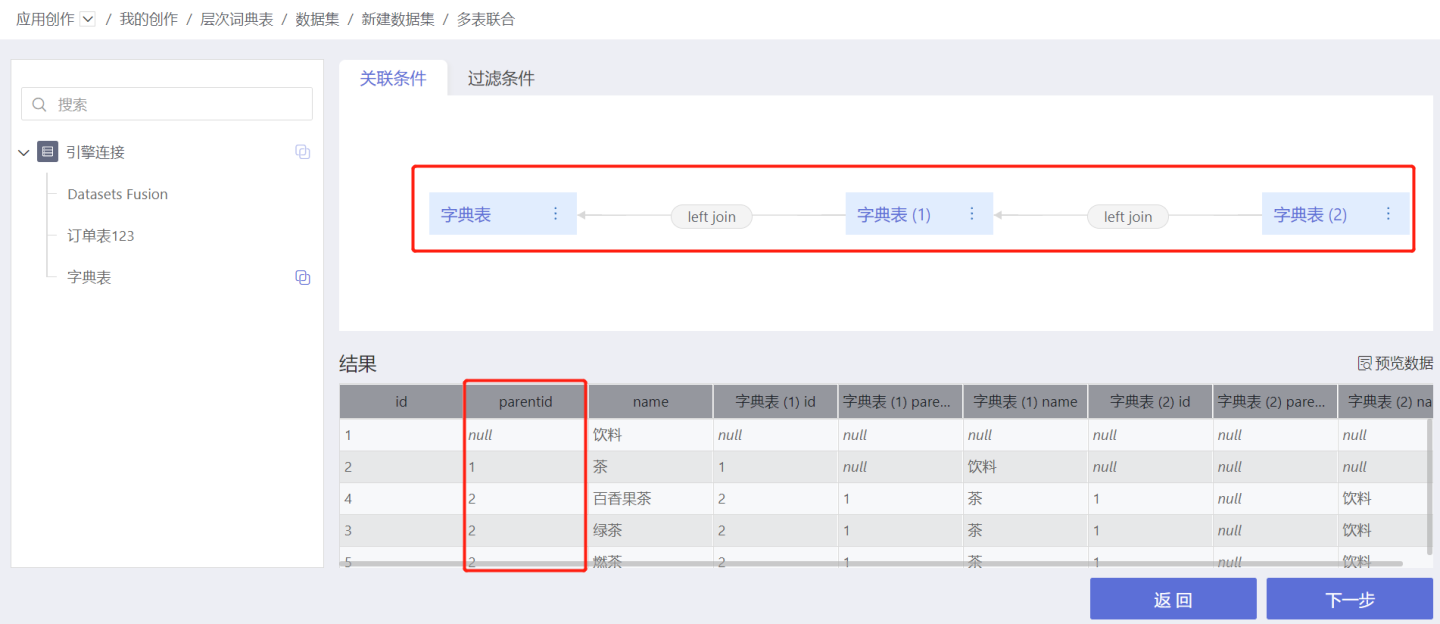
Dataset reuse solves the problem of associating hierarchical dimension tables with themselves multiple times, eliminating the need to duplicate datasets, thus making user operations more convenient.
Relevant Instructions
- After enabling the Public Dictionary feature for a dataset, it cannot be used as the base table for multi-table joins, i.e., the first table dragged into the editing area.
- Multi-table joins are only supported for datasets from the same source. If you need to perform multi-table joins on datasets from different sources, you must enable the acceleration engine for the datasets and perform the joins within the engine.