Connecting to Spark SQL
Operation Steps
Please follow the steps below to connect to a Spark SQL data source.
On the data connection page, click "New Data Connection" in the upper right corner.
In the data source types, select the
Spark SQLdata source.
Fill in the required parameters for the data source connection as prompted.
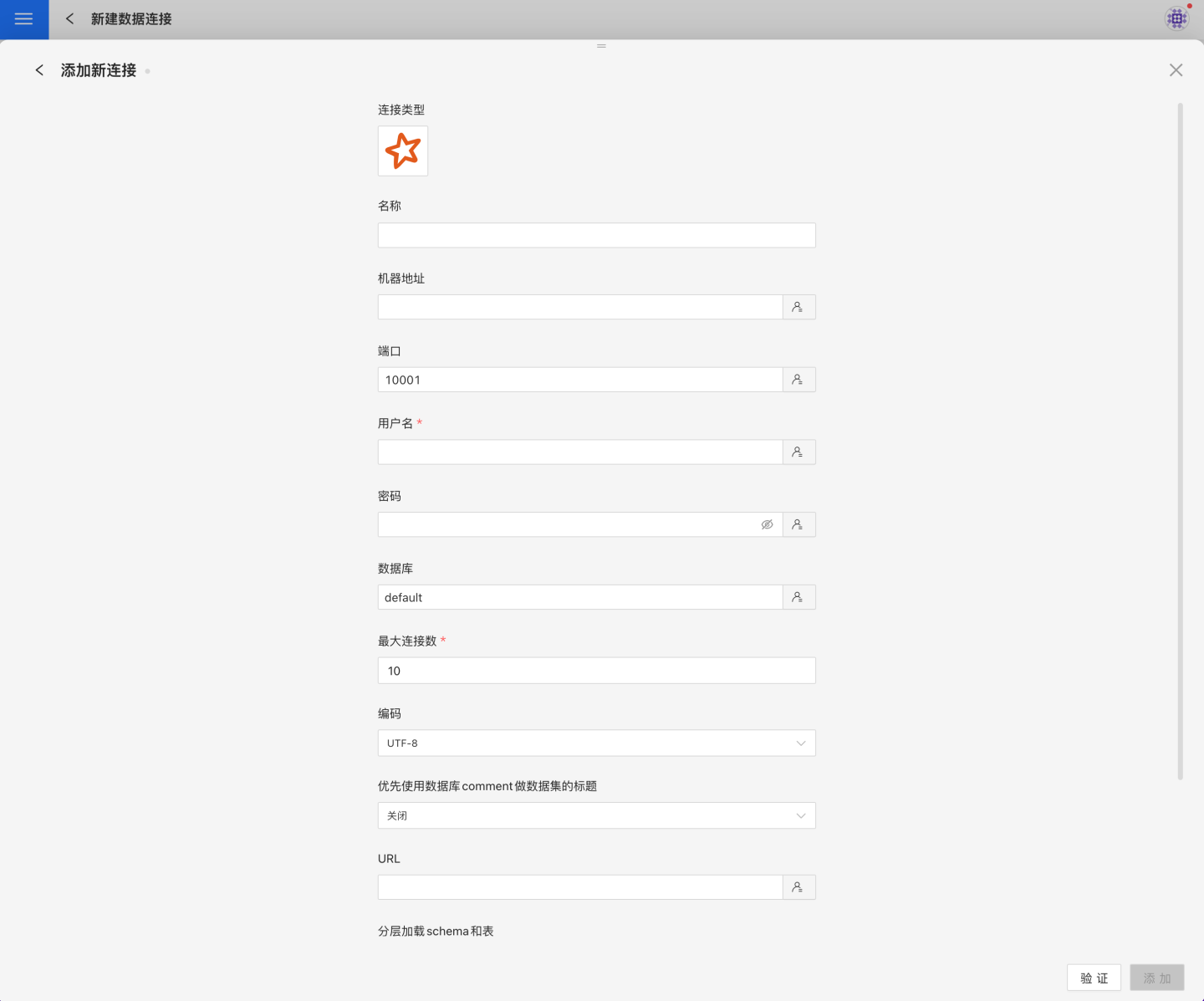
Connection Configuration Information Description
Field Description Name The name of the connection. Required and unique within the user. Host Address The address of the database. If the URL field is filled, the URL takes precedence. Port The port of the database. If the URL field is filled, the URL takes precedence. Username The username for the database. Password The password for the database. Database The name of the database. Max Connections The maximum number of connections in the connection pool. Encoding The encoding setting for the database connection. Prefer using database comment as dataset title Choose whether to display the table name or the table comment. When enabled, the title is shown; when disabled, the table comment is shown. URL The JDBC URL of the database. Hierarchical loading of schema and tables Disabled by default. When enabled, schemas and tables are loaded hierarchically. Only schemas are loaded during connection, and you need to click the schema to load the tables under it. Query Timeout (seconds) Default is 600. For large data volumes, you can increase the timeout as needed. Show only tables under the specified database/schema When this option is selected and the database field is not empty, only tables under the specified database are shown. After filling in the parameters, click the
Validatebutton to get the validation result (this checks the connectivity between HENGSHI SENSE and the configured data connection; you cannot add the connection if validation fails).After validation passes, click
Execute Preset Codeto pop up the preset code for this data source, then click the execute button.Click the
Addbutton to add theSpark SQLconnection.
Please Note
- Parameters marked with * are required; others are optional.
- When connecting to a data source, you must execute the preset code. Failure to do so will result in certain functions being unavailable during data analysis. In addition, when upgrading from a version prior to 4.4 to 4.4, you need to execute the preset code for existing data connections in the system.
Supported Spark SQL Versions
2.3.0 and above
Data Connection Preview Support
Supports all tables that can be listed by show tables.
SQL Dataset Support for SQL
Only SELECT statements are supported, along with all SELECT-related features supported by the connected Spark instance. Users need to ensure that the syntax complies with the Spark SQL standard.
Supported Authentication Methods for Connecting to Spark Thrift Server
Supports username and password authentication; SSL is not supported.
Unsupported Field Types
The following data types in Spark cannot be processed correctly:
- BINARY
- arrays
- maps
- structs
- union