关联关系描述
本文基于“咖啡店业务场景”,解释关联关系的描述,下面两张表是涉及到的数据集。
数据集1:咖啡豆库存表 (coffee_beans)
| bean_id | bean_name | stock_kg |
|---|---|---|
| 1 | 哥伦比亚 | 50 |
| 2 | 埃塞俄比亚 | 30 |
| 3 | 巴西 | 20 |
数据集2:咖啡销售表 (sales)
| sale_id | bean_id | sale_kg |
|---|---|---|
| 101 | 1 | 10 |
| 102 | 2 | 5 |
| 103 | 4 | 8 |
关联类型
关联类型指的是数据集关联时的连接类型,支持左连接(LEFT JOIN)、内连接(INNER JOIN)、右连接(RIGHT JOIN)、全连接(FULL JOIN)。
左连接(LEFT JOIN)
保留左侧数据集所有记录,右侧未匹配的显示NULL。上述两个数据集的左连接结果是:所有咖啡豆库存 + 匹配的销售记录(库存未售出则显示 NULL)。 左连接结果:
| bean_id | bean_name | stock_kg | sale_id | bean_id | sale_kg |
|---|---|---|---|---|---|
| 1 | 哥伦比亚 | 50 | 101 | 1 | 10 |
| 2 | 埃塞俄比亚 | 30 | 102 | 2 | 5 |
| 3 | 巴西 | 20 | NULL | NULL | NULL |
内连接(INNER JOIN)
保留两边数据集同时存在的记录。上述两个数据集的内连接结果是:仅保留有库存且售出的咖啡豆。 内连接结果:
| bean_id | bean_name | stock_kg | sale_id | bean_id | sale_kg |
|---|---|---|---|---|---|
| 1 | 哥伦比亚 | 50 | 101 | 1 | 10 |
| 2 | 埃塞俄比亚 | 30 | 102 | 2 | 5 |
右连接(RIGHT JOIN)
保留右侧数据集所有记录,左侧未匹配的显示 NULL。上述两个数据集的右连接结果是:所有销售记录 + 匹配的库存(销售未进货则显示 NULL)。 右连接结果:
| bean_id | bean_name | stock_kg | sale_id | bean_id | sale_kg |
|---|---|---|---|---|---|
| 1 | 哥伦比亚 | 50 | 101 | 1 | 10 |
| 2 | 埃塞俄比亚 | 30 | 102 | 2 | 5 |
| NULL | NULL | NULL | 103 | 4 | 8 |
全连接(FULL JOIN)
保留两侧数据集的所有结果,未匹配部分填充 NULL。上述两个数据集的全连接结果是:所有库存和销售记录(未匹配部分填充 NULL)。 全连接结果:
| bean_id | bean_name | stock_kg | sale_id | bean_id | sale_kg |
|---|---|---|---|---|---|
| 1 | 哥伦比亚 | 50 | 101 | 1 | 10 |
| 2 | 埃塞俄比亚 | 30 | 102 | 2 | 5 |
| 3 | 巴西 | 20 | NULL | NULL | NULL |
| NULL | NULL | NULL | 103 | 4 | 8 |
关联条件
关联条件是在关联操作中用于指定数据集之间关系的表达式。通常,关联条件基于数据集中的列,通过比较这些列的值来确定哪些行应该被关联在一起。例如,上述“咖啡店业务场景”的两个数据集,“咖啡豆库存表”包含bean_id列,“咖啡销售表”也包含bean_id列,通过这个共同的bean_id列,就可以建立起两个数据集之间的关联。正确理解和使用关联条件,是模型查询高效的关键。
单列关联
两个数据集的关联条件可以用单列相等来描述。在“咖啡店业务场景”的例子,关联条件可以写成:{{咖啡豆库存表}}.{bean_id}={{咖啡销售表}}.{bean_id}。在衡石的数据模型界面,用户可以在简单条件页面通过选择列的方式配置此关联条件,也可以在表达式条件页面通过写表达式的方式配置此关联条件。
多列关联
两个数据集的关联条件需要用多列相等来描述。例如我们有下面两个数据集咖啡订单表和咖啡库存表。当我们想要查询每个订单中所涉及咖啡的库存状态时,就需要根据咖啡的类型 coffee_type 和烘焙程度 roast_level 这两列进行关联查询。关联条件需要写成:{{coffee_orders}}.{coffee_type} = {{coffee_inventory}}.{coffee_type} AND {{coffee_orders}}.{roast_level} = {{coffee_inventory}}.{roast_level}。在衡石的数据模型界面,用户可以在简单条件页面通过选择列的方式配置此关联条件,也可以在表达式条件页面通过写表达式的方式配置此关联条件。
数据集3:咖啡订单表 (offee_orders)
| coffee_type | roast_level | quantity |
|---|---|---|
| 哥伦比亚 | 中度烘焙 | 5 |
| 埃塞俄比亚 | 浅度烘焙 | 3 |
| 巴西 | 深度烘焙 | 7 |
数据集4:咖啡库存表 (offee_inventory)
| coffee_type | roast_level | available_quantity |
|---|---|---|
| 哥伦比亚 | 中度烘焙 | 32.5 |
| 埃塞俄比亚 | 浅度烘焙 | 18.2 |
| 巴西 | 深度烘焙 | 12.8 |
| 危地马拉 | 中度烘焙 | 9.5 |
根据上述关联条件,选择左连接类型,咖啡订单表左连接咖啡库存表,得到的结果如下:
| coffee_type | roast_level | quantity | available_quantity |
|---|---|---|---|
| 哥伦比亚 | 中度烘焙 | 5 | 32.5 |
| 埃塞俄比亚 | 浅度烘焙 | 3 | 18.2 |
| 巴西 | 深度烘焙 | 7 | 12.8 |
非等值关联
除了使用“等于”进行等值关联外,还可以使用其他比较运算符或者嵌套函数进行非等值关联。我们需要找出符合客户价格接受范围的咖啡产品,需要用到非等值关联,关联条件是:{{coffee_products}}.{price} >= {{customer_preferences}}.{min_price} AND {{coffee_products}}.{price} <= {{customer_preferences}}.{max_price}。在衡石的数据模型界面,用户只能在表达式条件页面通过写表达式的方式配置此关联条件。
数据集5:咖啡产品表 (coffee_products)
| product_id | product_name | price |
|---|---|---|
| CP001 | 哥伦比亚特选 | 58 |
| CP002 | 埃塞俄比亚瑰夏 | 85 |
| CP003 | 巴西黄波旁 | 42 |
数据集6:客户偏好表 (customer_preferences)
| customer_id | min_price | max_price |
|---|---|---|
| CU1001 | 30 | 80 |
| CU1002 | 50 | 120 |
| CU1003 | 20 | 60 |
根据上述关联条件,选择内连接类型,咖啡产品表内连接客户偏好表,得到的结果如下:
| product_id | product_name | price | customer_id | min_price | max_price |
|---|---|---|---|---|---|
| CP001 | 哥伦比亚特选 | 58 | CU1001 | 30 | 80 |
| CP001 | 哥伦比亚特选 | 58 | CU1002 | 50 | 120 |
| CP001 | 哥伦比亚特选 | 58 | CU1003 | 20 | 60 |
| CP002 | 埃塞俄比亚瑰夏 | 85 | CU1002 | 50 | 120 |
| CP003 | 巴西黄波旁 | 42 | CU1001 | 30 | 80 |
| CP003 | 巴西黄波旁 | 42 | CU1003 | 20 | 60 |
关联基数
关联关系的关联基数,反映了 “从” 和 “到” 相关列的数据特征。“一” 侧代表该列的每行都包含唯一值,而 “多” 侧则表示该列的多行可以包含重复值。关联条件是确定基数的关键依据,关联基数类型有一对一、一对多、多对一和多对多四种类型。如果数据集A到数据集B的关系为一对多,那表示数据集B的引入会引起数据集A的数据膨胀。
关联基数的判定方法
简单关联条件下的基数判定
当关联条件为简单条件时,我们可以通过查看相关列的值是否唯一来定义关系基数。以下以 部门人员 表和 人员信息 两个数据集为例进行说明。这两个数据集的关联条件为 {{部门人员}}.{user_id} = {{人员信息}}.{id}。在 部门人员 数据集中,有多行数据包含相同的 “user_id”,这表明 部门人员 数据集应被定义为基数为 “多” 的一侧。在 人员信息 数据集中每行数据的 “id” 都不相同,所以 人员信息 表应被定义为基数为 “一” 的一侧。部门人员和人员信息的关联基数判定为多对一。
数据集7:部门人员(depart_member)
| l1 | l2 | user_id |
|---|---|---|
| 销售 | 销售一部 | 1 |
| 销售 | 销售二部 | 2 |
| 销售 | 销售三部 | 3 |
| 销售 | 市场方向 | 1 |
| 销售 | 大客户方向 | 2 |
| 市场部 | 市场部 | 1 |
数据集8:人员信息(user)
| id | name |
|---|---|
| 1 | jack |
| 2 | tom |
| 3 | amy |
复杂关联条件下的基数判定
当关联条件为复杂条件时,我们可以通过添加虚拟列来辅助判断基数。以 销售订单数 表和 月份信息 两个数据集为例。这两个数据集的关联条件为 trunc_month({{销售订单数}}.{day}) = {{月份信息}}.{month},其中 trunc_month 函数用于获取变量所在月的第一天。我们在 销售订单数 表中添加虚拟列 trunc_month({{销售订单数}}.{day}),存在多行数据有相同的值,这意味着 “销售订单数” 表应被定义为基数为 “多” 的一侧;而 “月份信息” 表中每行数据的 “month” 都不相同,所以 “月份信息” 表应被定义为基数为 “一” 的一侧。销售订单数和月份信息的关联基数判定为多对一。
数据集9:销售订单数(orders)
| day | order_num | trunc_month({{销售订单数}}.{day}) |
|---|---|---|
| 2023-01-01 | 200 | 2023-01-01 |
| 2023-01-02 | 150 | 2023-01-01 |
| 2023-01-04 | 300 | 2023-01-01 |
| 2023-02-01 | 100 | 2023-02-01 |
| 2023-02-05 | 80 | 2023-02-01 |
| 2023-02-06 | 90 | 2023-02-01 |
| 2023-01-01 | 200 | 2023-01-01 |
数据集10:月份信息(date)
| month |
|---|
| 2023-01-01 |
| 2023-02-01 |
| 2023-03-01 |
关联基数对模型计算的影响
关联基数中多的一方会引起另外一方的数据膨胀,所以模型中设置不同的基数类型,决定了关联计算的执行逻辑。核心规则是:
- 模型表在任何情况下都需要参与计算,从模型表到度量所用数据集的路线上的数据集也都会参与计算。度量所用数据集后面的节点是否参与到计算,是由关联基数确定的。
- 保证每个度量的正确性,如果计算度量A的时候引入度量B,会引起度量A所在数据集的数据膨胀,那么度量A和度量B就分开计算。
在下面的说明中,假设左表是模型表,右表是从表,不同的关联基数会引起不同的执行逻辑:
- 一对一:这种基数类型体现的是对等关系,在数据关联过程中不会引起数据的膨胀。基于左边和右表的所有计算的基础都是左表和右表的关联结果。
- 一对多:这种基数类型体现与右表的关联会引起左表的数据膨胀。只和左表相关的度量计算基础是左表,其它度量的计算基础是左表和右表的关联结果。
- 多对一:这种基数类型体现与左表的关联会引起右表的数据膨胀。但是由于模型表始终参与计算,所以基于左边和右表的所有计算的基础都是左表和右表的关联结果。
- 多对多:左右表都会由于关联引起数据膨胀,但是模型表还是要始终参与计算。只和左表相关的度量计算基础是左表,其它度量的计算基础是左表和右表的关联结果。
生效机制
模型中有一个模型表和多个从表,基于此模型的场景分析,模型表都会被引入计算,但是从表是否会被引入计算,需要参照从表的生效机制。生效机制决定了数据集在计算过程中如何相互协作的,生效机制分为按需关联和始终关联两种。
按需关联
按需关联是关系的默认生效机制。其核心特点是只有当右表中的字段在分析中被使用时,右表才会参与到计算过程中。这一机制体现了一种 “按需调用” 的理念,能够根据实际的计算需求灵活地引入右表数据,避免不必要的资源消耗。
始终关联
始终关联机制要求只有在基数为“一对一”或者“多对一”的关系中才可以设置。其规则是只要左侧数据集在计算过程中被使用,右侧数据集就会自动参与到计算中。这种机制确保了右侧数据始终与左侧数据协同工作。这个功能通常用于使用数据集限制数据权限的场景中。
过滤条件
模型关联后过滤条件指的是在完成数据模型之间的关联操作后所设置的筛选规则。数据模型关联将不同结构的数据集按照关联关系组合在一起后,可能会产生大量的数据,其中部分数据对于当前具体的分析场景而言是不必要的。此时,就需要借助过滤条件来对这些关联后的数据进行筛选。
启用环形模型
启用环形模型功能有两个选项,它决定了当前从表是否可以有多个上游数据集。独立关联关系表示当前从表只能有一个上游数据集,共享关联关系表示当前从表可以有多个上游数据集。启用共享关联关系通常用于多维度表多事实表的场景中。 下图的场景中,user数据集做为用户信息,关联app、dataset、dashboard数据集。这样可以在用户维度同时分析app、dataset、dashboard数据集。
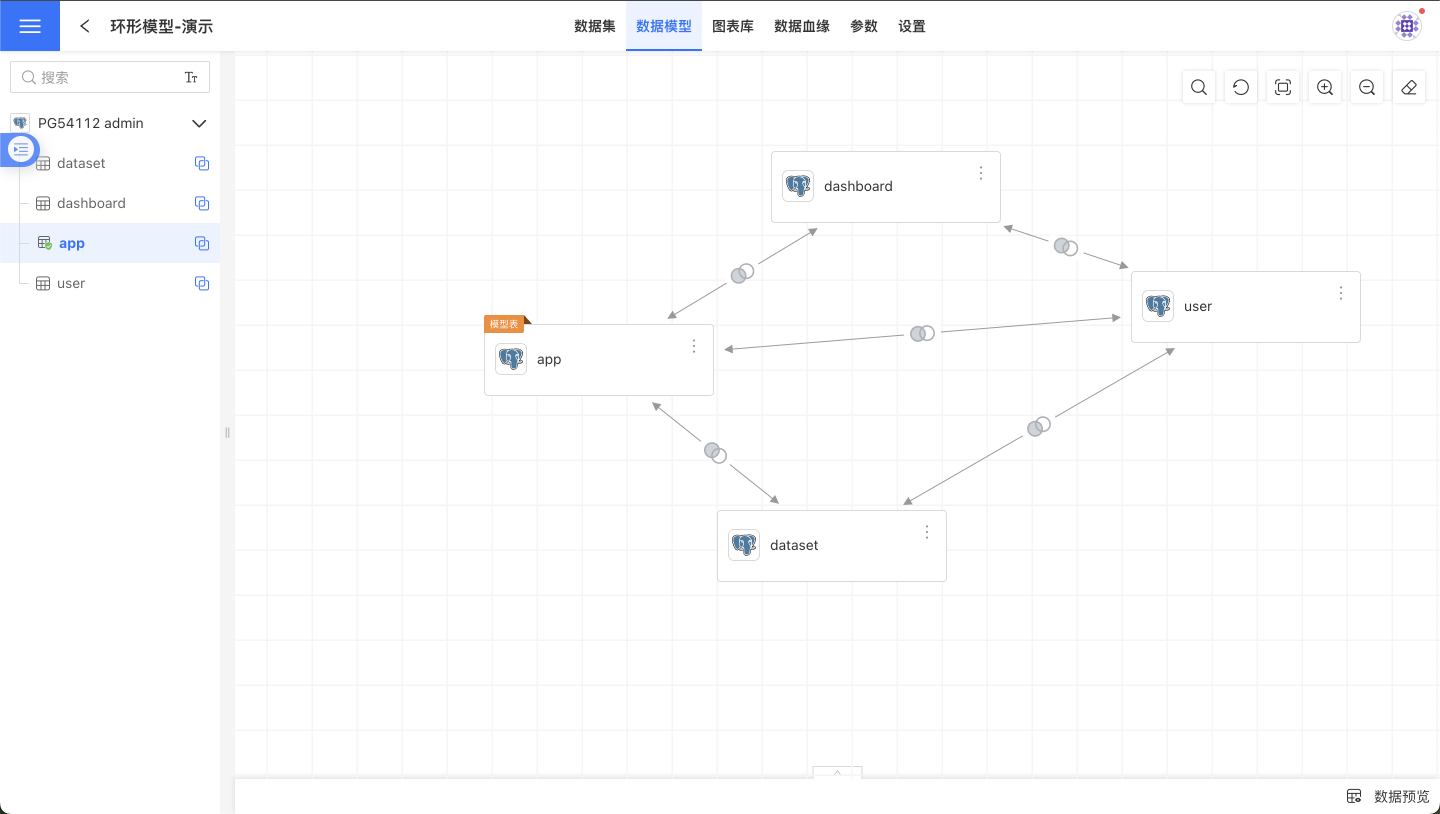
环形模型的限制:
- 其他表与"共享关联关系"的从表的关联基数能为多对一(多:1)或者一对一(1:1)。
- 关系路径从模型表出发,到"共享关联关系"的从表结束,"共享关联关系"的从表的后面不能再有其它从表了。
- "共享关联关系"的从表不支持重命名。
- 一个模型中同一个数据集做为"共享关联关系"的从表只能存在一个。