批量同步
当用户需要将数据从一个数据库迁移到一个或多个目标数据库时可以通过在批量同步中创建项目来实现。
批量同步主要功能:
- 将一个或者多个表同步到指定连接中。
- 在数据同步过程中设置数据同步策略。
- 支持手动、定时同步数据。
- 可执行多个项目来完成数据同步工作。
创建数据同步流程
批量同步数据的过程如下: 
- 创建批量同步项目。
- 配置来源数据连接和目标数据连接。
- 配置同步策略。
- 设定项目执行计划。
批量同步详细指导
创建批量同步项目
在数据集成->批量同步页面中,点击右上角的新建项目,创批量同步项目。 
配置数据源
在批量同步项目页面设置来源数据连接(需要迁移的数据连接)和目标数据连接(即数据迁移到的数据连接)。 目标数据连接创建时需要勾选允许写入操作。 如果不了解数据连接的概念,请先阅读数据连接。 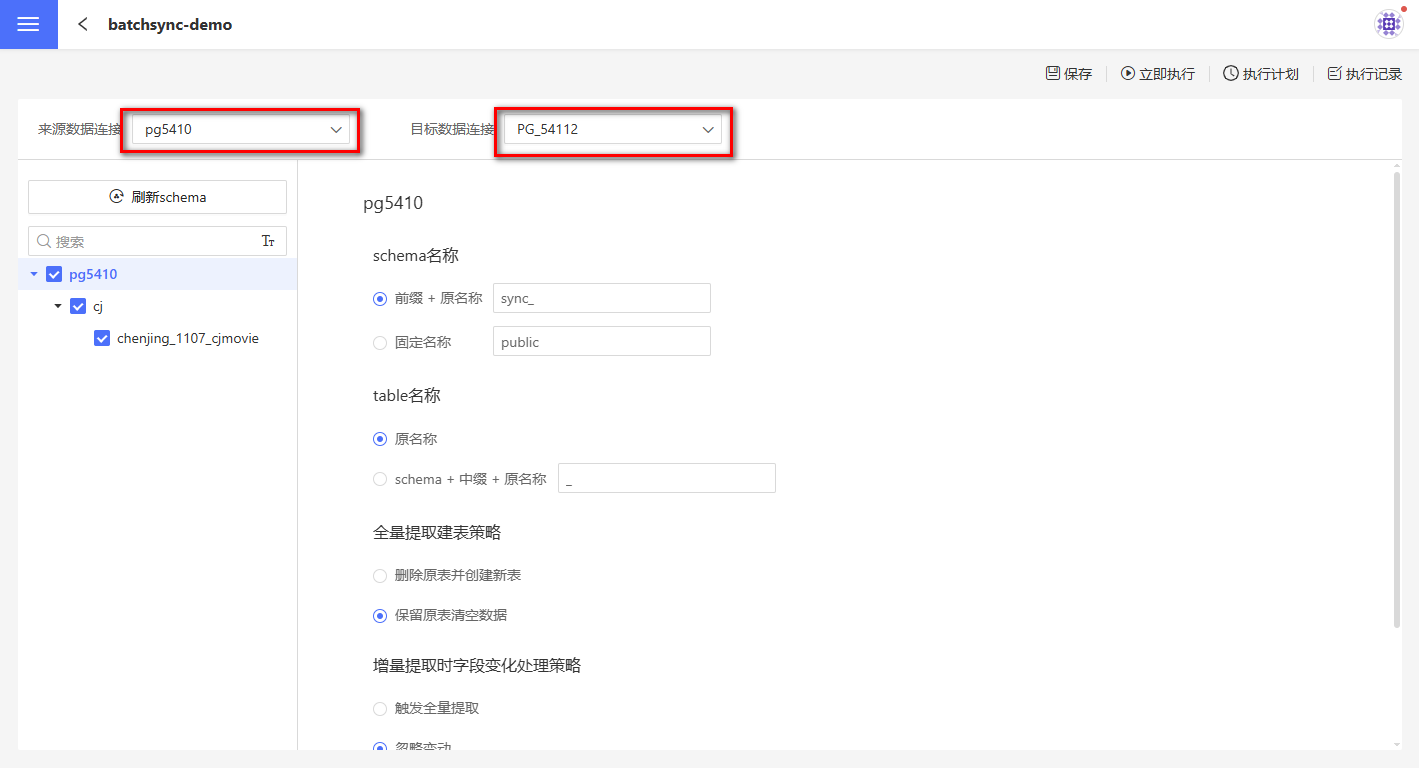
配置数据同步策略
批量同步支持对连接、schema、表分别设置同步策略。
配置连接同步策略
连接同步策略对连接内所有目录及目录下的表都生效。连接同步策略包括:
- schema 名称: 数据同步后表所在的 schema 名称设置。
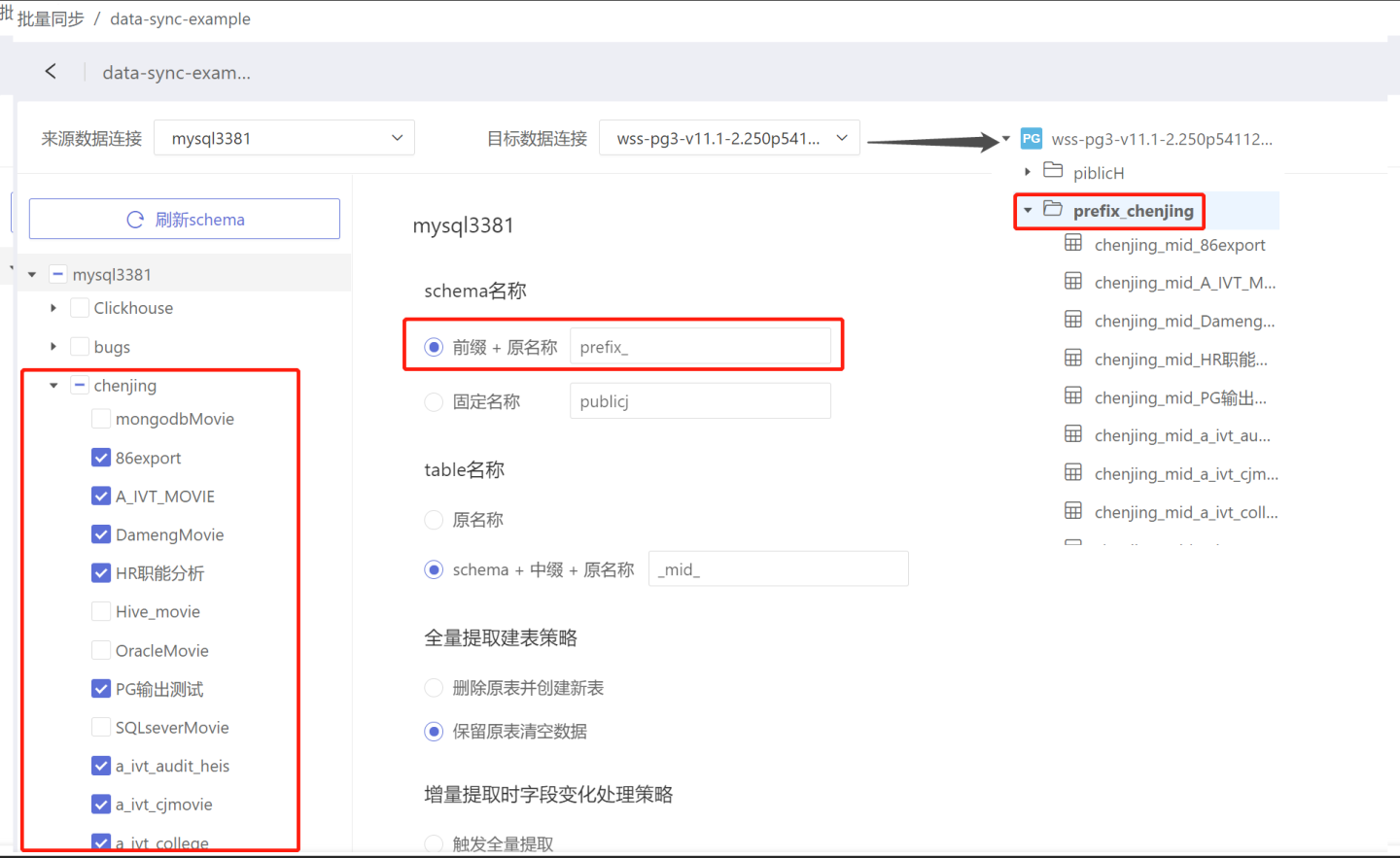
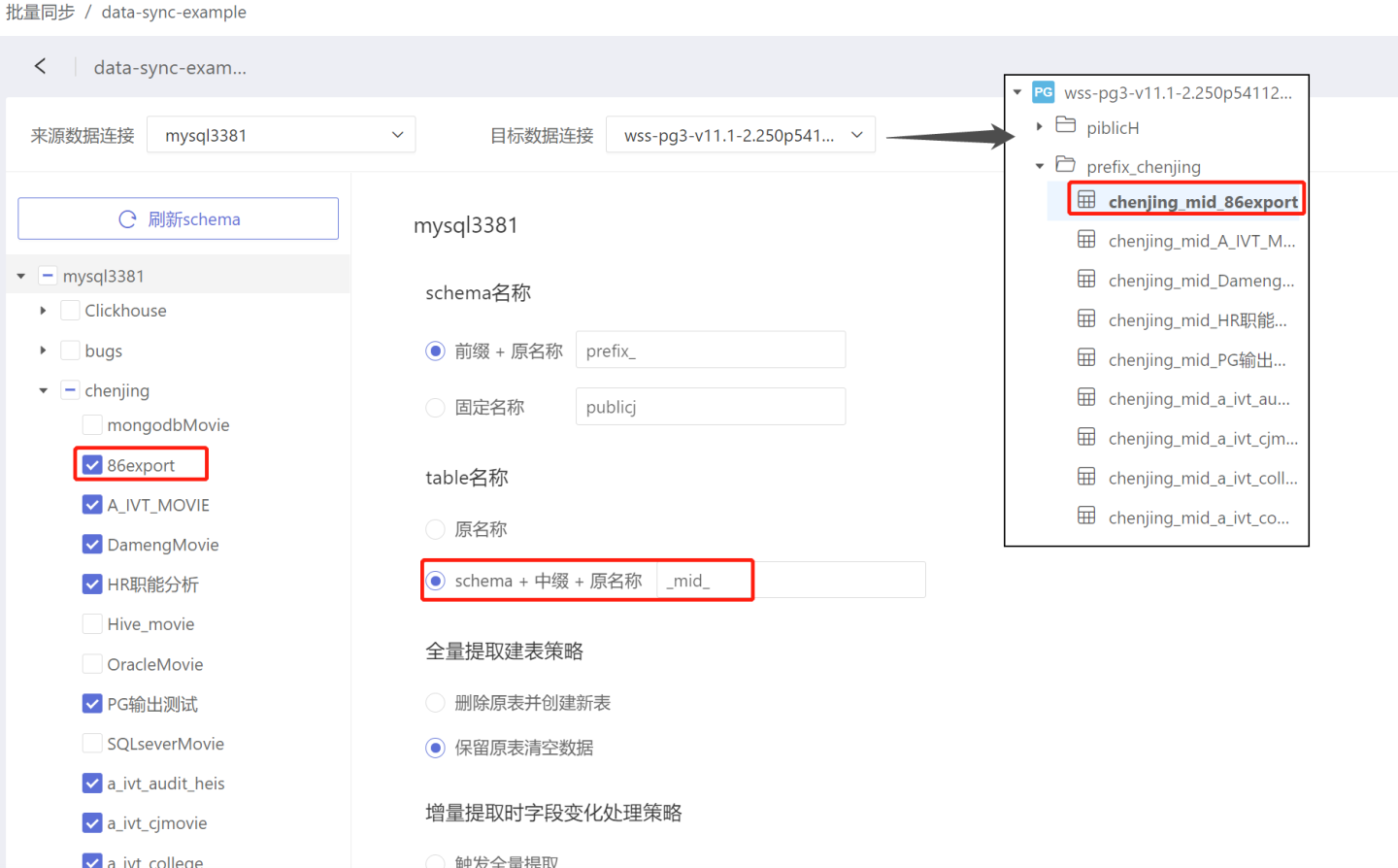
- 前缀+ 原名称 : 数据同步后表存放的目录名称为“前缀”+“原名称”。 如图将前缀设置为“prefix_”时,数据同步前表86export 存放在目录 chenjing 中,同步后表86export 存放目录名称为“prefix_chenjing”。前缀没有默认值,需要按需填写。
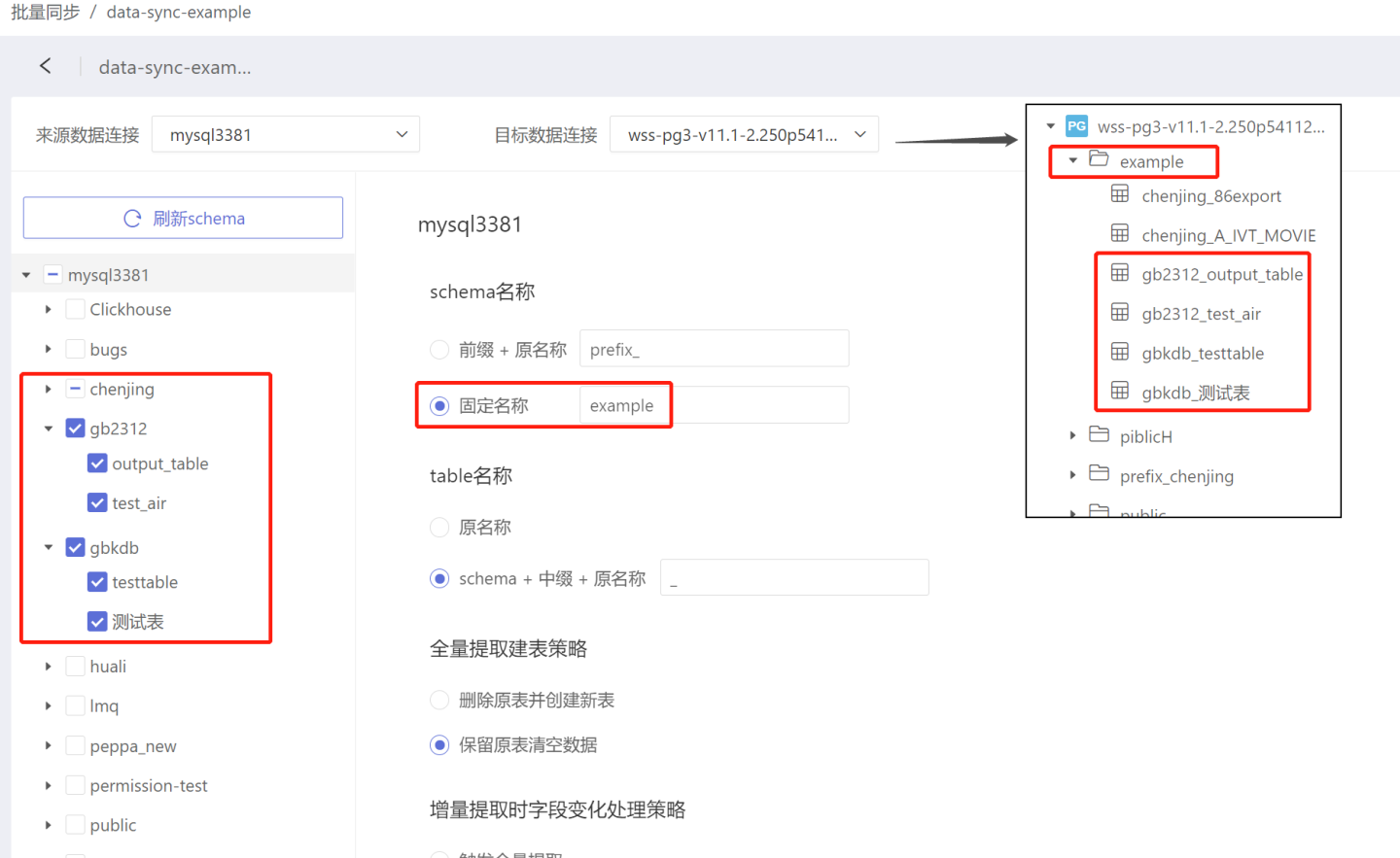
- 固定名称:数据同步后所有表存放在同一目录中。 如图所示,目录 chenjing、gb1312、gbkdb 里面的表都存放在 example 中。固定名称没有默认值,需要按需填写。
- 前缀+ 原名称 : 数据同步后表存放的目录名称为“前缀”+“原名称”。 如图将前缀设置为“prefix_”时,数据同步前表86export 存放在目录 chenjing 中,同步后表86export 存放目录名称为“prefix_chenjing”。前缀没有默认值,需要按需填写。
- table 名称:表同步后的命名规则。
- 原名称:数据同步后表名不变。
- schema+中缀+原名称:数据同步后,表的名称变为“schema”+“中缀”+“原名称”。如图将中缀设为“_mid_”时,表86export 同步后名称改为 chenjing_mid_86export。中缀没有默认值,需要按需填写。
- 全量提取建表策略: 默认表都是全量提取,除非在表级别特别设置为增量提取并做相应设置。当表选择全量提取时,支持以下两种方式。
- 删除原表并创建新表:将原有表格删除,重新创建新表,同步数据。
- 保留原表清空数据:原表不删除,只是将数据进行清空,然后同步数据。如果新数据有多的字段,会在目标表中加上。如果新数据少字段,目标表对应的字段为建表时设置的默认值,一般为null。
- 增量提取时字段变化处理策略: 默认表都是全量提取,除非在表级别特别设置为增量提取并做相应设置。当表选择增量提取时,如果表的字段发生变化可以选择如下两种处理策略。
- 触发全量提取: 表按照全量并删除原表的方式进行提取方法。
- 忽略变动: 忽略变动的字段,表按照原来增量方式进行提取。新数据多的字段,会在目标表中加上,但是老数据该字段不会被同步,而是null。新数据少的字段,目标表对应的字段的老数据不会改变,该字段在新插入的记录中为建表时设置的默认值,一般为null。
- 忽略后续新增的表: 勾选此项后,来源数据连接中新增的表不会被同步。
- 为每个表添加额外的更新时间列 选择此项后,数据同步时,除了原始的数据列之外,会额外增加 hs_sync_time 列,记录每行数据被同步的时间戳。
配置 schema 同步策略
配置 schema 同步策略仅对当前 schema 生效,目前仅支持“忽略后续新增的表”的配置。前面设置的“忽略后续新增的表”是针对整个连接的设置,这里是针对单个schema设置,优先级高于全局设置。
配置表同步策略
表同步策略仅对当前表配置生效。表同步策略包括:
- 提取方法
- 全量提取:每次都是全量提取数据。
- 增量提取:
增量提取需要选择增量键,提取时只会提取增量字段值大于当前已导入数据中该增量字段最大值的数据。要求增量字段必须是单调递增的。如果选择多个增量字段,那么增量字段按添加的顺序组合成多字段组合,这个组合也必须是单调递增的,比如年字段-月字段-日字段组合,使用无关的多个字段无法做增量字段组合。增量字段的最大值是从目标表获取的。设置增量字段后,首次执行仍然是全量提取,因为首次执行目标表没有最大值记录。增量键是在读取数据时使用,建议来源数据连接对应的表建立相应的索引以提高性能。
- 键字段:设置键字段用来做主键和分布键。键字段是在写入时使用的。键字段有两个功能。
- 增量更新时是用来做主键,以便排重。
- 建表时用来做主键和分布键。如果设置建表属性,则键字段设置不生效。
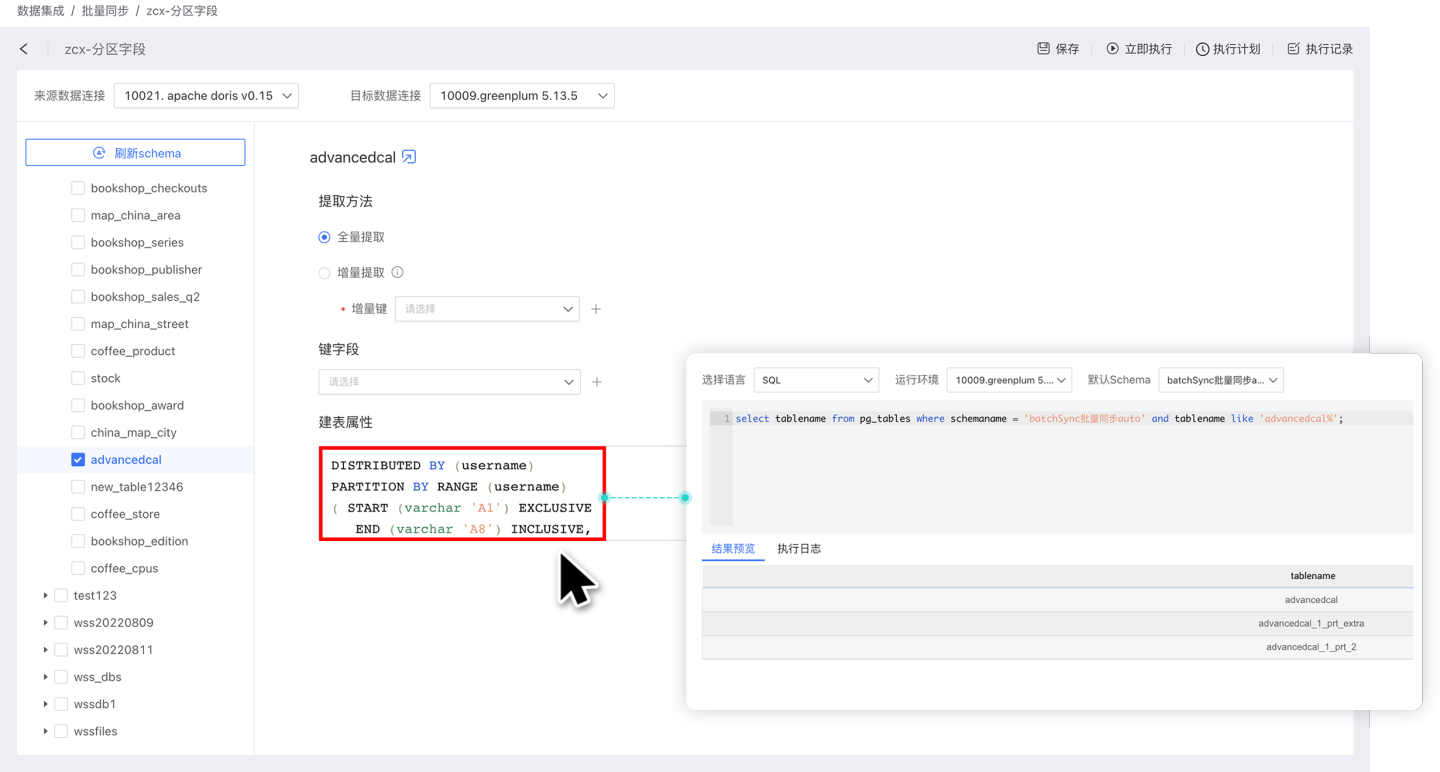
- 建表属性:在数据同步表创建过程中自定义分区字段和索引字段,对数据进行分散存储。 建表属性仅在第一次建表时生效。 目前支持建表属性的数据源包括 Greenplum、Apache Doris、StarRocks 和 ClickHouse。
配置保存
配置设置后需要点击保存按钮以保存到系统中,否则离开页面后会丢失。如果还没保存就点击执行,执行的是按当前的配置来执行的,但是配置还是没有保存,需要手动保存。 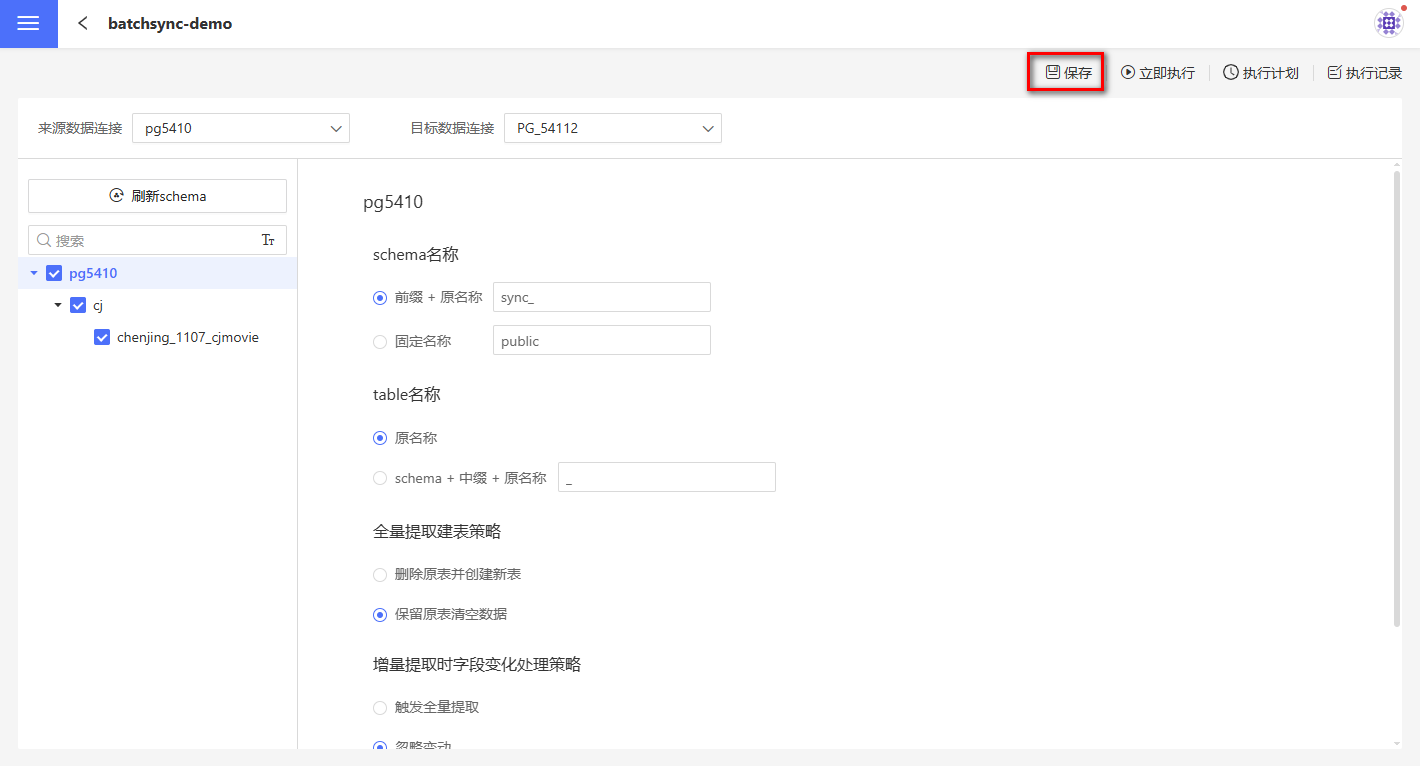
数据分批同步
当提取的数据量比较大时,数据导入时间可能超过了源数据库的查询超时时间,导致数据提取失败。此时可以通过配置项 ETL_SRC_MYSQL_PAGE_SIZE (MySQL) 或 ENGINE_IMPORT_FROM_PG_BATCH_FETCH_SIZE (PostgreSQL) 设置一次提取数据的最大上限,当超过该上限时数据进行分批提取。目前只有 MySQL 和 PostgreSQL 数据源支持分批提取。
提示
请联系技术人员配置 ETL_SRC_MYSQL_PAGE_SIZE 或 ENGINE_IMPORT_FROM_PG_BATCH_FETCH_SIZE。
执行同步操作
数据同步可分为立即执行和通过执行计划同步数据。
立即执行:即手动执行数据同步操作,点击立即执行按钮后开始同步数据。
执行计划:即设定同步计划,由系统触发数据同步操作。点击右上角的执行计划,进入执行计划设置页面,设置计划的基本信息、调度信息、告警信息。
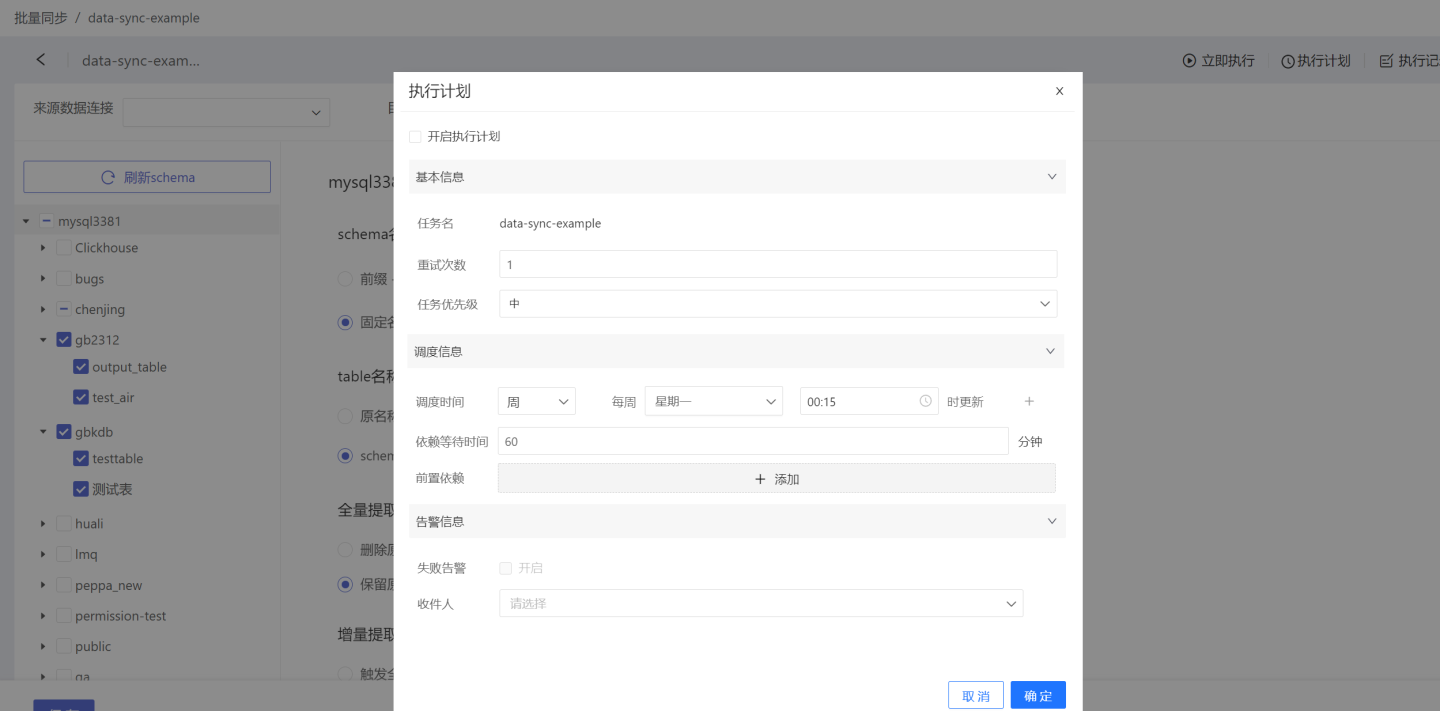
- 基本信息:设置执行时重试次数及任务的优先级。任务优先级分高、中、低三个级别。高级别的任务优先处理。
- 调度信息:
- 设置任务的调度时间,可设置多个调度时间。 支持按小时、天、周、月的方式设置执行计划。
- 小时:可设置每小时的第几分钟更新。
- 天:可以设置每天具体的时间点更新。
- 周:可以设置每周的周几的具体时间点更新,可以多选。
- 月:可以设置每月的第几天的具体时间点更新,可以多选。
- 自定义:可以自行设置更新的时间点。
- 设置任务的前置依赖,可设置多个前置依赖任务。
- 设置依赖等待时间。
- 设置任务的调度时间,可设置多个调度时间。 支持按小时、天、周、月的方式设置执行计划。
- 告警信息:开启失败告警,当任务执行失败后,会以邮件形式通知到收件人。
提示
每次执行数据同步,无论成功和失败都会记录在执行记录中。
FAQ
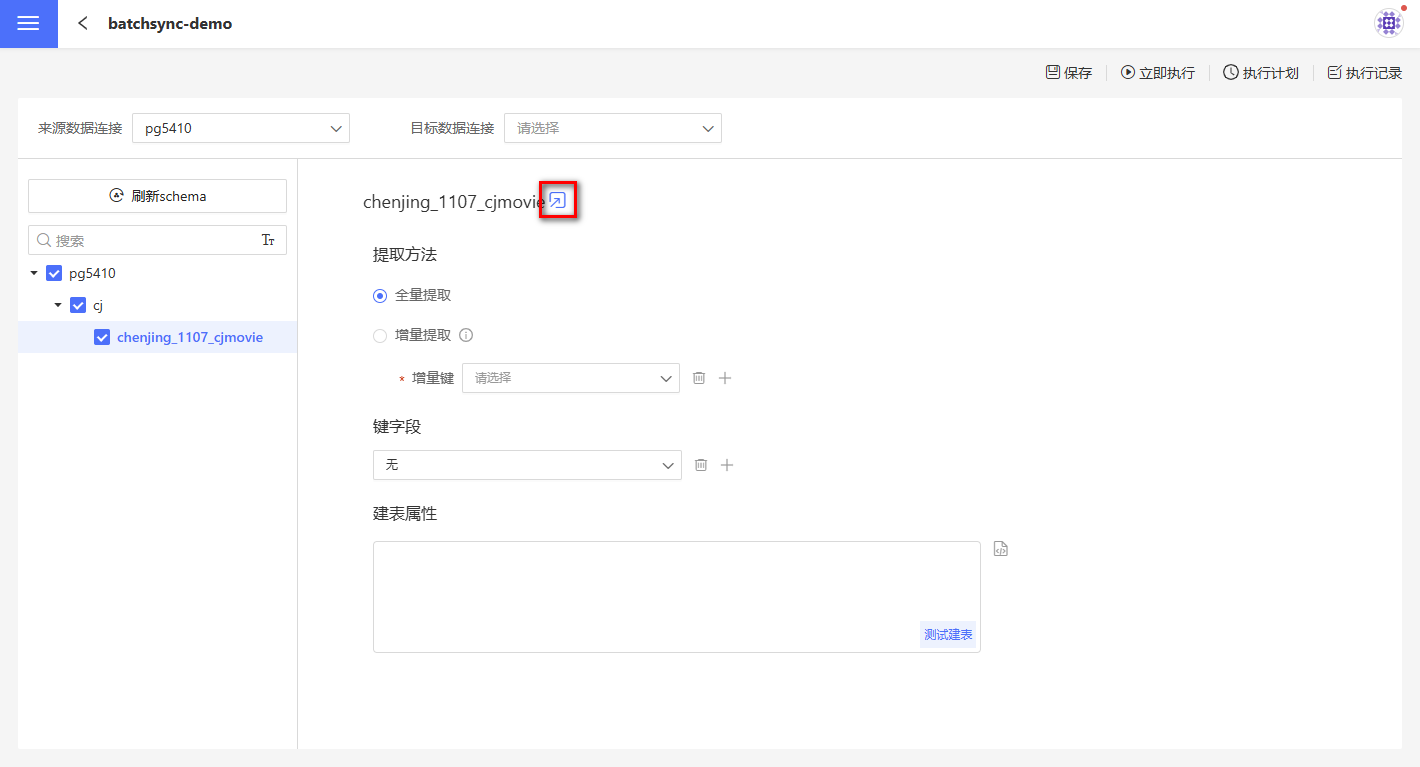
1.单表快捷同步 数据集成支持单表快捷同步。在全量提取少数表时,设置目的数据连接后,找到对应的表,点击图标即可完成表同步。