连接 Hive
操作步骤
请参照如下步骤连接 Hive 数据源。
在数据连接页面右上角点击新建数据连接。

在数据源种类中选择
Hive数据源。
按要求填写连接时数据源的参数。
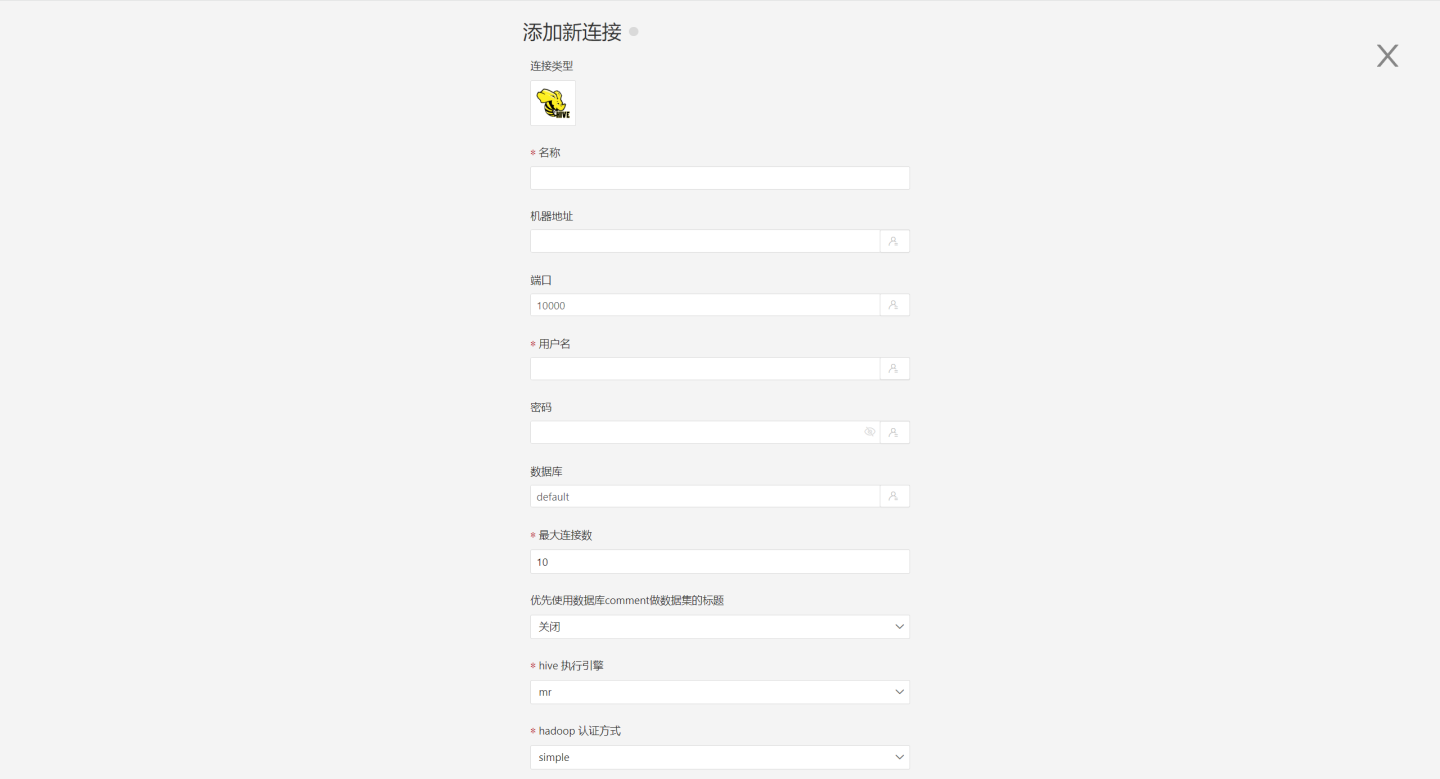
连接配置信息说明
字段 说明 名称 连接的名称。必填,且用户内唯一 机器地址 数据库的地址。如果填了 url 字段,优先使用 url 里面的 端口 数据库的端口。如果填了 url 字段,优先使用 url 里面的 用户名 数据库的用户名 密码 数据库的密码 数据库 数据库名称 模式 数据库的schema 最大连接数 连接池最大连接数 优先使用数据库 comment 做数据集的标题 优先显示表的名字还是表的注释 hive 执行引擎 hive 执行引擎,可选择 mr、tez、spark 三种引擎 hadoop 认证方式 hadoop 认证方式,支持 “simple”,“kerberos”,“tbds” 3种。当选择 “kerberos” 或 “tbds” 时,上面的“用户名”和“密码”要填写对应 “kerberos” 或 “tbds” 系统中的用户名和密码 realmA 当 hadoop 认证方式为 kerberos 时,需要填写该项 kdcA 当 hadoop 认证方式为 kerberos 时,需要填写该项 realmB 当 hadoop 认证方式为 kerberos 时,需要填写该项 kdcB 当 hadoop 认证方式为 kerberos 时,需要填写该项 server principal 当 hadoop 认证方式为 kerberos 时,需要填写该项 URL 数据库的 jdbc url 读取行为的事务隔离级别 该设置只影响读取数据,写入数据还是用默认的隔离级别 分层加载 schema 和表 默认为 关闭。开启时分层加载 schema 和表,连接过程只加载 schema,需要点击schema才会加载schame下的table 查询超时时间(秒) 默认为 600. 当数据量较大时,可以适当增加超时时间 只显示指定数据库/模式下的表 该项选中时并且 database 字段不为空,则只显示该 db 下面的表 填好参数后,点击
验证按钮,获取验证结果(验证 HENGSHI SENSE 和设置的数据连接的连通性,在未验证通过时不可添加)。验证通过后,点击
执行预置代码,弹出该数据源对应的预置代码,点击执行按钮。点击
添加按钮,添加Hive连接。
请注意
- 配置参数时带*的参数是必填参数,其他参数为选填。
- 连接数据源时,必须执行预置代码。不执行会导致数据分析过程中某些函数无法使用。此外,从4.4之前的版本升到4.4时,需要对系统中已经存在的数据连接执行预置代码。
支持的版本
1.2.0, 1.2.1, 1.2.2, 2.0.0, 2.0.1, 2.1.0, 2.1.1, 2.2.0, 2.3.0 等
数据连接预览支持
支持show tables能列出的所有表。
SQL查询数据集对SQL的支持
支持所有SELECT相关特性,SELECT SQL 语句需要符合Hive语法规范。
不支持的字段类型
hive 的以下数据类型,不能正确处理:
- BINARY
- arrays
- maps
- structs
- union