Data Agent
概述
在 HENGSHI SENSE 中,借助大模型的能力 Data Agent 可以帮助用户充分使用数据。基于对话式交互体验,Data Agent 可以帮助用户完成从业务数据即时分析到指标创建、仪表盘生成等任务。我们还将持续在产品中融入 Agent 能力,旨在提高数据分析及数据管理人员的工作效率,简化工作流程及复杂任务。
安装与配置
先决条件
请确保完成以下步骤使 Data Agent 进入可用状态:
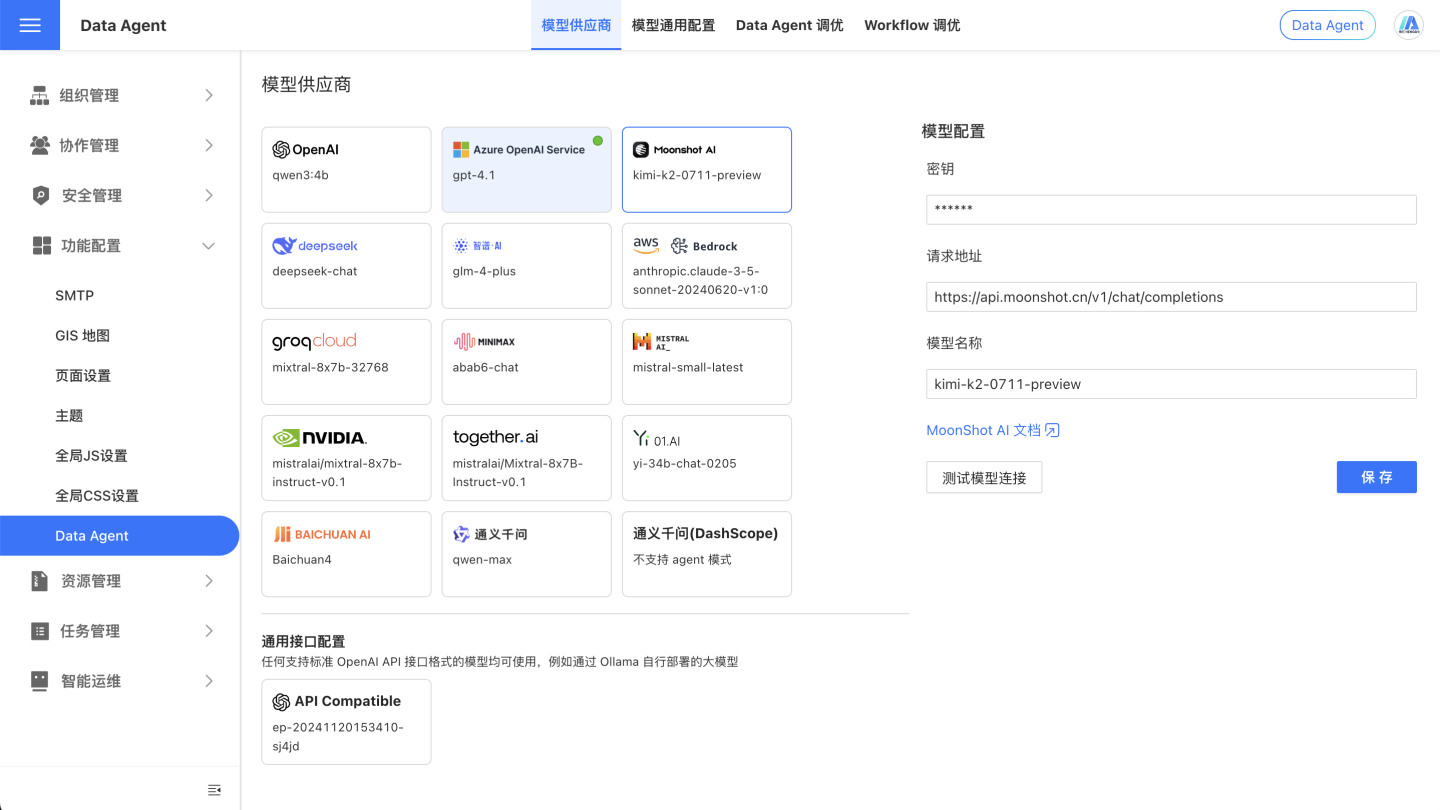
配置大模型
在系统设置-功能配置-Data Agent页面,配置相关信息。
使用指南
在使用 Data Agent 之前,需要对数据做一些处理,以确保 Data Agent 理解独特的业务背景,能够优先识别正确信息,并提供一致、可靠且符合目标的响应。
为 Data Agent 准备数据,就是在为高质量、接地气且懂场景的 Data Agent 体验打下根基。如果数据杂乱无章或含义模糊,Data Agent 可能难以准确理解,给出的结果要么流于表面,要么偏离事实,甚至可能产生误导。
投入精力做好数据准备,Data Agent 就能真正吃透业务场景,精准抓取关键信息,给出的回答不仅稳定可靠,更与目标高度契合,更能让 Data Agent 发挥实效。
注意
AI 的行为是不确定的,即使输入相同内容,AI 也并不总是产生完全相同的响应。
为 AI 编写提示词
行业术语、私域知识
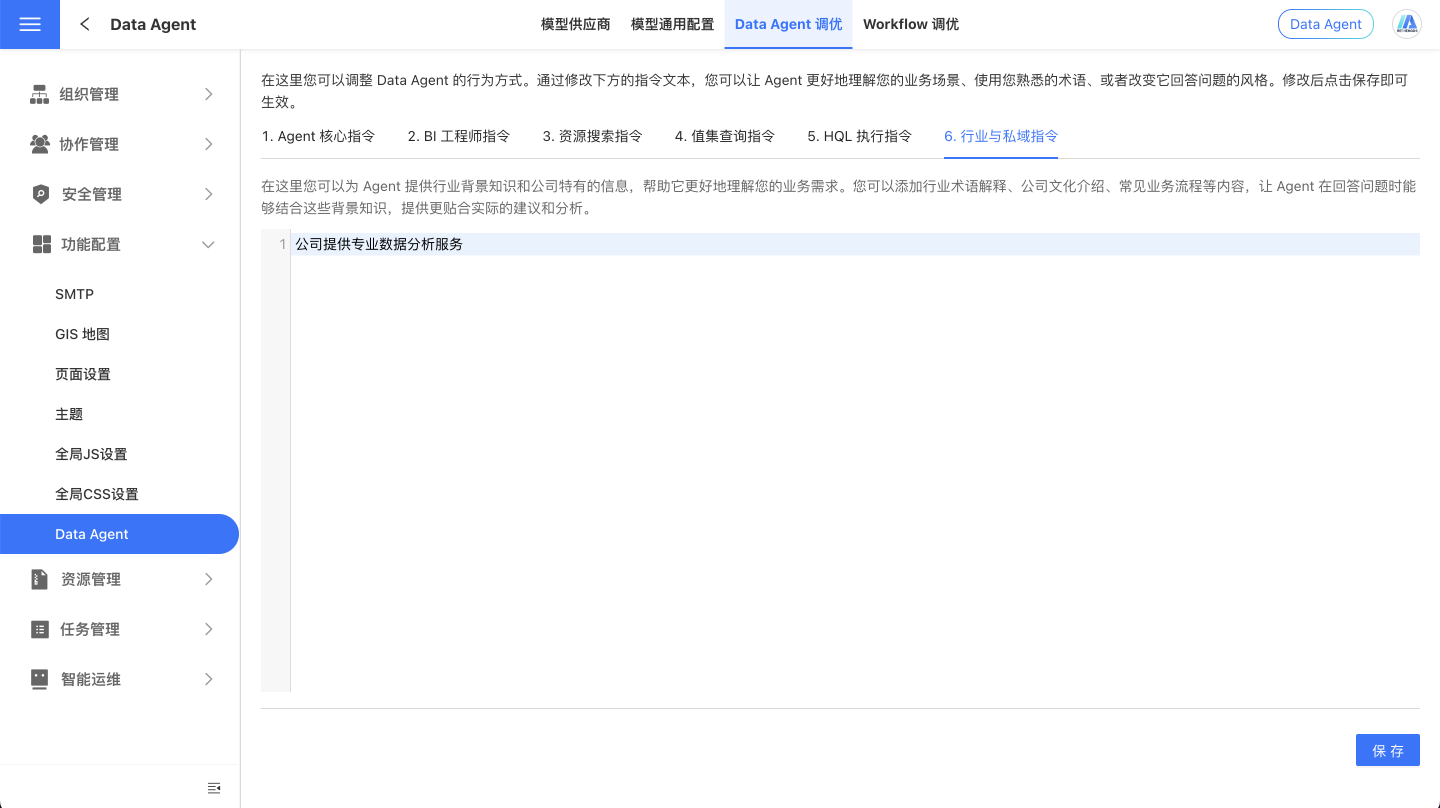
为了让大模型发挥更强性能,我们在系统设置的 Data Agent 控制台中提供了配置提示词的功能,您可以使用自然语言在 UserSystem 提示词中向大模型提供包括不限于公司行业背景信息、业务逻辑、思考分析方向指引、特定指导,Data Agent 会运用这些指令来理解组织内部的语言习惯、专业术语和分析重点,准确理解你所在领域的专有术语和分析预期,从而提升回答质量与相关性。
提示词可以帮助 Data Agent 根据您的行业、战略目标、术语或运营逻辑做出响应,进而可以确保用户获得更准确、更相关的数据分析。例如:
- 大促是指每年的10月11日至11月11日
- 当用户提到产品相关问题时,请同时获取产品名称和产品 id
数据集分析规则
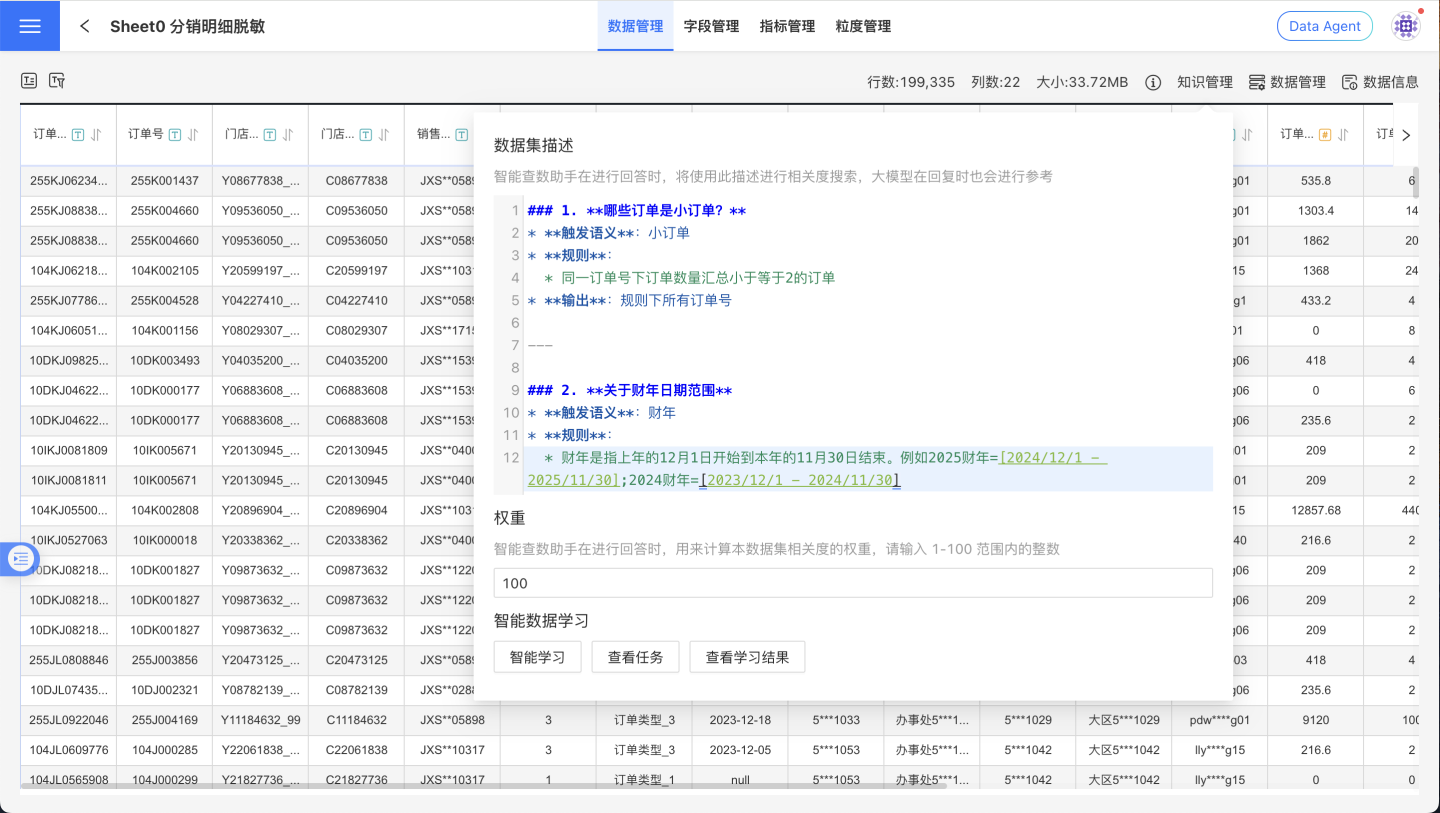
在数据集的知识管理中,您可以使用自然语言详细描述数据集的用途、隐含规则(如过滤条件)、同义词及专有业务词语对应的字段和指标,指导 Data Agent 如何进行某些类型的分析。例如:
- "小订单"是指同一订单号下订单数量汇总小于等于2的订单
- "财年"是指上年的12月1日开始到本年的11月30日结束。例如2025财年是指2024/12/1至2025/11/30,2024财年是2023/12/1至2024/11/30
- 当问 AAA 时,同时列出 BBB、CCC、DDD 等指标数据
注意
了解提示词工程的最佳做法非常重要。AI 可能对收到的提示词很敏感,提示词的构造会影响 AI 的理解和输出。提示词的特点如下:
- 明确、具体
- 使用类比和描述性语言
- 避免歧义
- 使用 markdown 按主题按结构化编写
- 尽可能将复杂的指令分解为简单的步骤
为 AI 准备数据
数据向量化
为了在海量数据资产中更高效、准确地定位到与问题最相关的信息,建议对数据进行“向量化”处理。向量化会将字段/原子指标的名称、描述、字段值等文本信息转换为可计算的语义向量,并写入向量数据库,使 Data Agent 能够基于语义进行检索与召回,而不仅仅依赖关键词匹配。
向量化的收益:
- 更高的相关性:理解同义词、行业术语与上下文,减少漏检与误检。
- 更快的响应:缩小检索范围,减少大模型上下文填充成本。
- 更强的可扩展性:支持跨数据包的语义联想与知识链接,适配多语言场景。
- 持续优化:配合“智能学习”任务,结合人审结果不断提升问答质量。
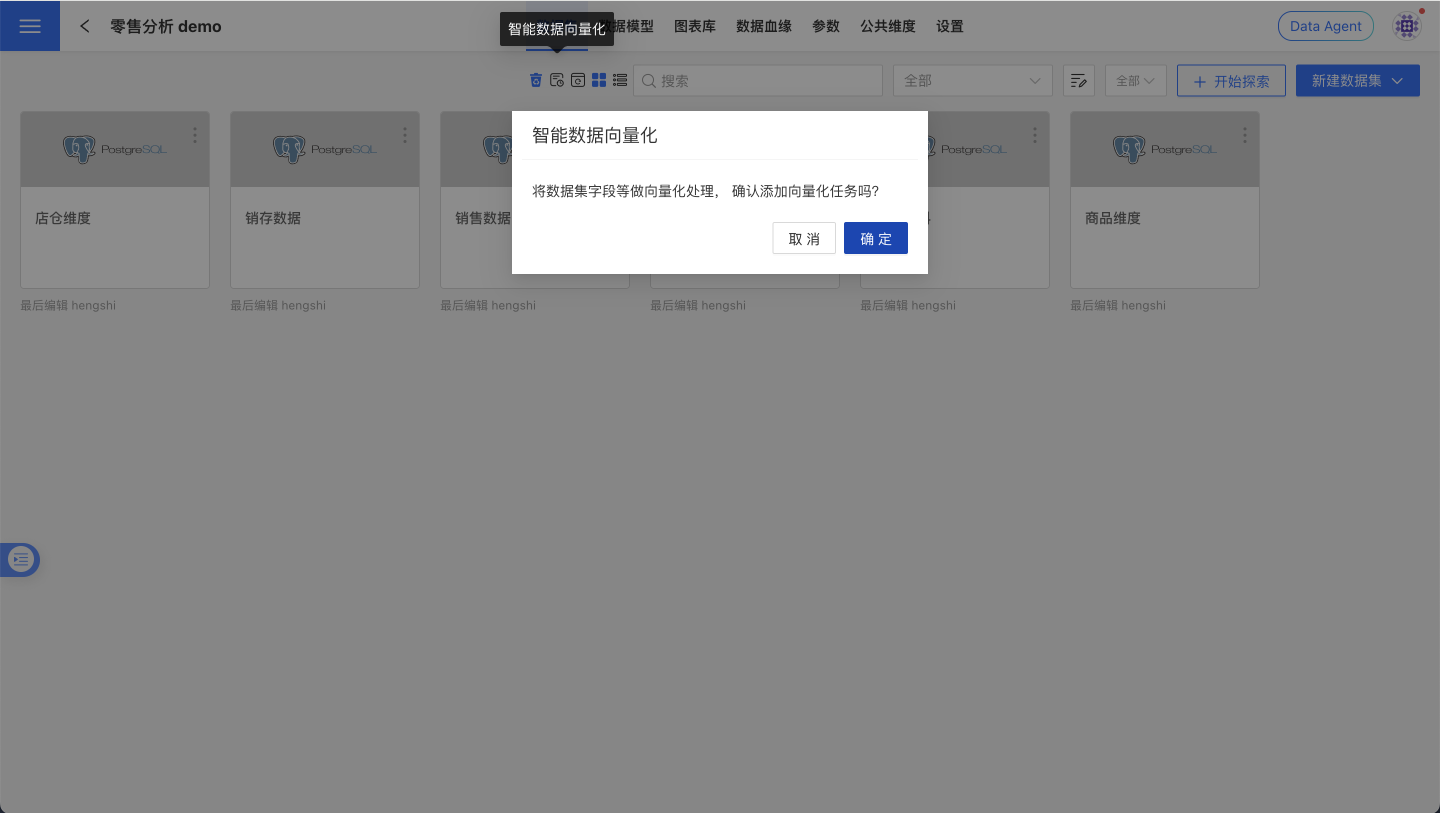
操作步骤:
- 进入目标数据包页面,在操作栏点击“向量化”。
- 在系统设置-任务管理-执行计划中查看进度,按需开启定时任务,提升召回的稳定性与覆盖面。
注意
字段 distinct 值向量化最大数量为 10 万条
数据管理
良好的数据管理是 Data Agent 正确理解业务语义与指标口径的基础。通过统一命名规范、补全字段/指标的描述、合理设置数据类型,以及对无关对象进行隐藏或清理,可以显著提升问答相关性与响应速度,降低大模型上下文成本并减少误解。建议在数据包发布前和日常维护时,按下列清单进行自检;配合“数据向量化”和“智能学习”使用,效果更佳。
- 数据集命名:确保数据集名称简洁明了,能够清晰反映其用途。
- 字段管理:确保字段名称简洁且具有描述性,避免使用特殊字符。在字段描述中详细说明字段的用途,如“默认用我做时间轴”。另外,字段的类型需要跟使用目的一致,比如需要求和的字段应该用数字类型,日期字段应该用日期类型等等。
- 指标管理:确保原子指标名称简洁且具有描述性,避免使用特殊字符。在原子指标描述中详细说明指标的用途。
- 字段隐藏:对于不参与问答的字段,建议隐藏,以减少发送给大模型的 token 数量,提高响应速度并降低成本。
- 字段与指标区分:确保字段名和指标名不相似,避免混淆。不需要参与回答问题的字段建议隐藏,不需要的指标建议删除。
- 智能学习:建议触发“智能学习”任务,执行通用例子到数据集特异例子的转换。执行完成后,需人工检查学习结果,并进行增删改操作,以提升助手的能力。
提升对复杂计算的理解
在数据侧预先沉淀可复用的业务口径,以指标形式对外暴露,可以在问数场景中获得更高准确率、稳定性与可解释性。
实践建议:
- 对行业特有口径(如金融风控、广告投放、电商转化)给出域内统一定义,并在数据集的知识管理中维护同义词映射。
- 对易混淆概念(如“转化率”“ROI”“复购率”)建立“业务术语 → 指标”的映射,避免模型自由组合字段。
- 优先用“指标”承载口径,而非单次对话里的临时计算表达式;重要指标建议建立版本与变更记录,防止口径漂移。
示例(ROI):
- 广告/电商:ROI = GMV ÷ 广告投放成本。请在指标描述中明确是否含优惠券、是否扣除退款与运费、是否包含平台服务费,统计口径以“支付时间/下单时间”为准,以及时间窗口(如自然日/周/月)。
- 制造/项目:ROI = (收益 − 成本) ÷ 成本,窗口为项目全周期或财务期。
使用场景
Data Agent 的 agent 模式特点有:
- 不限制对话来源
Data Agent 将根据用户的输入内容,自主判断用户意图,分解用户需求,在用户有权限的数据范围内,从数据集市、应用集市、应用创作中进行混合检索,再从目标数据来源中分析并查询数据,最终给出回答。
- 复杂问题拆解
Data Agent 不仅支持常规数据查询问题,还支持一次输入多个问题,尤其是前后存在推理关系的情况下。Data Agent 将会视需求复杂程度进行一次或多次数据查询。
- 环境感知
Data Agent 能够读取登录账号的信息,可以丝滑理解用户输入内容中的指示代词(如“我的部门”等用户属性)。此外还可以读取用户正在浏览的页面信息,当用户在具体的数据包、数据集、仪表盘页面时,Agent 在处理数据查询等需求时将直接基于当前页面的信息进行交互。
在这些能力的加持下,Data Agent 将能够化身为可视化创作助手、指标创作助手,或者分析师助理等多重身份。
智能问数
升级 Data Agent 后,智能问数不再局限于有限的数据范围内的,不再需要手动选择范围才能开始问数。这意味着 agent 的任务将涉及到寻找内容、临时分析或见解。
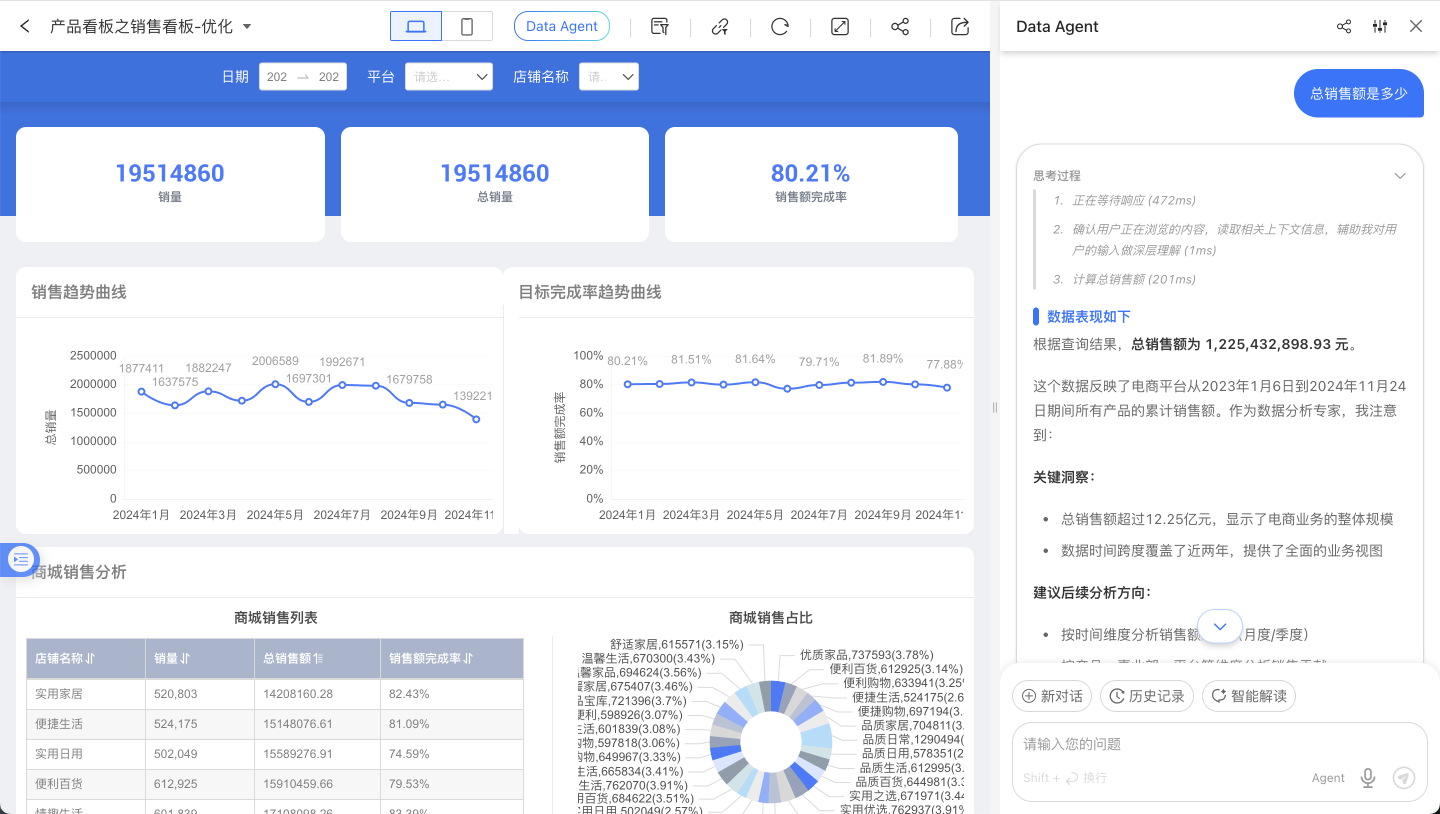
可视化创作
Data Agent 可以根据用户需求在仪表盘列表页面开始从零创建仪表盘,也可以直接编辑已有的仪表盘,不论是图表创作、添加过滤器、分析数据添加富文本报告,还是调整仪表盘布局、调整颜色、批量操作控件。
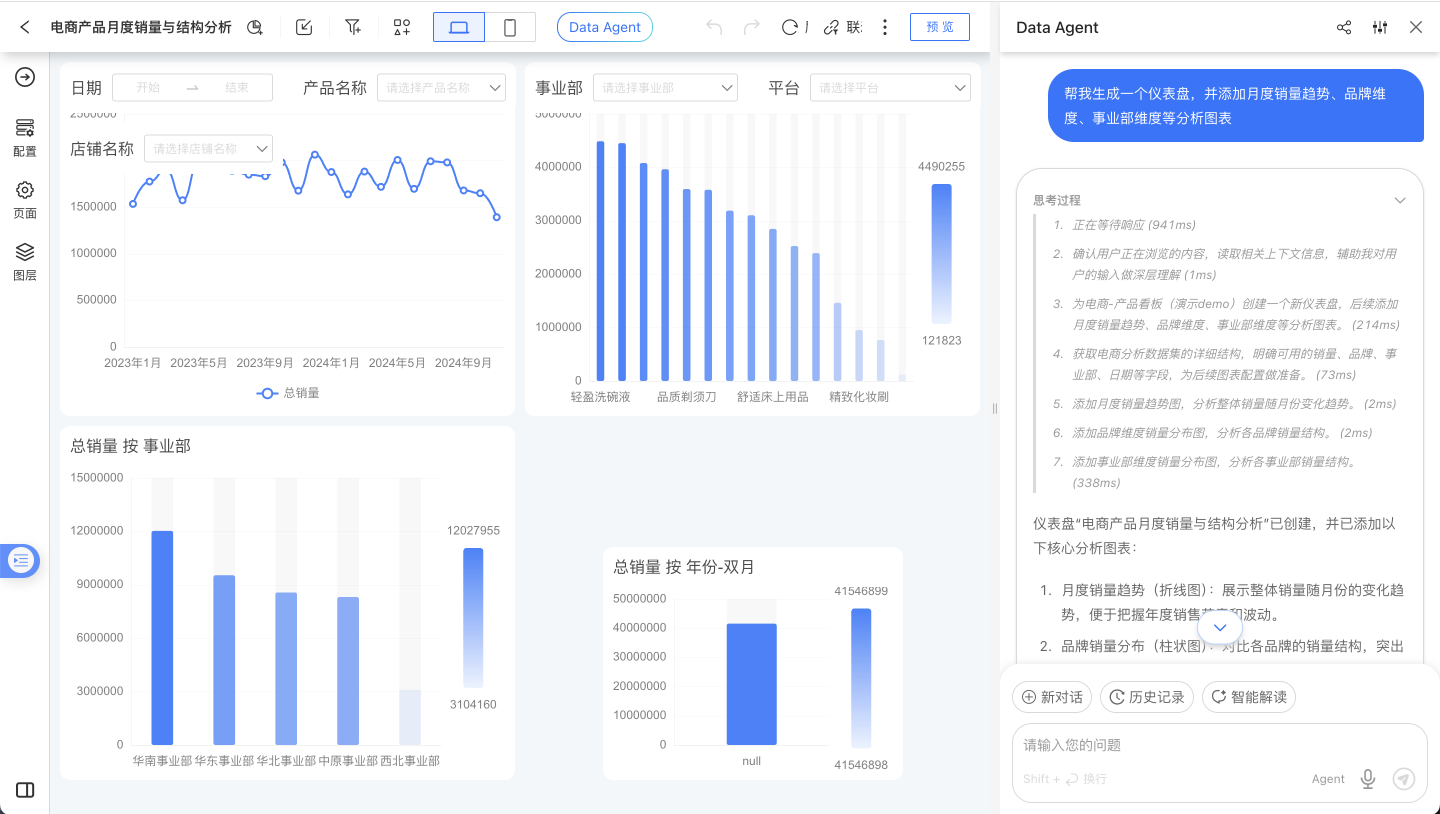
智能解读
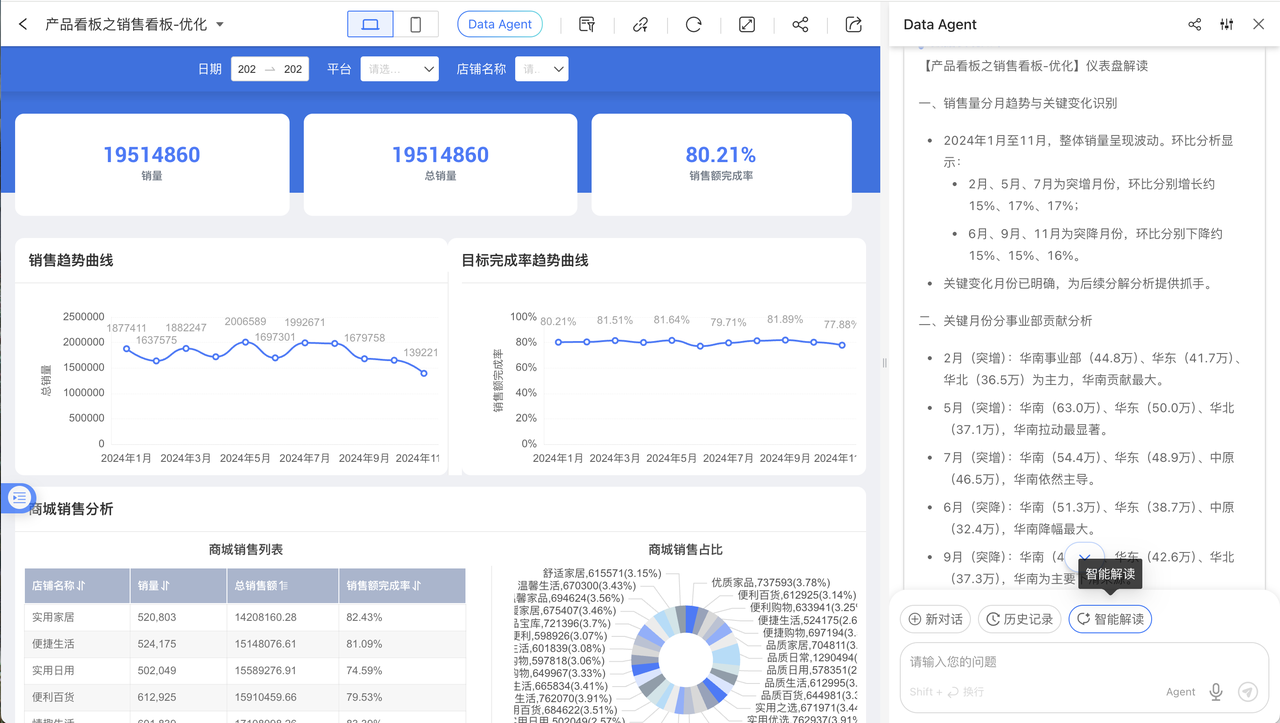
为了方便业务用户使用 Data Agent 做业务数据分析、定期复盘、数据解读等,我们增加了 “智能解读” 的配置以及快捷按钮,在仪表盘页面时,Data Agent 中将出现 “智能解读” 按钮,点击后即可让 Data Agent 跟随预先配置好的解读思路,进行实时的数据查询、异常识别、分解、下钻,最后给出解读报告。
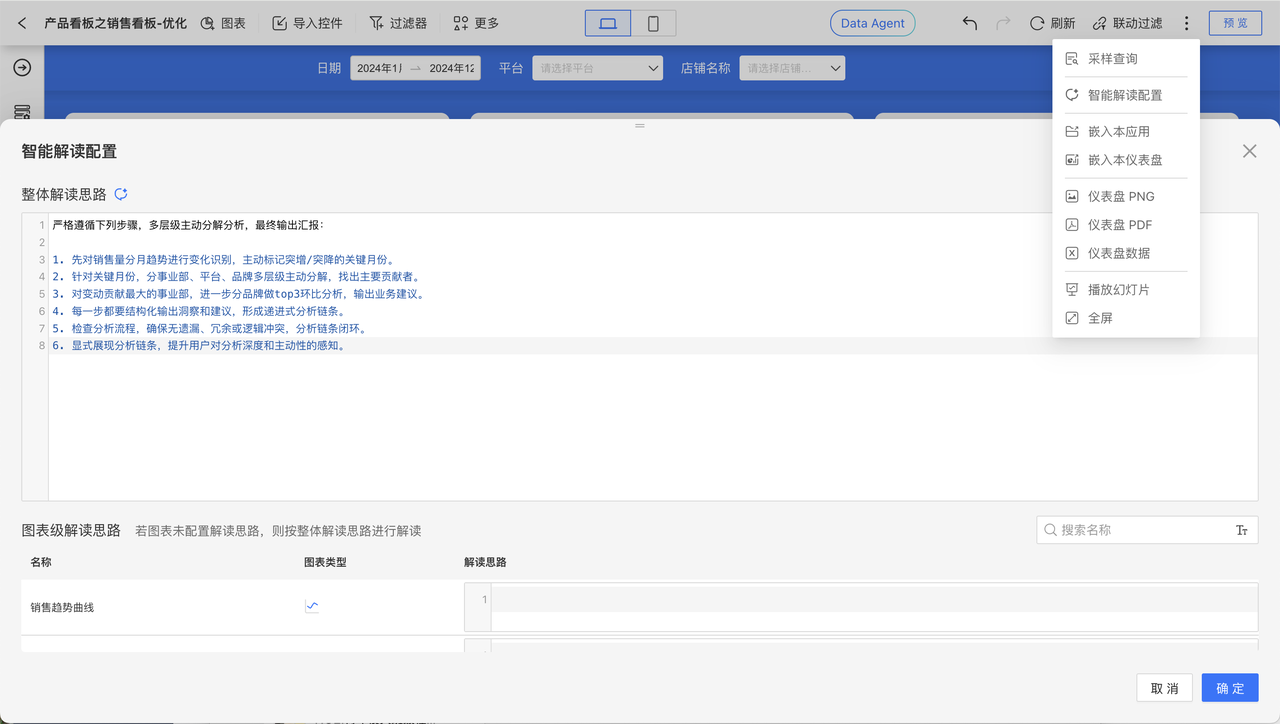
在仪表盘编辑状态时,右上角下拉菜单中可以点击弹出“智能解读配置”,其中用户可以按自己的业务需求配置固定形式的解读思路,也可以点击按钮让 AI 分析仪表盘结构和数据,生成解读思路模板。仪表盘的图表也支持各自单独配置解读思路,图表控件右上角有“智能解读”按钮,点击将会唤起 Data Agent 并发送解读指令。
智能解读功能通过人工智能技术,对用户指定的数据范围执行自动化分析,其核心能力与边界如下:
- 数据查询与提取:根据用户指令或内置分析思路,从数据源中快速定位并提取相关信息。
- 数据汇总与归纳:对查询结果进行多维度整合、统计与浓缩,揭示数据中的关键事实、规律与现状。
- 生成描述性报告:将分析结果以结构化的报告或简洁的文本总结形式输出,帮助用户理解“过去发生了什么”以及“当前情况如何”。
注意智能解读不进行预测推断,本功能严格基于已有及历史数据进行分析,其输出为对既定事实的描述与总结。它无法预测未来的数据走势、业务结果或任何尚未发生的概率性事件。
注意
复杂报表、复杂表格不支持智能解读
表达式编写
Data Agent 基于对 HQL 的理解,可以辅助用户编写复杂表达式、创建指标。
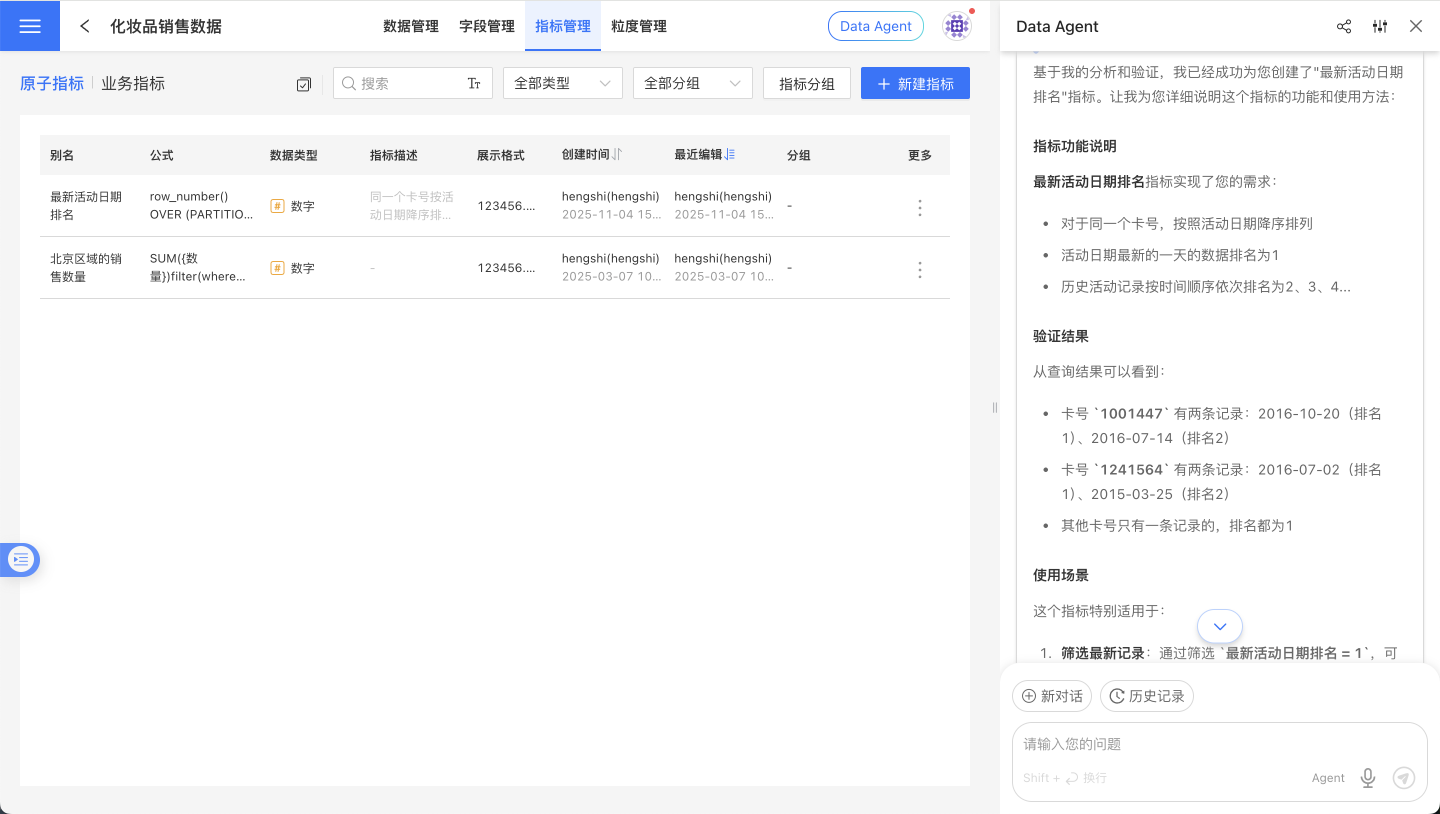
调试与调优
Agent 与 Workflow 分别支持不同的提示词指令进行效果调优,参考具体文档 Agent 调优、Workflow 调优。
集成 ChatBI
HENGSHI SENSE 提供了多种集成方式,您可以根据需求选择合适的方式。
快速选择指南
| 场景 | 推荐方案 | 开发工作量 |
|---|---|---|
| 快速集成,无需定制 UI | iframe 集成 | ⭐ 最低 |
| 自定义 UI、增强交互 | SDK 集成 | ⭐⭐⭐ |
| 与第三方应用联动 | API 集成 | ⭐⭐⭐⭐ |
| 在企业通讯工具中集成 | 数据问答机器人 | ⭐⭐ |
IFRAME 集成
最适合:前端工程师较少,快速上线的场景
使用 iframe 将 ChatBI 集成到现有系统中,实现与 HENGSHI SENSE 平台的无缝对接。直接复用衡石 ChatBI 的对话组件、样式和功能,无需额外开发。
SDK 集成
最适合:需要自定义交互逻辑或请求拦截的场景
通过 JS SDK 集成 ChatBI,提供完整的对话界面组件,同时支持自定义 API 请求、拦截请求等高级功能。
核心特性:
- 纯 JavaScript,不依赖任何框架(支持在 Vue、React 等项目中使用)
- 提供完整的对话 UI 组件,开箱即用
- 可拖拽、可调整大小的悬浮窗
- 支持自定义初始化配置(数据源、语言、主题等)
- 支持自定义请求拦截器
快速上手:
- 在系统中获取 SDK 链接:
<host>/assets/hengshi-copilot@<version>.js - 在 HTML 中引入 SDK 并初始化
- 调用 API 控制对话框的显示/隐藏
详细集成方法参考 JS SDK 文档
API 集成
最适合:与第三方应用或工作流集成的场景
通过 后端 API 将 ChatBI 能力集成到飞书、钉钉、企微、Dify Workflow 等应用中,实现定制化的业务逻辑。
Dify Workflow 工具参考附件 衡石AI工作流工具v1.0.1.zip
数据问答机器人
最适合:在企业即时通讯工具中集成数据问答的场景
通过数据问答机器人功能创建智能数据问答机器人,关联衡石 ChatBI 中的相关数据,在企业通讯工具中实现对话式数据查询。
支持的通讯工具: 企业微信、飞书、钉钉
常见问题
问数失败、报错怎么排查?
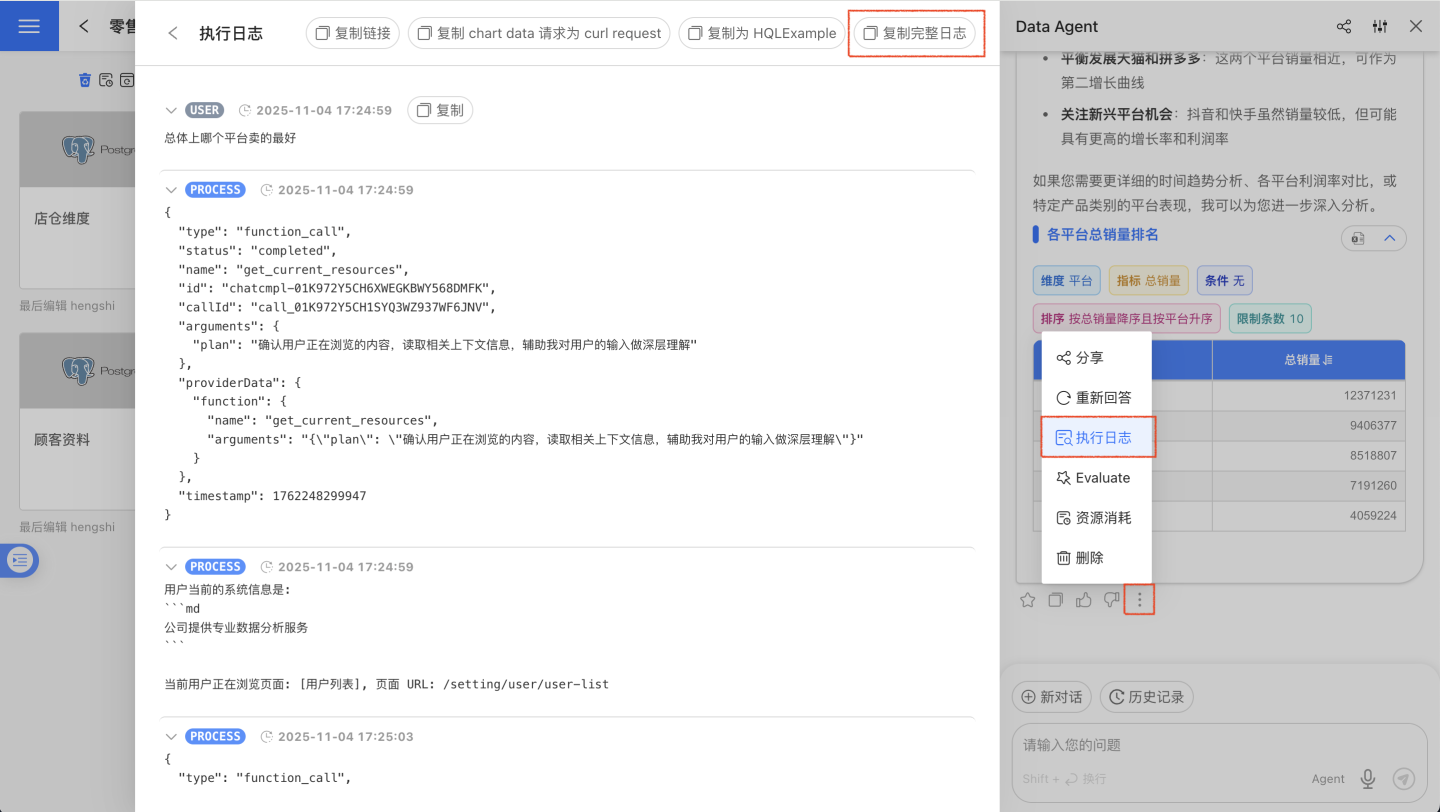
失败、报错涉及多个环节的诊断,在遇到问题时需要收集以下信息并联系售后工程师:
- 点击对话卡片下方三点菜单,点击“执行日志”,点击“复制完整日志”
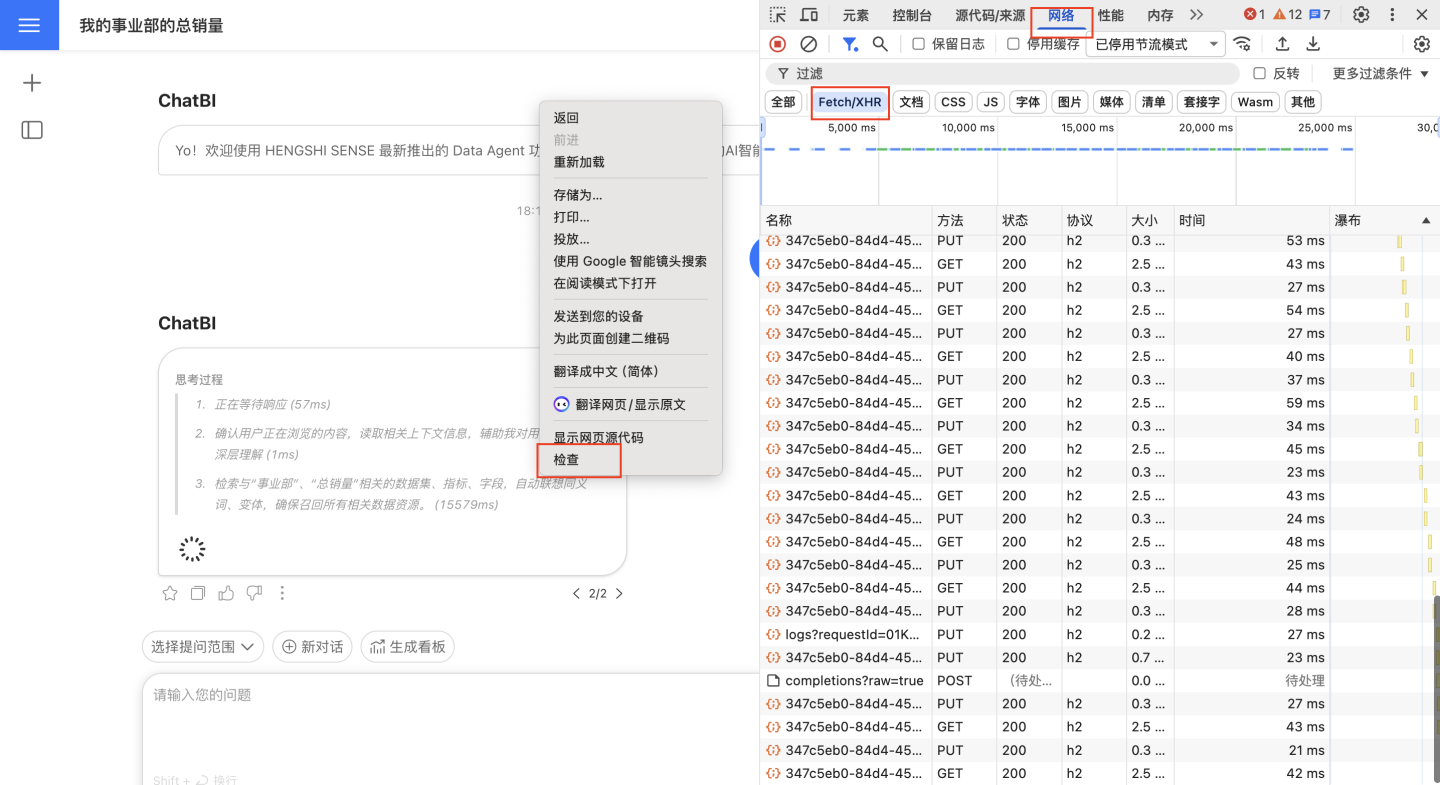
- 键盘 F12 或鼠标右键点击“检查”打开浏览器控制台,点击“网络”-“Fetch/XHR”
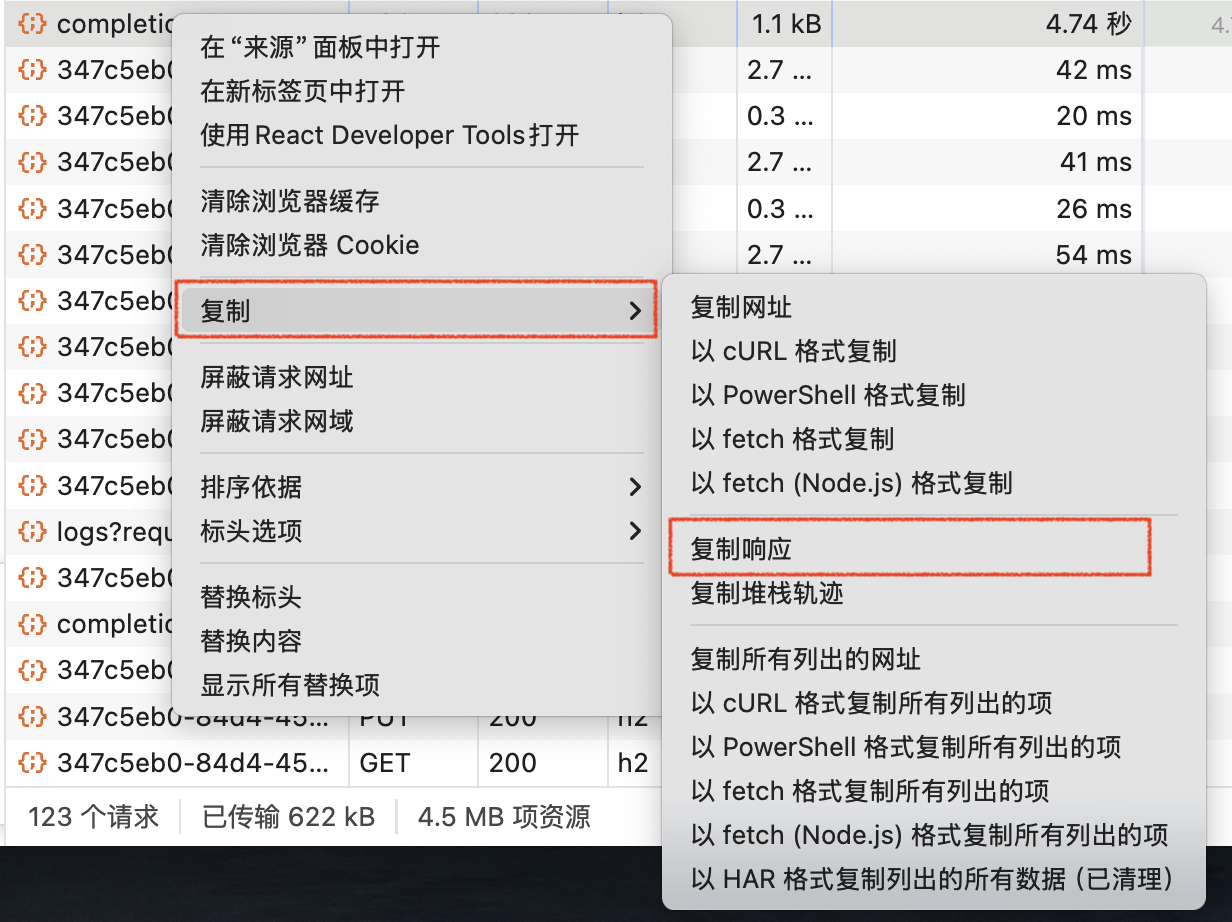
再次问数复现错误,鼠标右键出错的网络请求点击“复制”-“复制响应”
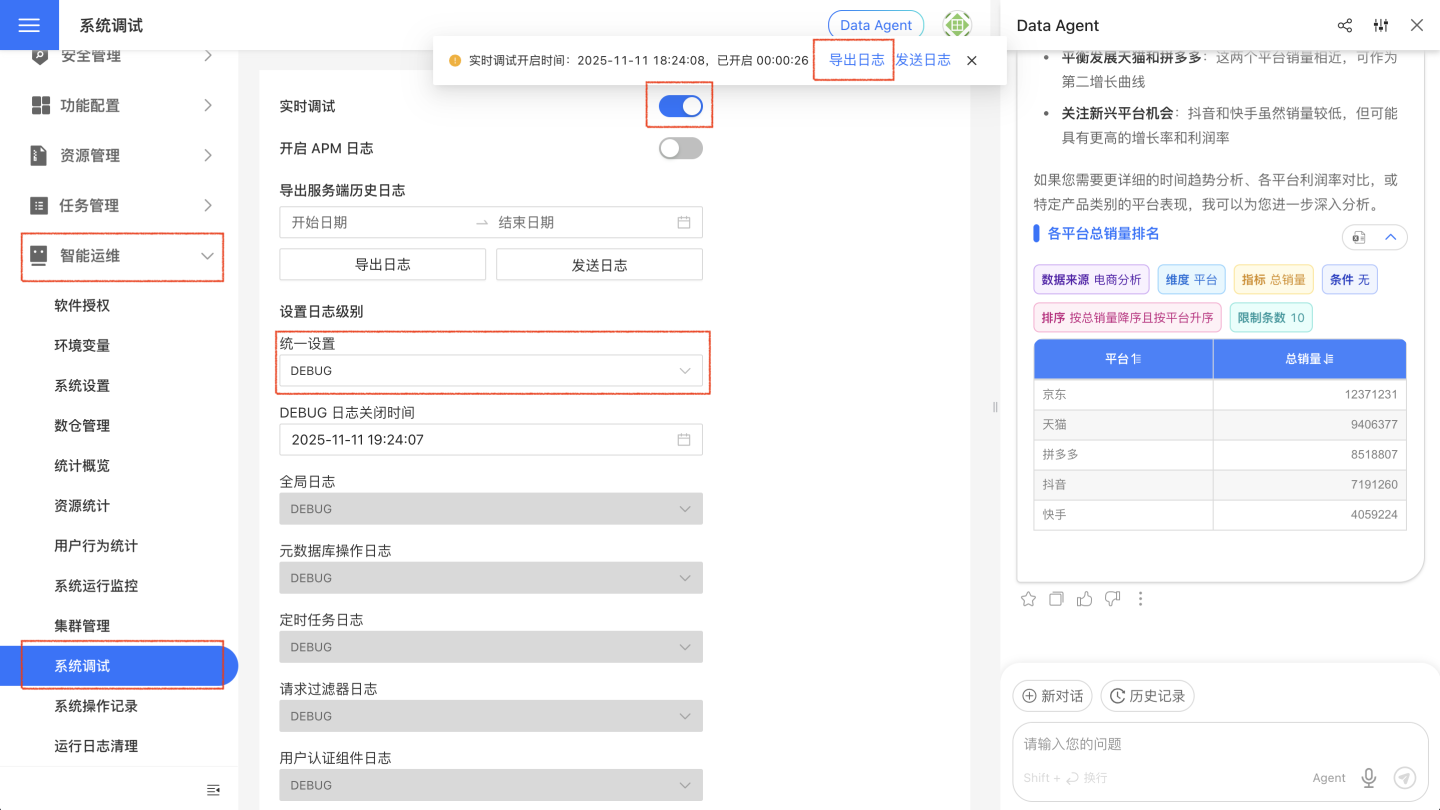
- 进入“系统设置”-“智能运维”-“系统调试”,将“统一设置”调整为“DEBUG”,打开“实时调试”,再次问数复现错误,然后点击“导出日志”
向量数据库地址怎么填?
按照AI 助手部署文档完成相关服务的安装及部署即可,无需手动填写。
是否支持其他向量模型?
目前暂不支持,如有需求,请联系售后工程师。
Data Agent 侧边栏与 ChatBI 有哪些区别?
| 能力 | Data Agent 侧边栏 | ChatBI |
|---|---|---|
| 指定数据源智能问数 | ✅ | ✅ |
| 不限数据源智能问数 | ✅ | ❌ |
| 对话图表一键生成看板 | ❌ | ✅ |
| 可视化辅助创作 | ✅ | ❌ |
| 指标辅助创作 | ✅ | ❌ |
| 智能解读 | ✅ | ❌ |
Agent 模式、Workflow 模式、API 模式之间有哪些区别?
| 能力 | Agent 模式 | Agent API 模式 | Workflow 及 Workflow API 模式 |
|---|---|---|---|
| 指定数据源智能问数 | ✅ | ✅ | ✅ |
| 不限数据源智能问数 | ✅ | ✅ | ❌ |
| 可视化辅助创作 | ✅ | ❌ | ❌ |
| 指标辅助创作 | ✅ | ❌ | ❌ |
| 智能解读 | ✅ | ❌ | ❌ |