主题
API 数据源
当用户使用 EXT API 数据时,可以通过 API 数据源将数据接入到衡石系统。 API 数据源定义统一的数据接入规范,能支持大量的无数据计算能力的 API 数据源。内置多种 API 数据源的同时支持用户自定义开发方式加入企业内部 API 数据源或其他公有 API 数据源,快速读取 API 数据源。API 数据源轻松实现接入外部 API 数据由1到 N 的快速增长,增强衡石数据的整合能力。
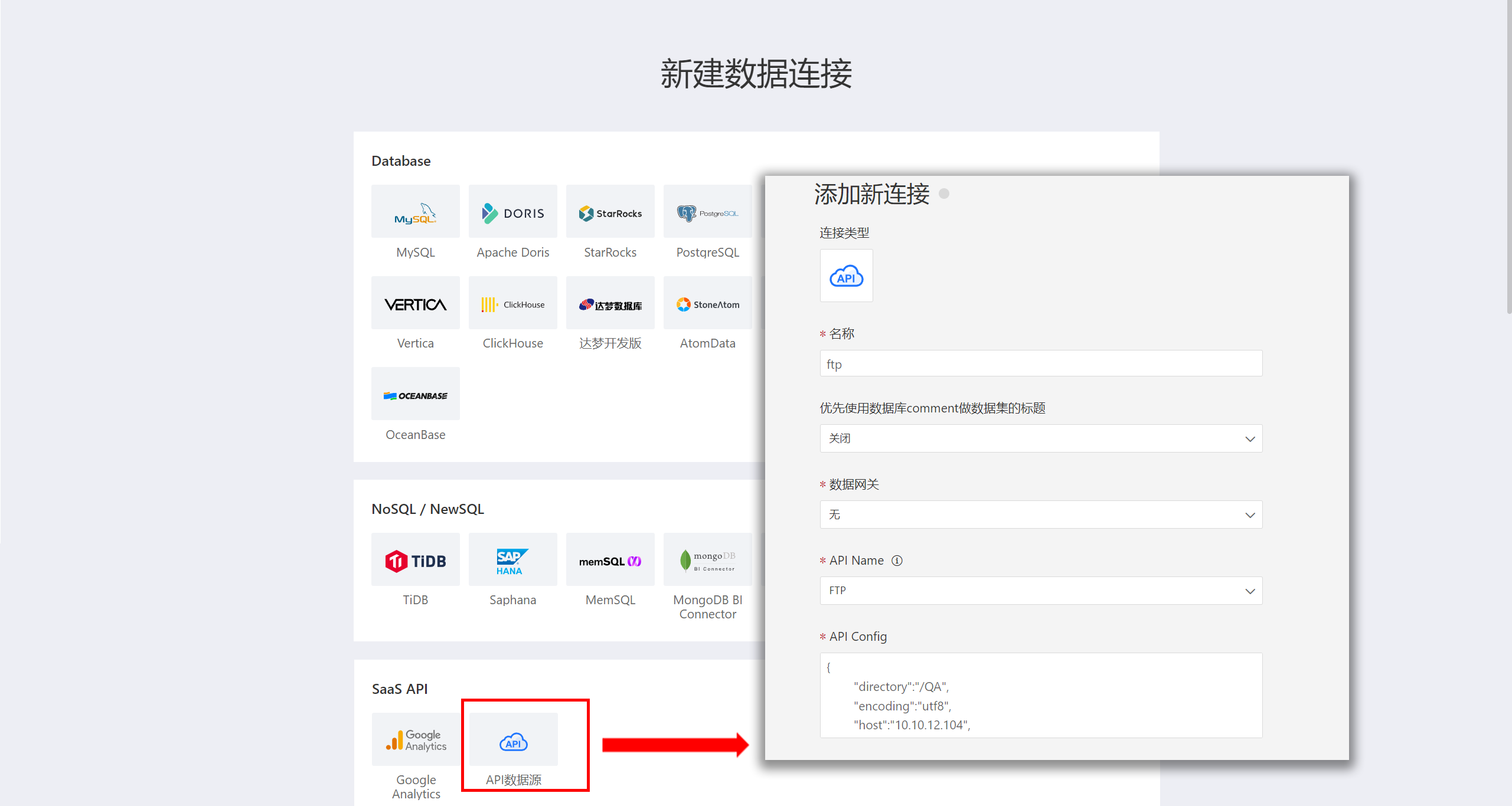
内置 API 数据源
明道云数据源
用户在明道云上的应用数据通过简单的配置就可以连接到衡石系统。配置步骤如下:
在新建数据连接中选择 API 数据源。
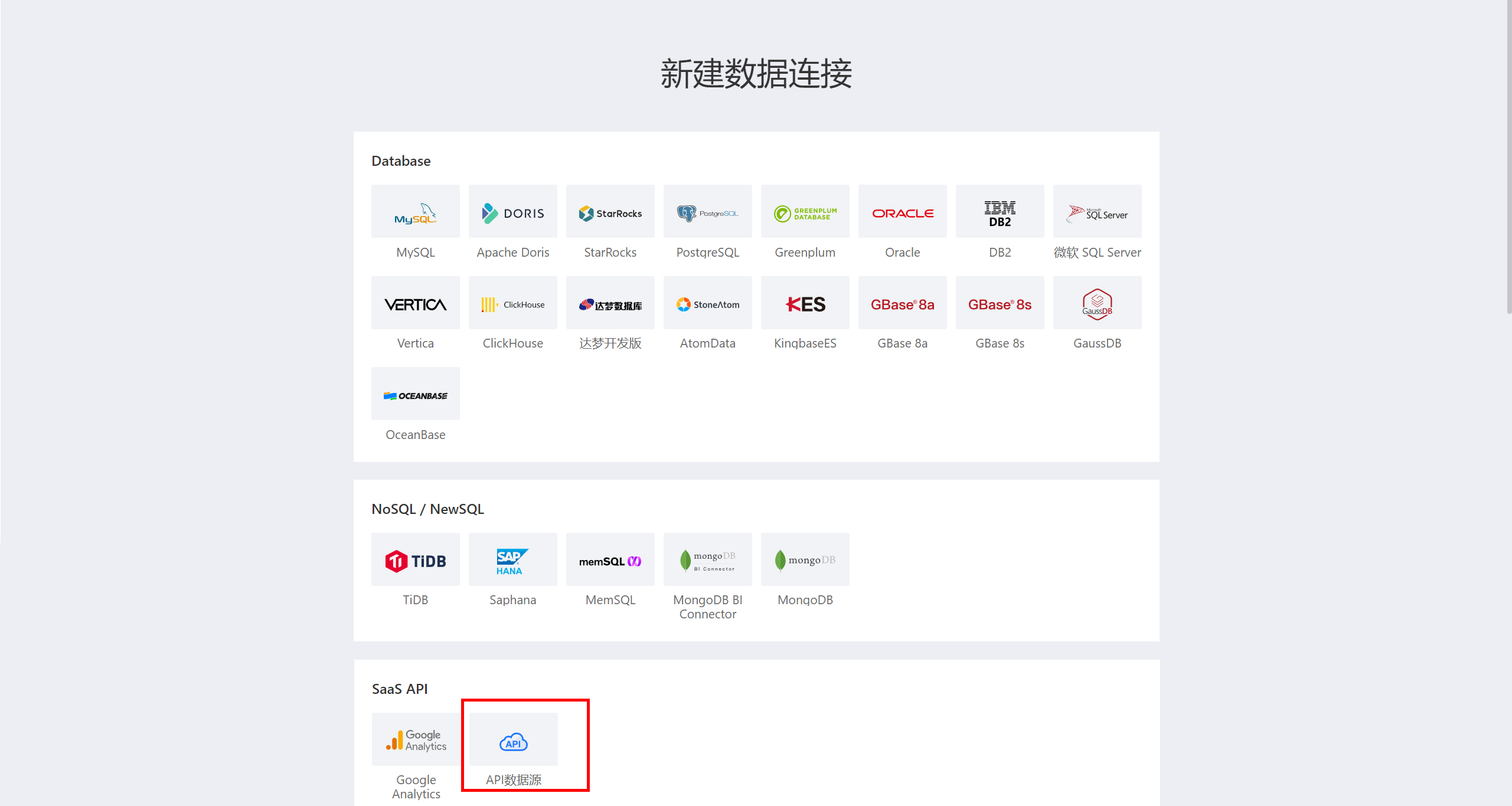
输入新建连接名称、选择数据网关、API name 选择'mingdaoyun'。
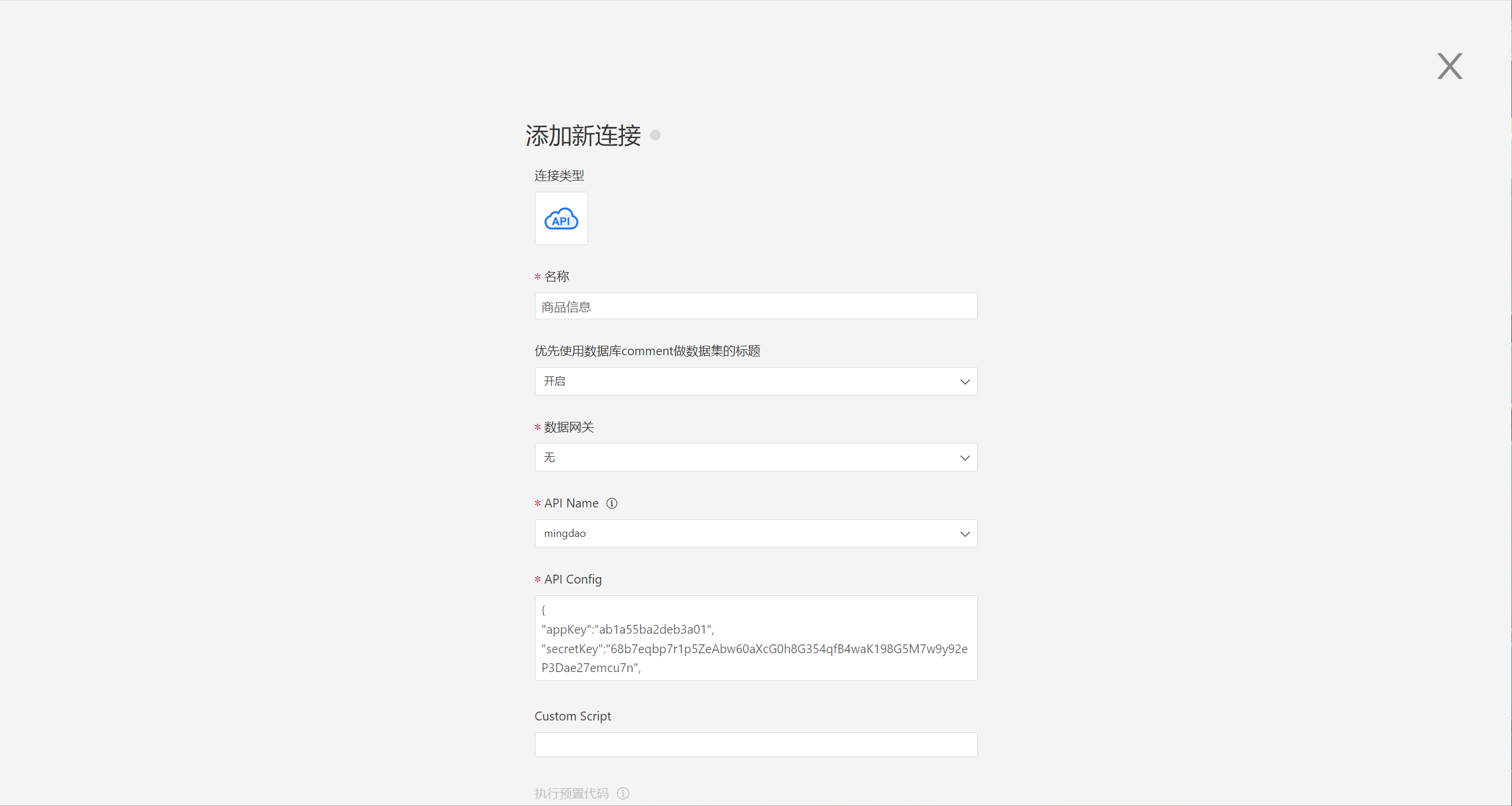
填写明道云配置信息 API Config,包括 appKey、secretKey、sign apiUrl。 其中 appKey、secretKey、sign 指的是明道云应用中的 AppKey、SecretKey、Sign。明道云为私有部署时,apiUrl 请填写私有部署地址;公有部署时 apiUrl 可置空或填写默认地址。
 json
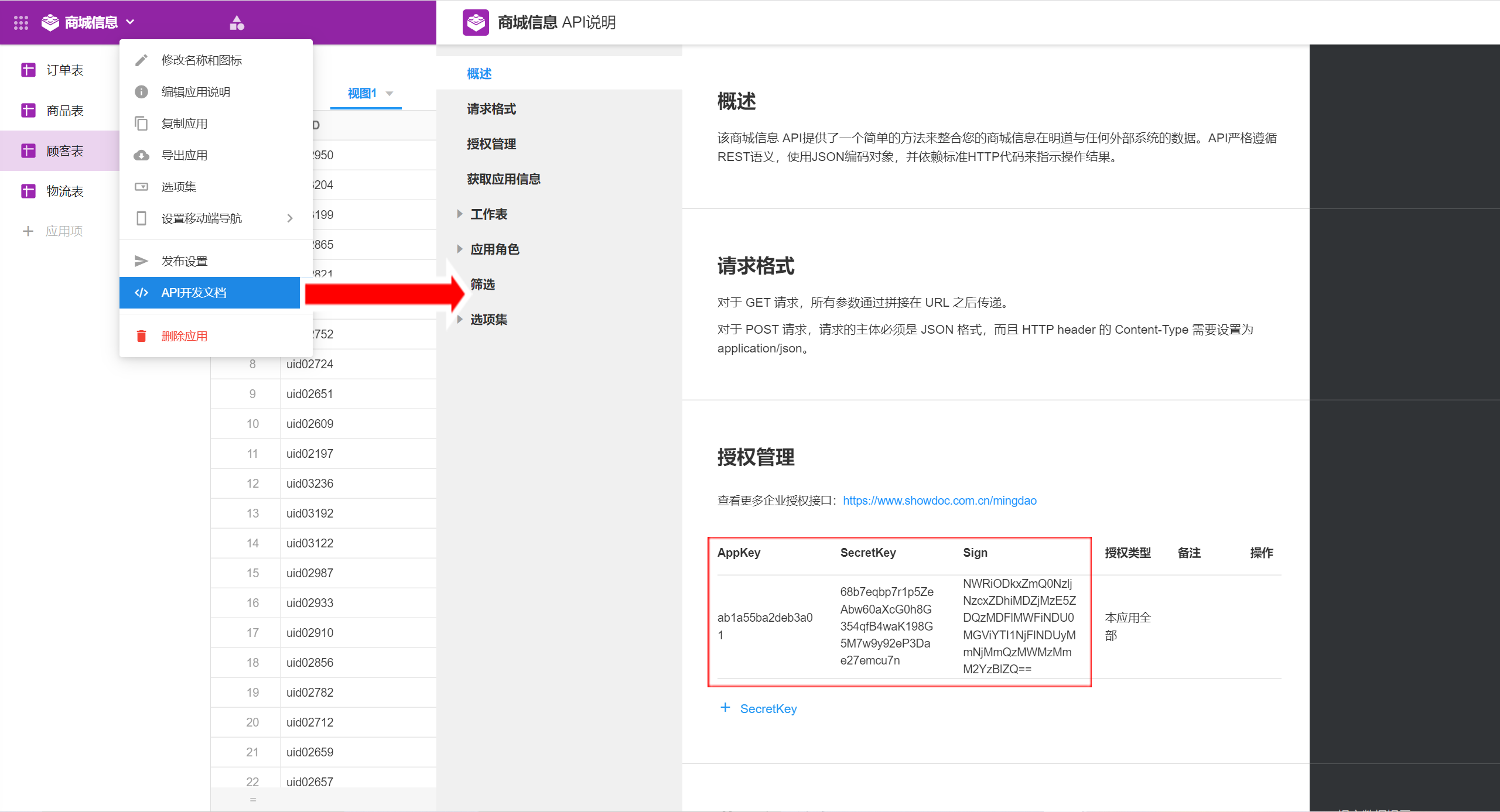
json{ "appKey":"ab1a55ba2deb3a01", "secretKey":"68b7eqbp7r1p5ZeAbw60aXcG0h8G354qfB4waK198G5M7w9y92eP3Dae27emcu7n", "sign":"NWRiODkxZmQ0NzljNzcxZDhiMDZjMzE5ZDQzMDFlMWFiNDU0MGViYTI1NjFlNDUyMmNjMmQzMWMzMmM2YzBlZQ==", "apiUrl": "https://api.mingdao.com/v2/open" }验证成功后,点击保存,数据连接创建完成。在系统中可以查看和使用明道云中的数据。
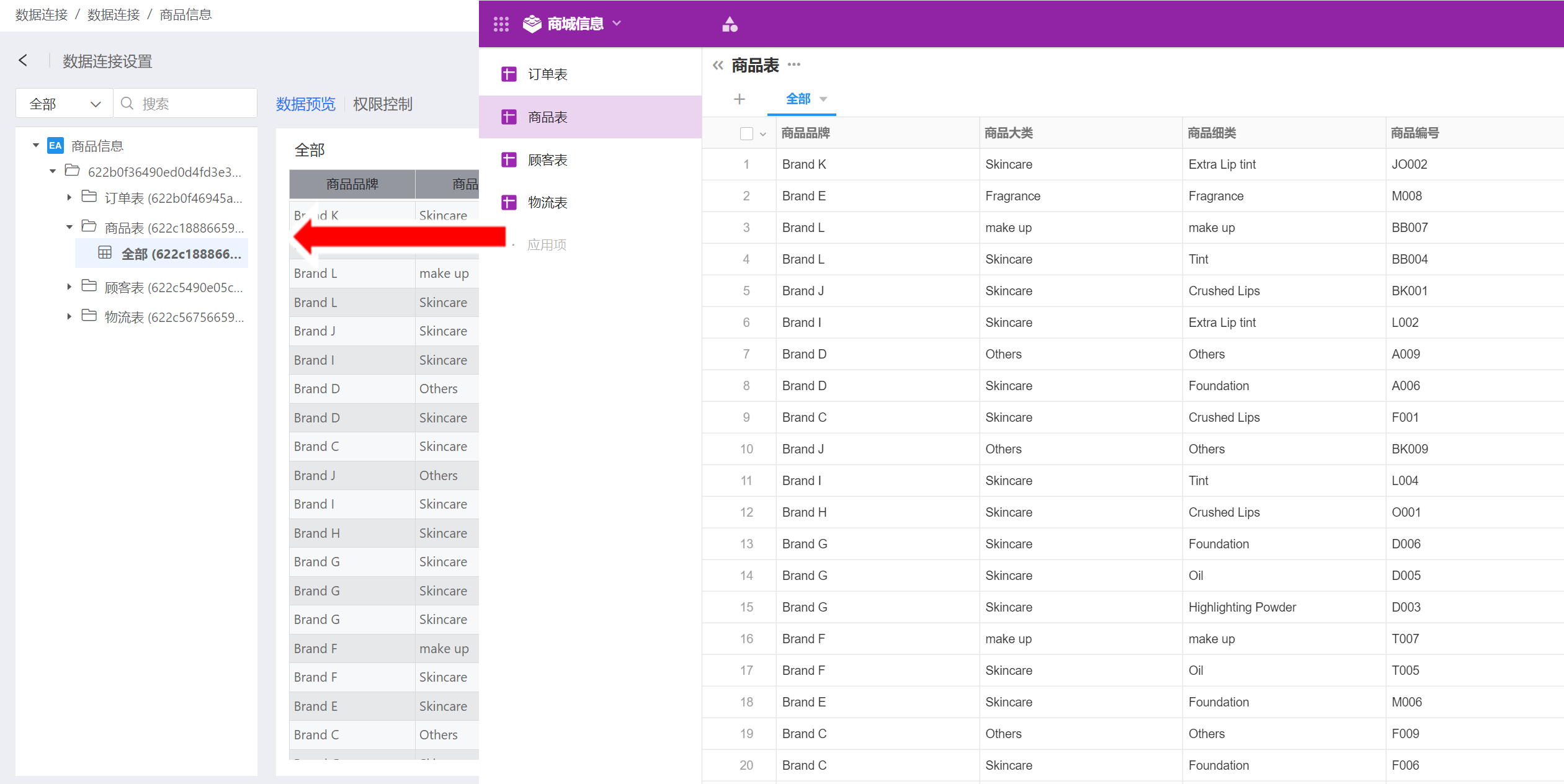
FTP 数据源
系统支持 FTP 数据源,在 HENGSHI SENSE 中通过简单配置,可以读取 ftp 指定路径下的文件。 配置步骤如下。
- 在新建数据连接中选择 API 数据源。
- 输入新建连接名称、选择数据网关、API name 选择'ftp',填写 ftp 配置信息,将 host、username、password、directory、encoding、passive 等信息填入到配置中。json
{ "host":"10.10.10.86", "username":"anonymous", "password":"anonymous", "directory":"/", "encoding":"utf8", "passive":true, }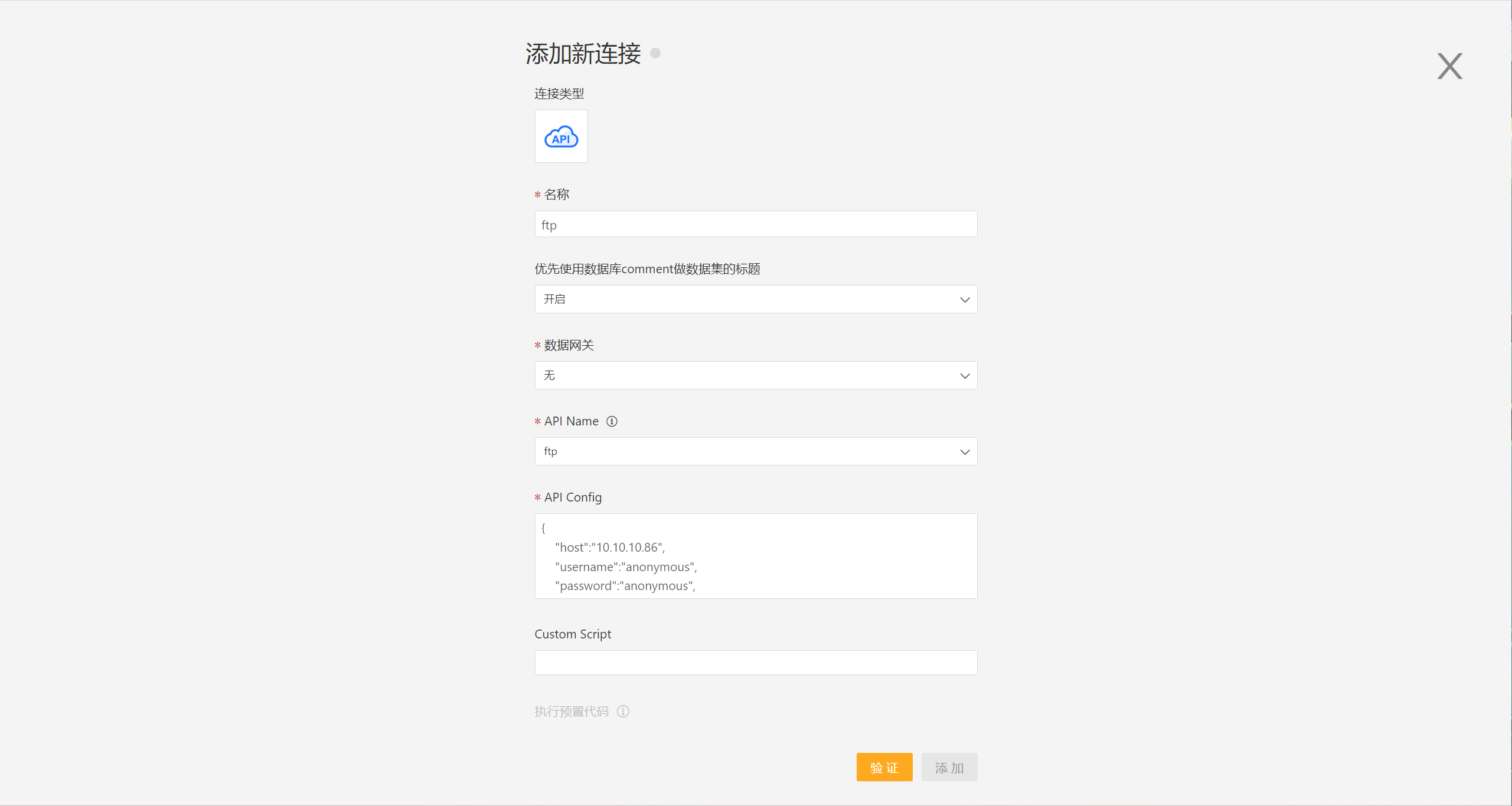
- 验证成功后,点击保存,数据连接创建完成。在系统中可以查看和使用连接数据。
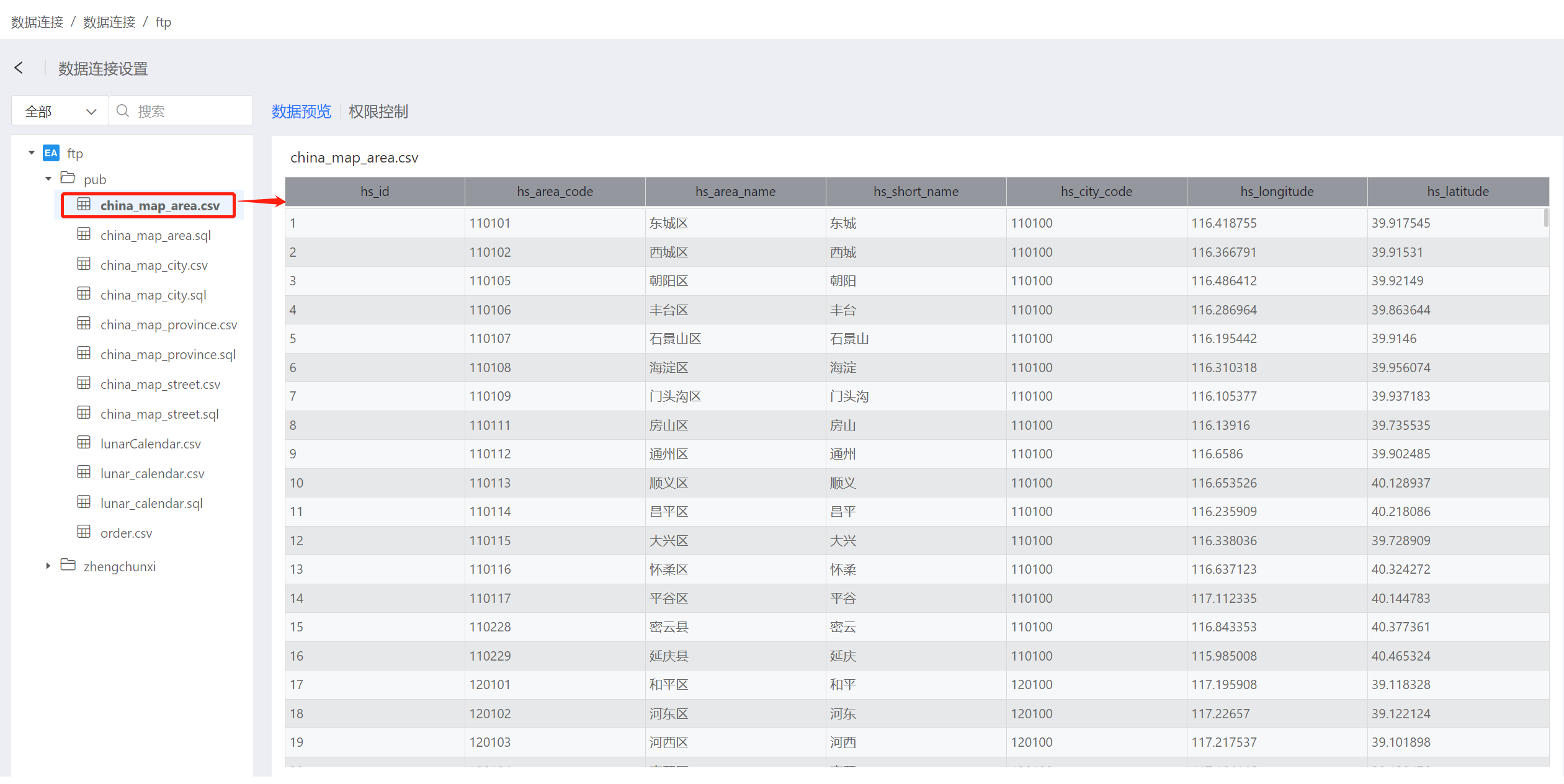
提示
FTP 数据源只能将 csv 和 excel 解析为表的形式,其他类型的文件不支持解析。
其他内置数据源
除了上述 FTP 和明道云外,系统还支持 S3、旺店通、企业微信、石墨文档、聚水潭、易仓科技、外勤等 API 数据源,用户配置 API config 后,即可将数据接入到衡石系统中。
自定义 API 数据源
除了内置的 API 数据源外,系统支持用户自定义 API 数据源,可以使用以下两种方法自定义 API 数据源。
- 自定义 API 数据源为内置数据源
- 系统直接接入自定义 API 数据源
自定义 API 数据源为内置数据源
自定义 API 数据源为内置数据源,是指将自定义 API 数据源的 Groovy 脚本载入到衡石系统中,系统启动会自动载入脚本中定义的数据源。 用户可以在下拉框中找到自定义的 API 数据源,其使用方法与内置 API 数据源一样。
自定义 API 数据源载入系统
按照规范编写自定义 API 数据源的 Groovy 脚本,通过环境变量 EXT_API_PATH 指定脚本位置,然后重启系统。
export EXT_API_PATH=/opt/hengshi/ext_api_files系统在启动过程中会自动扫描 EXT_API_PATH 指定的路径下所有数据源定义文件(以.groovy 后缀结尾的文件),并且加载到 API 数据源中。在 API 数据源创建时就能看到相应的数据源了,使用时与内置数据源使用方法一样。 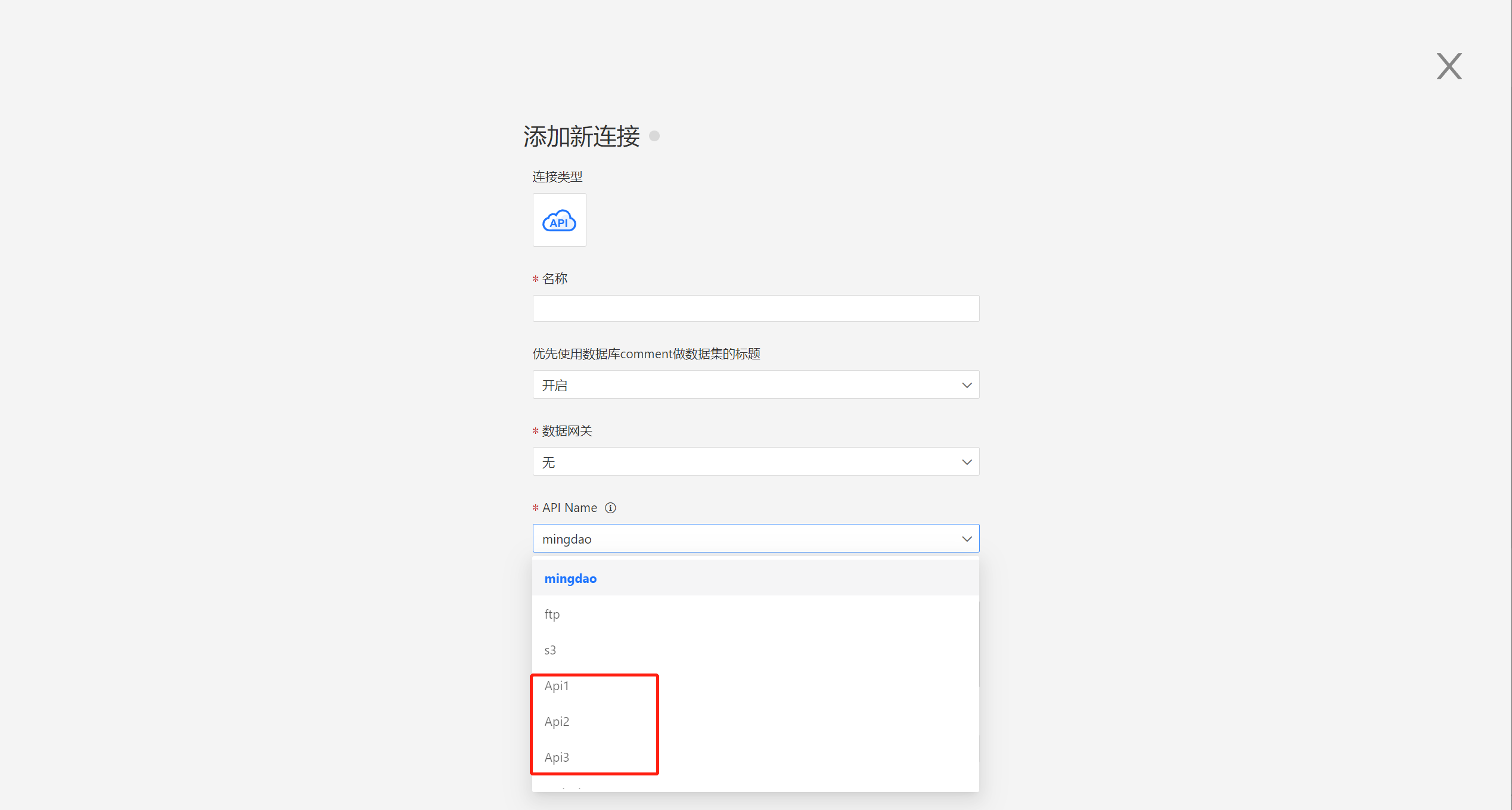
API 数据源接入规范
自定义数据源接入时,需要在 Groovy 脚本中实现下面四个接口。
- getAPIName : 用来获取 API 名称。
- setOptions:用来处理认证鉴权相关配置信息。
- fetchPathTables:用户获取数据源目录结构。
- fetchTableData : 用于获取 table 节点数据。
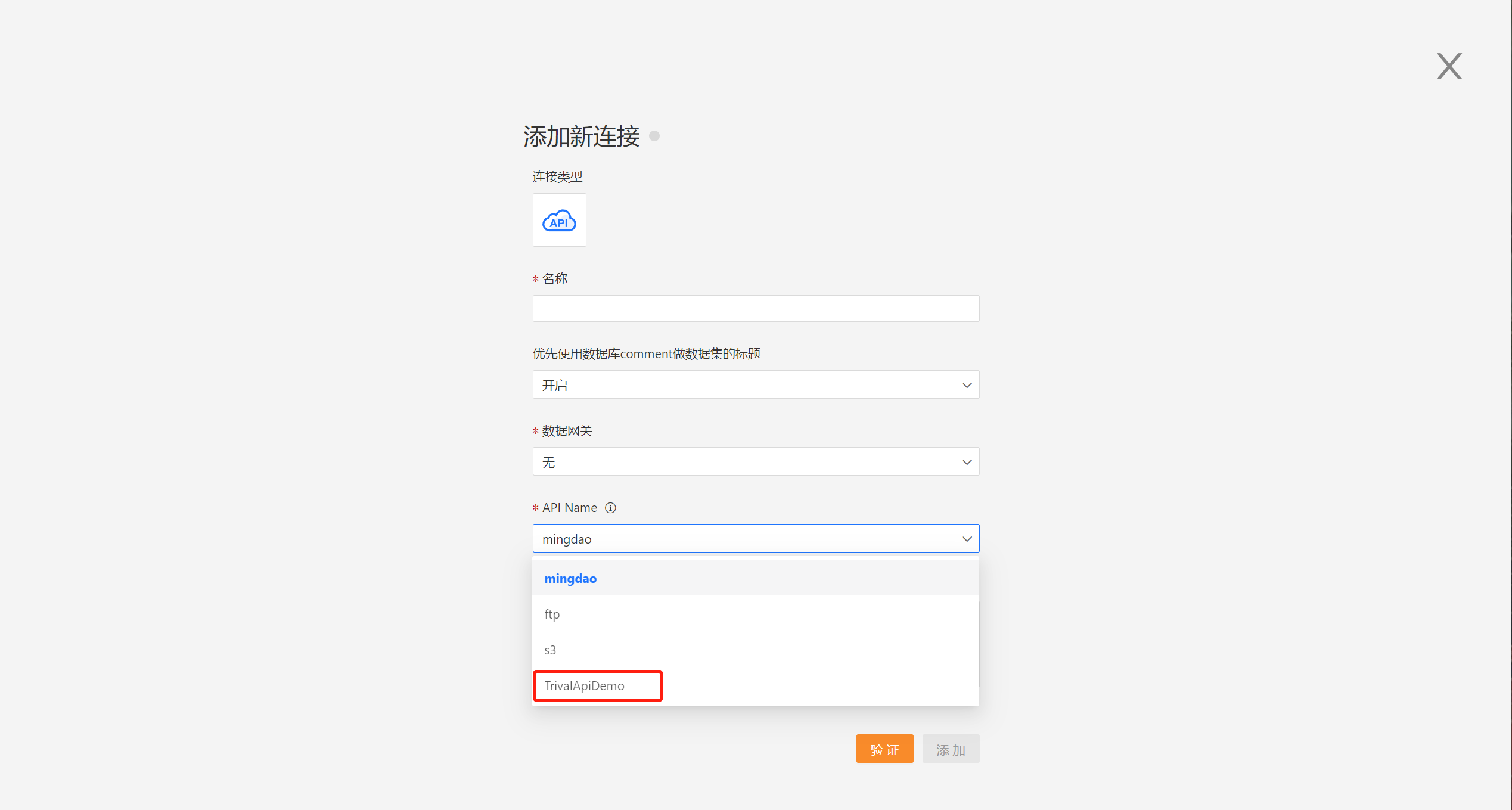
函数 getAPIName
函数 getAPIName 的作用是输出 API 名称。该名称会出现在页面的 API Name 下拉选择框中。 每一个 API 数据源名称不能相同,如果相同会导致发生冲突。 该函数是类 static 函数,返回值为 string 类型的字符串。
groovy
static getApiName() {
return "TrivalApiDemo"
}
函数 setOptions
函数 setOptions 的作用是用来保存处理认证鉴权相关的配置信息。 如果不涉及外部网络请求,可以直接留空了。 该函数是 object 函数, 函数参数是一个 JSON 字符串,这个字符串是用户在添加数据连接时填写的信息。
groovy
def setOptions(String options) {
if (!options?.trim()) {
return
}
def json = jsonSlurper.parseText(options)
if (json.cityCodeURL?.trim()) {
config.cityCodeURL = JSON.cityCodeURL
}
if (json.weatherURL?.trim()) {
config.weatherURL = JSON.weatherURL
}
}函数 getPathTables
函数 getPathTables 的作用是返回目录树,把该数据源的所有 catalog/schema/table 的结构都返回。 代码示例如下。
groovy
def getPathTables() {
def tableTree = [
[pathType: "table", name: "table1", tableType: "table"],
[pathType: "path", name: "schema2", children: [
[pathType: "table", name: "table3", tableType: "view"],
[pathType: "table", name: "table4", tableType: "table", remarks: "表别名4"]
]]
]
return new JsonBuilder(tableTree).toString()
}结构定义说明:
- pathType 的种类有 table(代表叶子结点的表), path(代表数据库中的 schema 或者 catalog)
- name 就是 表名或者 schema/catalog 的名字
- tableType 只对 table 有意义,它的类型一般写成 table 就可以了(另外一个选项是 view,不常用)
- 当 pathType 为 path 时,代表这个节点不是一个表,而是一个 schema 或者 catalog 这样的中间目录结构,此时它可以有 children 数组节点
- remarks 是当前节点的一个说明,需要的时候可以提供,是可选项。
通过上面的函数定义的 schema, 可以在数据连接中查看如下的 table。
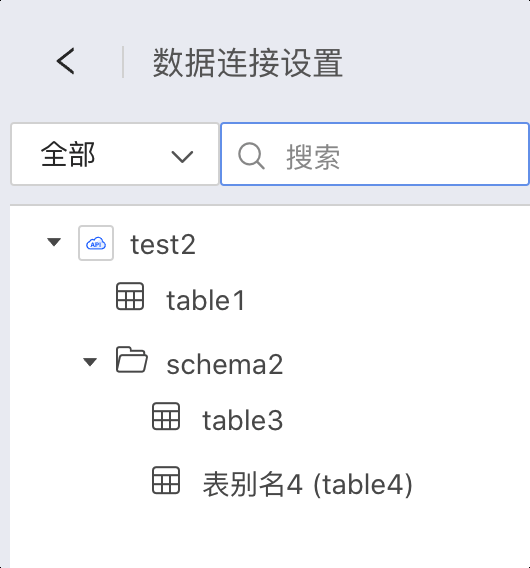
函数 fetchTableData
函数 fetchTableData 函数的作用是获取一个叶子节点,即 table 节点的数据。代码示例如下。
groovy
def fetchTableData(List<String> tablePath) {
def tableName = tablePath.last()
def schemaData = [
schema: [
[fieldName: "field1", label: "字段别名1", type: "string"],
[fieldName: "field2", label: null, type: "string"],
[fieldName: "field3", type: "number"],
[fieldName: "field4", type: "date"],
[fieldName: "field5", type: "time"]],
data: [
["a", "b", 10, "2022-01-01", "2022-01-01 23:59:59"],
["c", "d", 20.20, "2019-12-39", "2019-12-39 23:59:59"]
]
]
return new JsonBuilder(schemaData).toString()
}Schema 结构定义:
- fieldName 字段名,需要在 table 内具有唯一性,能区分不同的字段。
- type:字段的类型,常用的类型有:string, number, date, time, json, bool。
- label:字段的别名。
Data 结构定义:
- data 的每一个元素都是一个数组,数组的元素个数必须和 schema 相同,数据的类型也必须一一匹配。
通过上述示例,可以返回的数据如下。 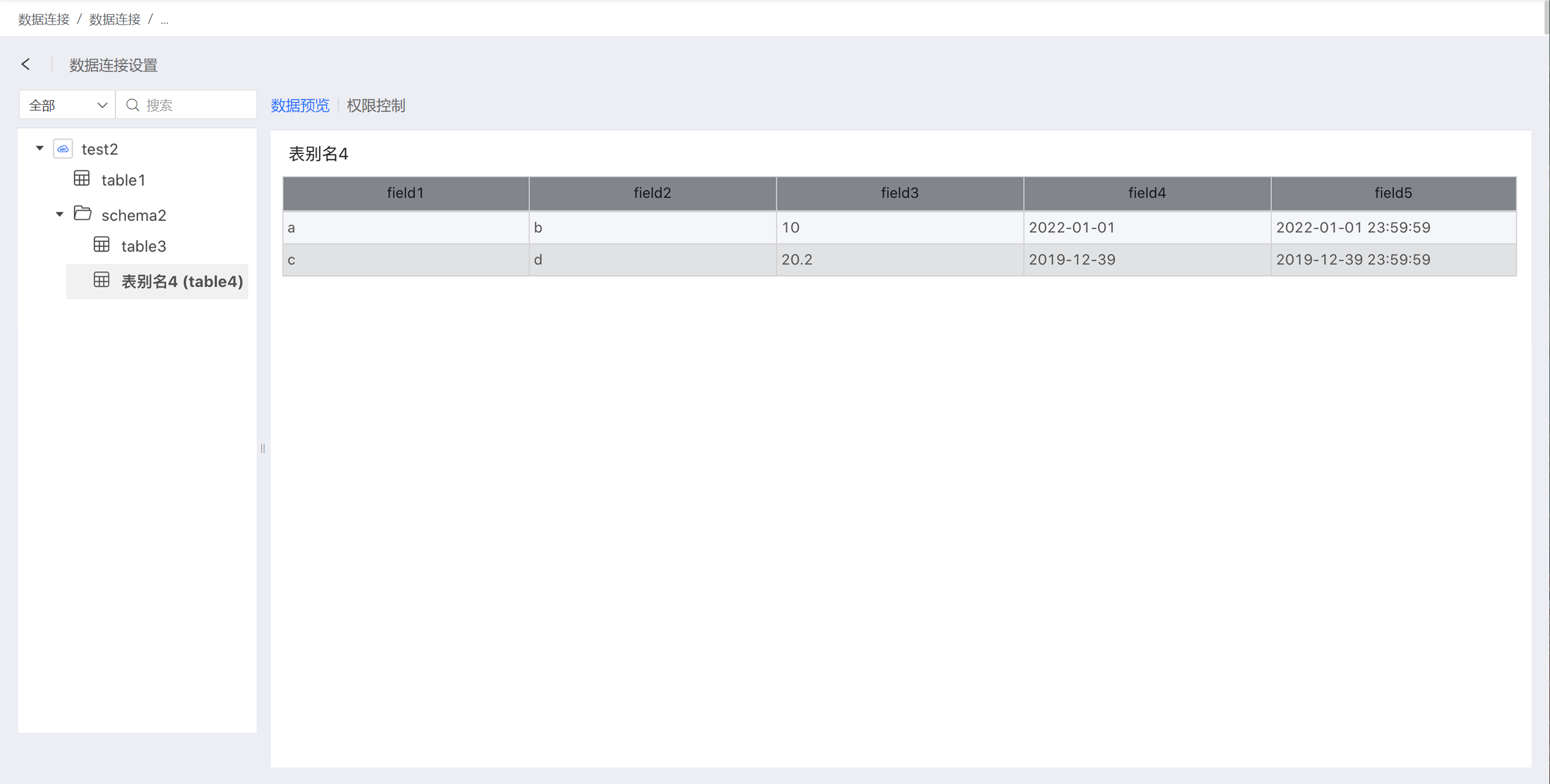
API 数据源定义文件方式
API 数据源定义文件方式有很多种,上面示例是使用 JSON 方式定义一个 API 数据源,这种方式简单,但是性能不高,当数据量较大时,可以使用 Java 方式。 下面使用 Java 构造一个天气 API 自定义数据源。weather.groovy 文件定义内容如下。
groovy
//Weather.groovy
import com.hengshi.nangaparbat.dto.DatasetResultDto
import com.hengshi.nangaparbat.model.PathTableNode
import static com.hengshi.nangaparbat.model.Dataset.Field
import static com.hengshi.nangaparbat.model.Type.TypeName
import groovy.json.JsonSlurper
class Provider {
static getApiName() {
return "天气 API"
}
def setOptions(String options) {
if (!options?.trim()) {
return
}
def json = jsonSlurper.parseText(options)
if (json.cityCodeURL?.trim()) {
config.cityCodeURL = json.cityCodeURL
}
if (json.weatherURL?.trim()) {
config.weatherURL = json.weatherURL
}
}
def getPathTables() {
def txt = config.cityCodeURL.toURL().text
def arr = jsonSlurper.parseText(txt)
return arr.collect{ obj ->
def node = PathTableNode.createTableNode(obj.city_code)
node.setRemarks(obj.city_name)
return node
}
}
def fetchTableData(List<String> tablePath) {
def url = config.weatherURL + tablePath.last()
def txt = url.toURL().text;
def result = new DatasetResultDto()
def schema = []
def data = []
def row = []
def arr = jsonSlurper.parseText(txt)
arr.data.each{ k, v ->
def field = new Field();
field.setFieldName(k)
field.setType(TypeName.string)
if (k.startsWith("pm")) {
field.setType(TypeName.integer)
}
schema.add(field)
row.add(v);
}
result.setSchema(schema)
data.add(row)
result.setData(data)
return result
}
def jsonSlurper = new JsonSlurper()
def config = [
cityCodeURL: "https://github.com/baichengzhou/weather.api/raw/master/src/main/resources/citycode-2019-08-23.json",
weatherURL: "http://t.weather.itboy.net/api/weather/city/"
]
}代码说明:
- DatasetResultDto 定义了 fetchTableData 的返回结果,它由 schema 和 data 组成,通过 setData 和 setSchema 来写入。
- PathTableNode 定义了 getPathTables 的返回,它由 pathType, name, children 和 tableType 组成,也是通过各自的 setter 来写入
- schema 由多个 Field 组成,Field 由 fieldName, type 和 label 组成。
- type 的种类是一个枚举类型定义的 TypeName。
- CityCode中定义了目录结构。
- 天气网站是天气数据来源,记录了各个城市的天气数据。
使用上述示例代码定义了天气 API 数据源,将 weather.groovy 导入系统后,获取 API 数据。

直接接入自定义 API 数据源
系统可以直接接入自定义 API 数据源,如图所示,新建 API 数据源在 API name 中选择自定义,然后将自定义 API 数据源的 Groovy 脚本,存放到 Custom Script 中,点击验证,添加即可。
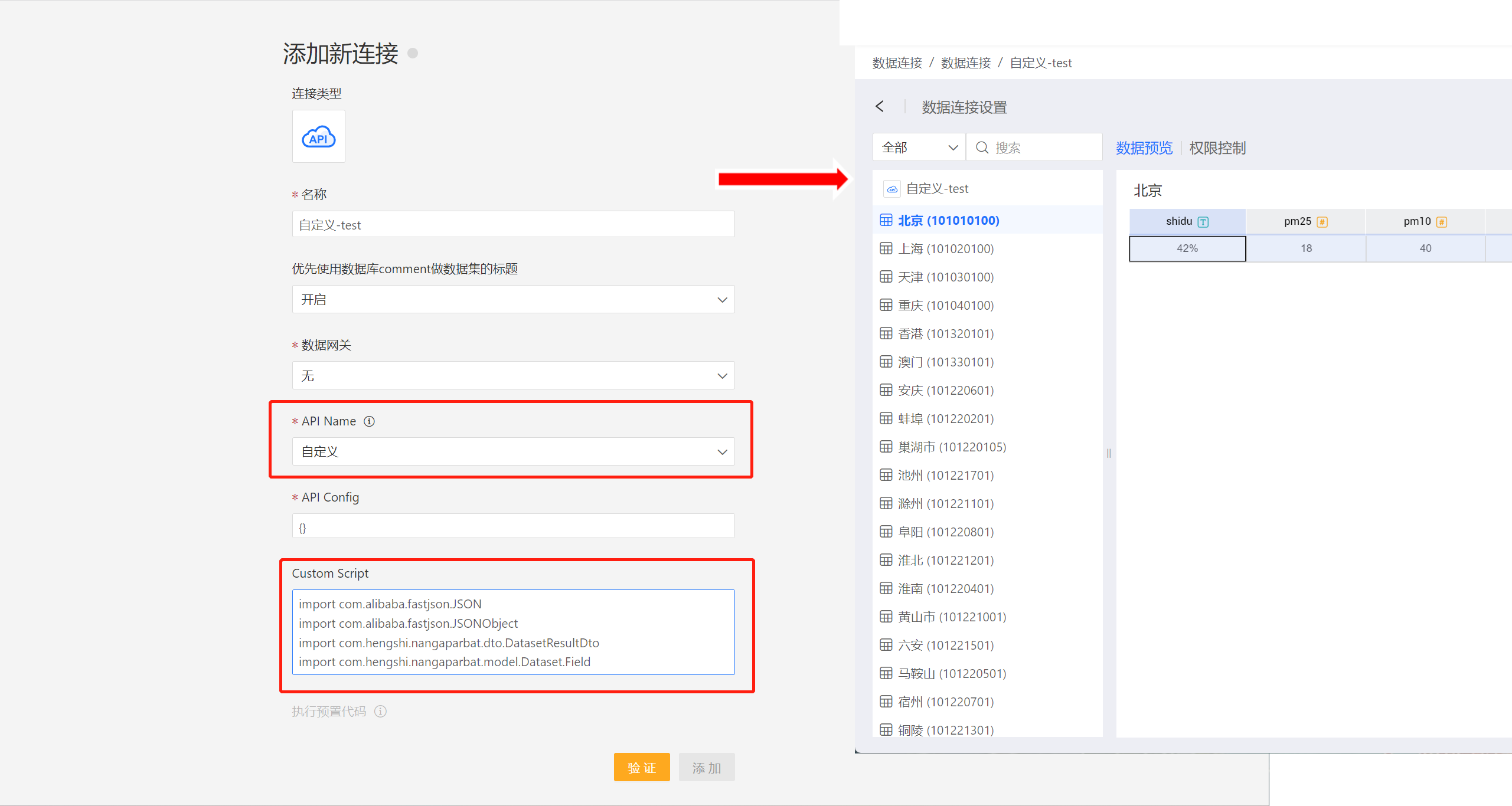
这种方式无须系统重启即可将自定义 API 数据源接入到系统中,操作比较方便。 但是每次新建数据连接时都需要输入 Custom Script。