1. 数据模型
数据模型,即关联关系模型,可以在数据集之间建立join或者union 的关系,并在作图时带入这些关系。
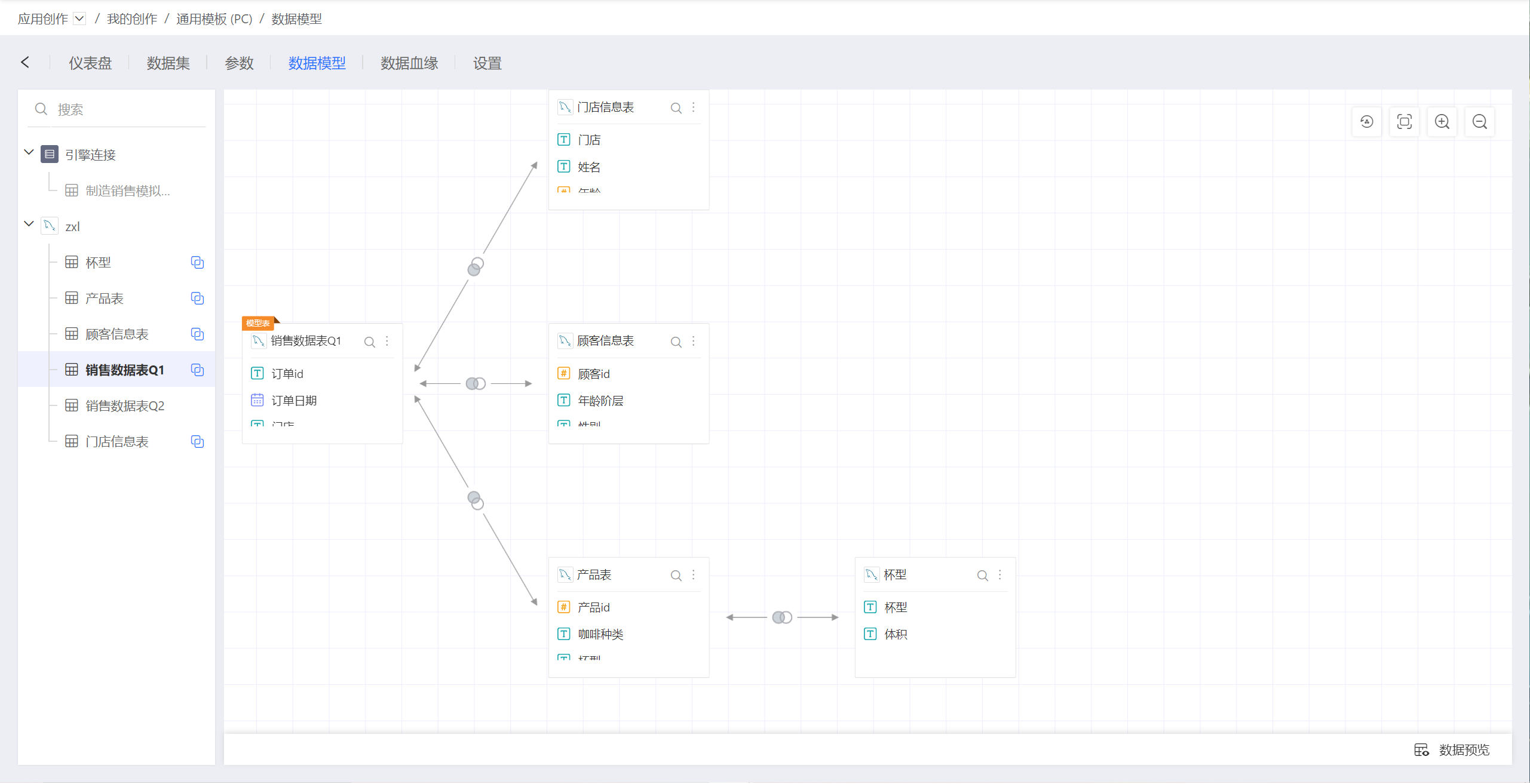
数据模型有以下功能:
- 支持数据集追加,比如每月追加新的销售数据
- 支持数据集复用:在一个数据模型中,可以将一个数据集多次拖入,建立不同的关联关系,可以实现数据集自关联,使用单个字典表扩展成带有层次结构的字典表
- 支持跨数据集建立指标:模型表可以使用与之关联的关联数据集创建指标
- 关联条件支持表达式:允许用户自由编写关联条件,比如模糊匹配等
与此同时,引入新的概念:
- 模型表:选中一个数据集,围绕该数据集建立各种关系,这个数据集称为模型表。
- 关联表:在数据模型中与模型表建立关联关系的数据集。
一个数据集在参与其他模型表的关联关系时,身份是“关联表”,在自己的数据模型中,身份是“模型表”。作图时选择数据集,就会带入以该数据集为模型表的整个数据模型。
只支持处于同一连接下的同源数据集建立数据模型。 一个图表只能使用一个数据模型,不能跨数据模型作图。
1.1. 新建关系
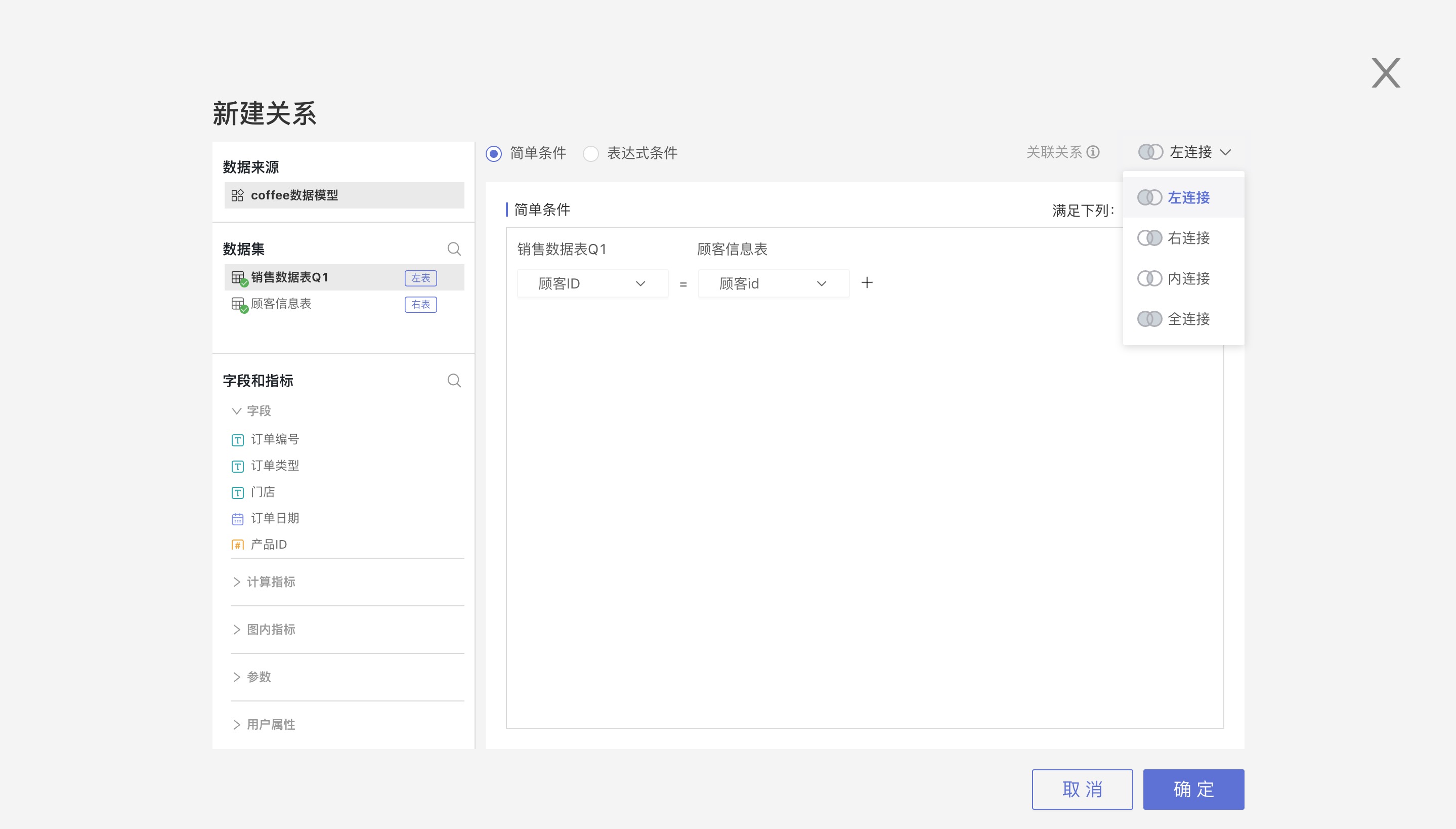
在数据模型区域,点击一个数据集,然后将左侧列表中的数据集拖到该数据集上,就会弹出新建关系弹窗,在弹窗中,可以设置:
- 关联关系:内连接、左连接、右连接、全连接
- 关联条件:简单条件、表达式条件
- 关联基数:一对一、一对多、多对一、多对多
1.1.1. 关联关系
关联关系指的是数据集join方式,包括以下四种:
- 内连接:只返回两张表中完全匹配的行
- 左连接:返回左表所有的行,无论是否匹配右表
- 右连接:返回右表所有的行,无论是否匹配左表
- 全连接:返回左连接结果和右连接结果的并集
部分数据库由于自身限制,不支持full join,比如mysql 5、tidb等,创建模型时会有相应提示。
1.1.2. 关联条件
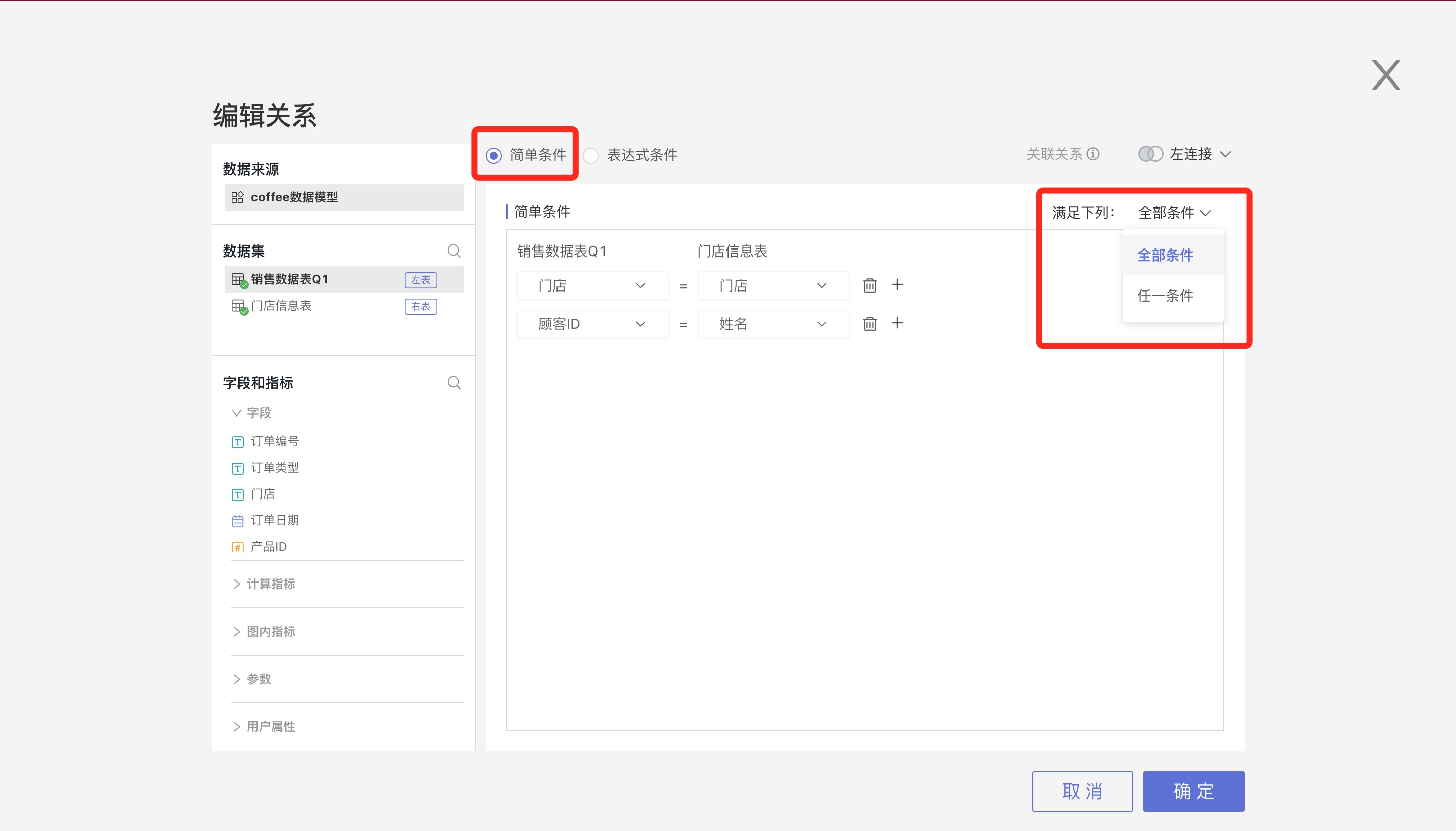
关联条件有简单条件和表达式条件两种设置方式。
简单条件的多个条件之间有两种关系:任一条件(OR)和全部条件(AND)。
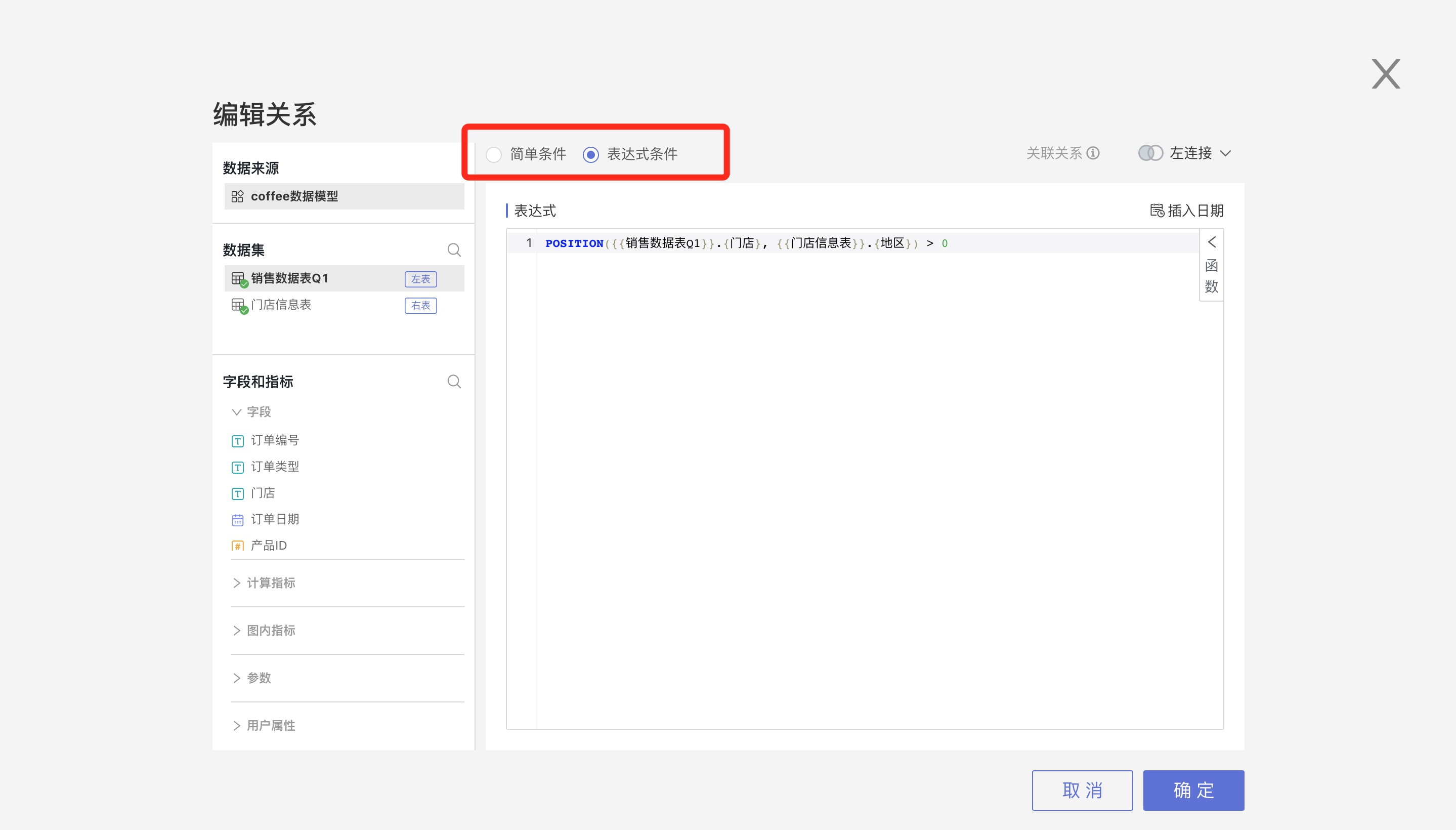
表达式条件支持用户自由编写关联条件,可以是字段a>字段b,也可以是like(字段a,字段b),如下:
1.1.3. 关联基数
在数据模型中关联基数类型的作用是避免因数据膨胀导致分析失真。示例中展现了关联基数为一对一建模时数据膨胀的情况,膨胀的数据会导致分析严重失真。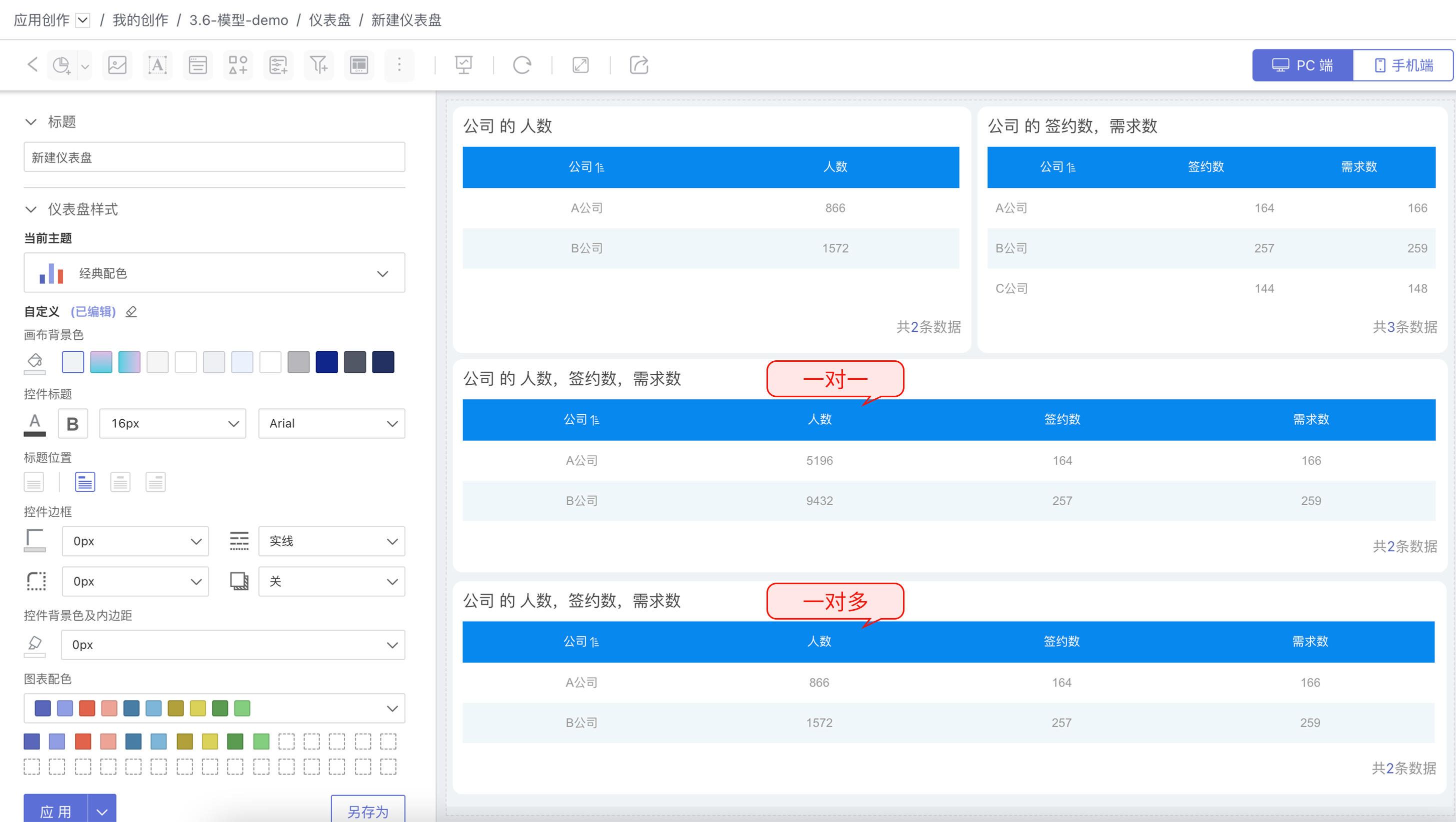
所以在数据建模时用户要根据业务实际情况,选择表格关联基数。 基数基数包括一对一 、一对多、多对一、多对多四种类型,默认设置为一对一。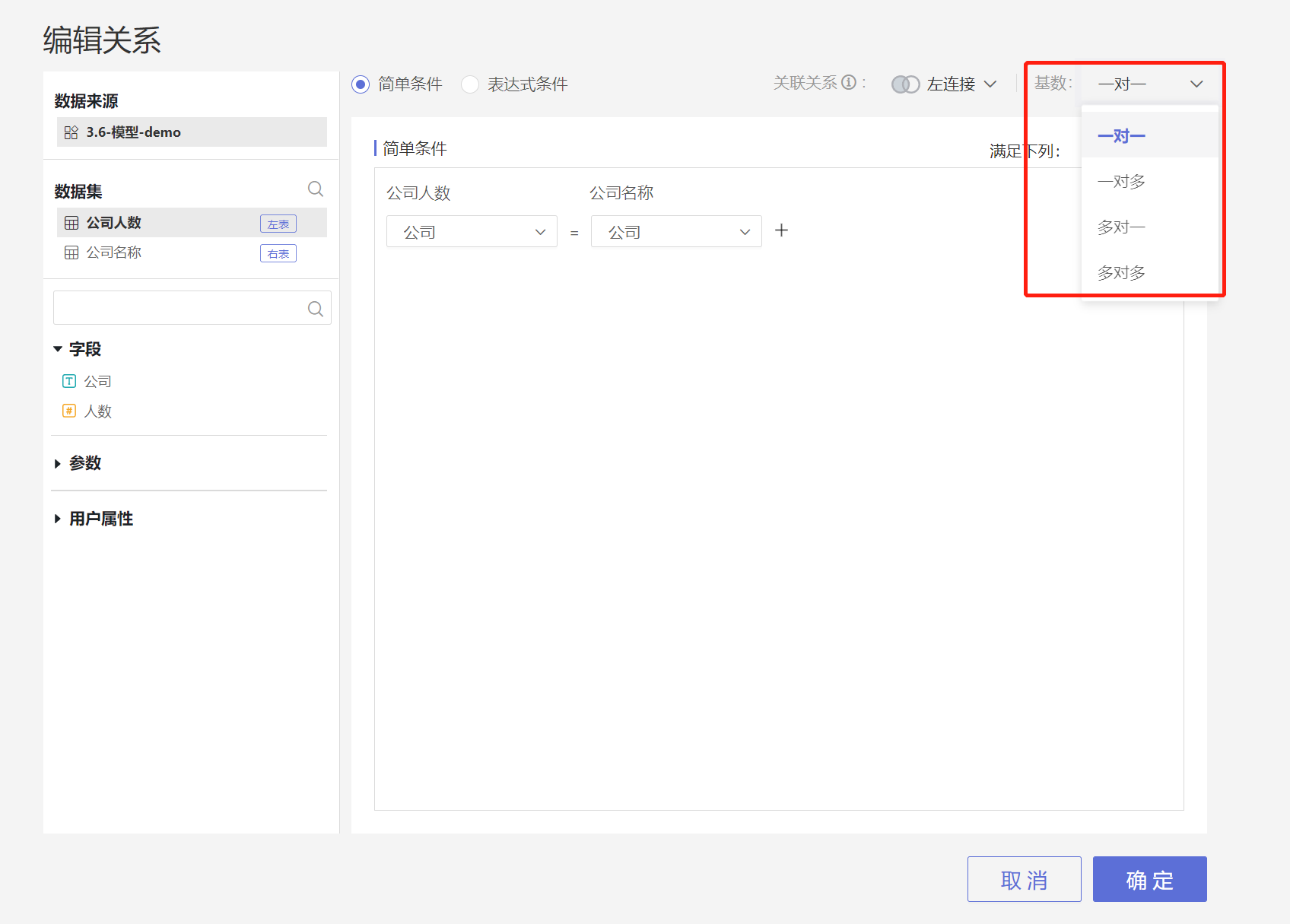
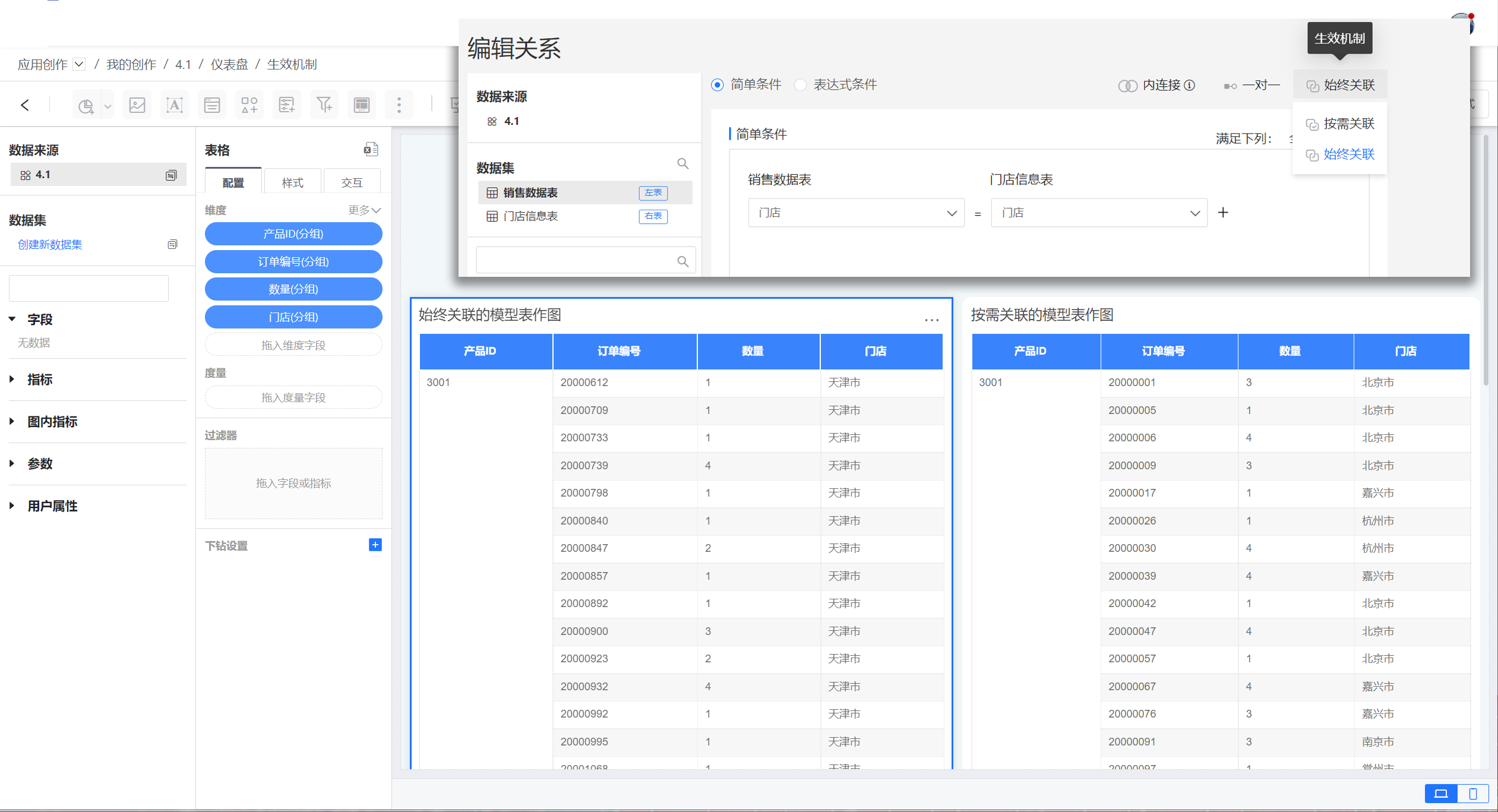
1.1.4. 生效机制
模型的生效机制包括按需关联和始终关联。
- 按需关联表示只使用模型表时关联关系不生效,只有使用到扩展表时关联关系才会生效。
- 始终关联表示不管是否使用到扩展表,关联关系都会生效。
示例中使用销售数据集作为模型表,门店信息表作为扩展表,两张表在使用按需模型和始终关联模型下作图效果。作图时都使用模型表中的字段,可以看出始终关联下关联关系生效,门店使用了扩展表中的门店信息。 按需关联时门店字段还是使用模型表的信息。
1.2. 编辑关系
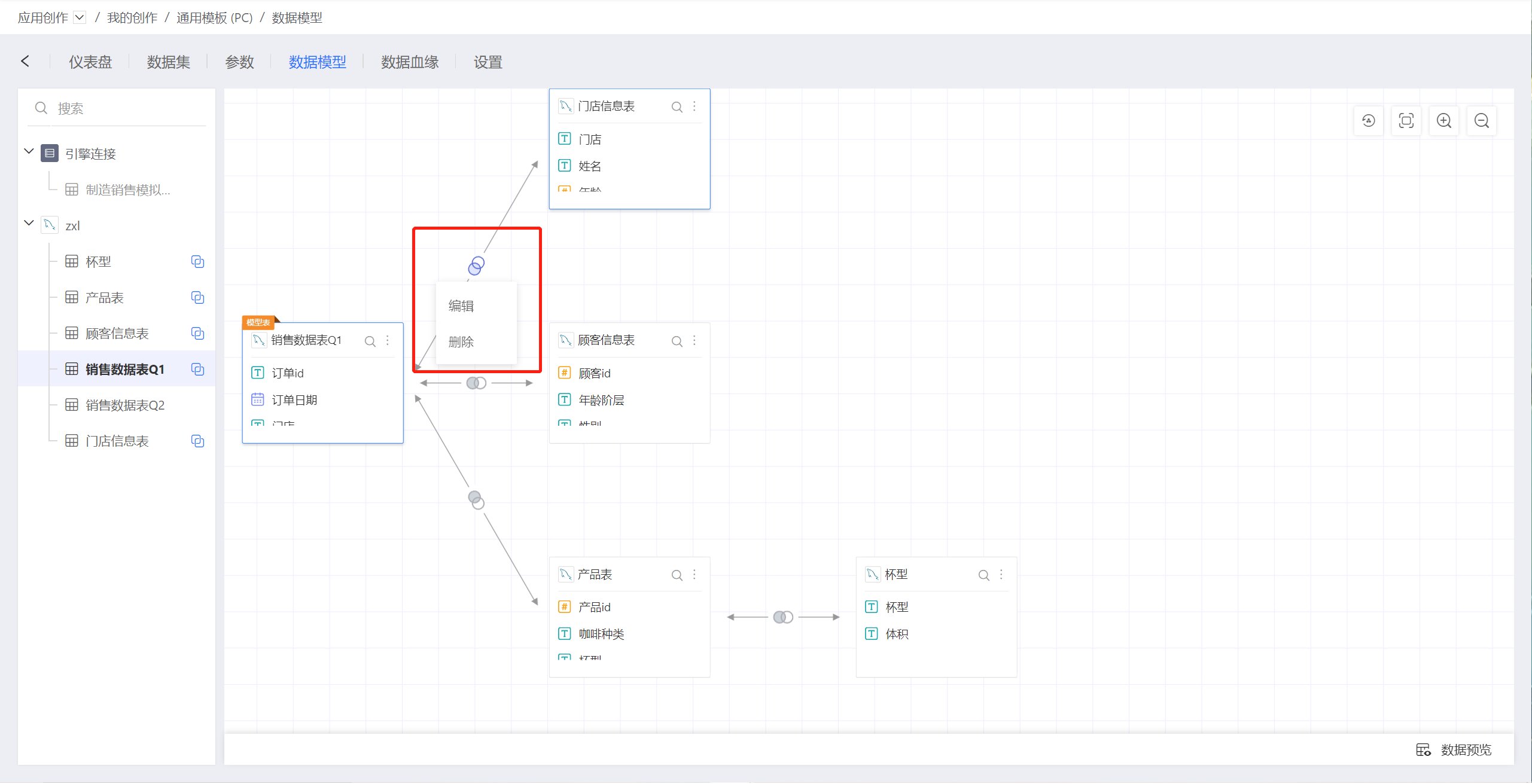
点击一个join关系图标,在弹出的菜单中选择编辑,会弹出编辑关系页面。编辑关系和新建关系页面完全一样。
1.3. 数据集追加
将鼠标悬浮于任一数据集的下部,可以呼出追加+图标,点击该图标,展开追加数据集区域,然后从左侧数据集列表中拖入一个数据集进行追加:

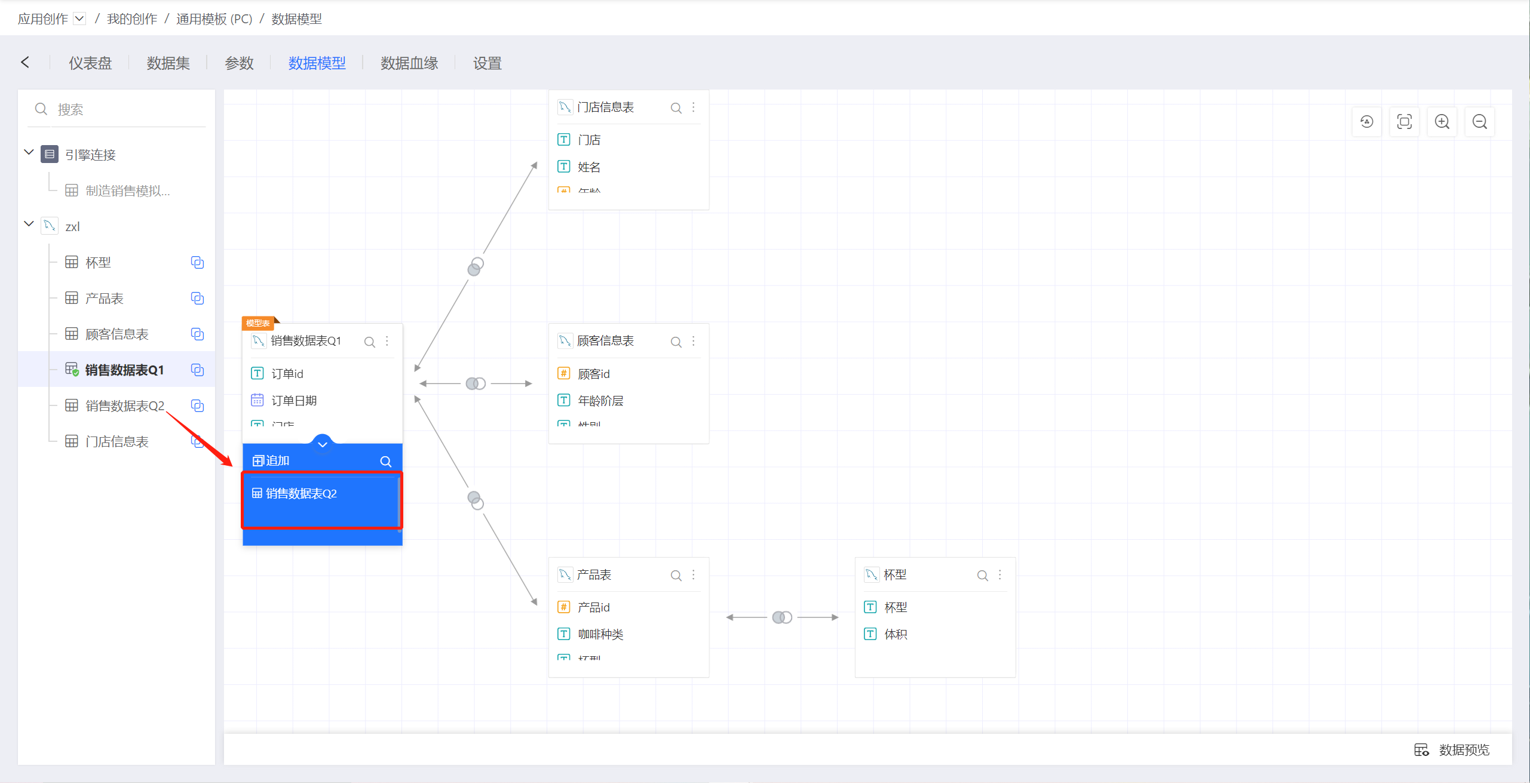
追加原则如下:
自动按label对齐,第一个为base dataset,label一样的加到一起,不一样的添加新的一列,如此循环
base dataset的用户新增字段,追加后依然是新增字段,如果追加进来的字段有一样label的,该实体列被忽略
隐藏列可以参与追加
1.4. 公共字典
不同来源的数据集不能进行建模。如图所示,公司名称和公司人数这两个数据集不能进行关联。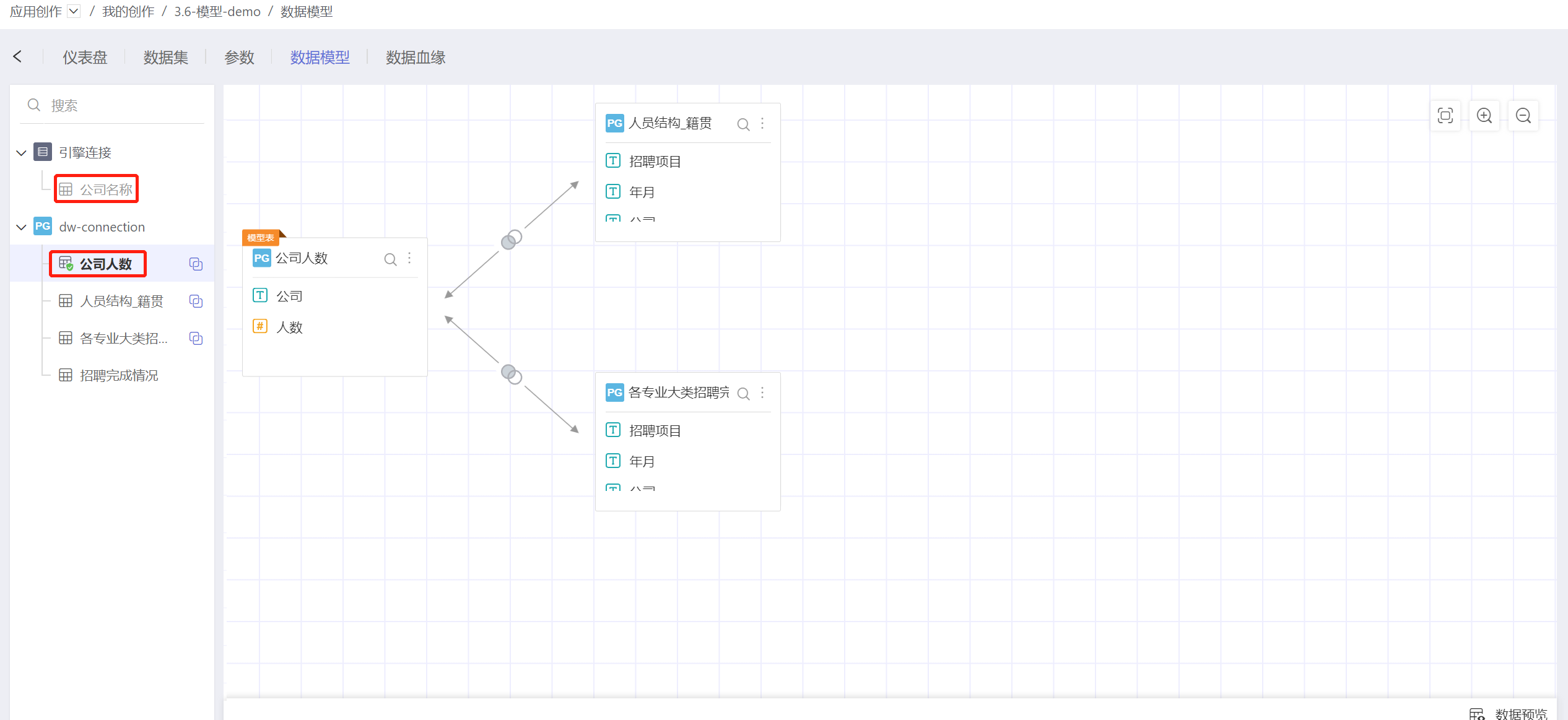
公共字典可以解决上述情况。首先将公司名称的数据集设置为公共字典表。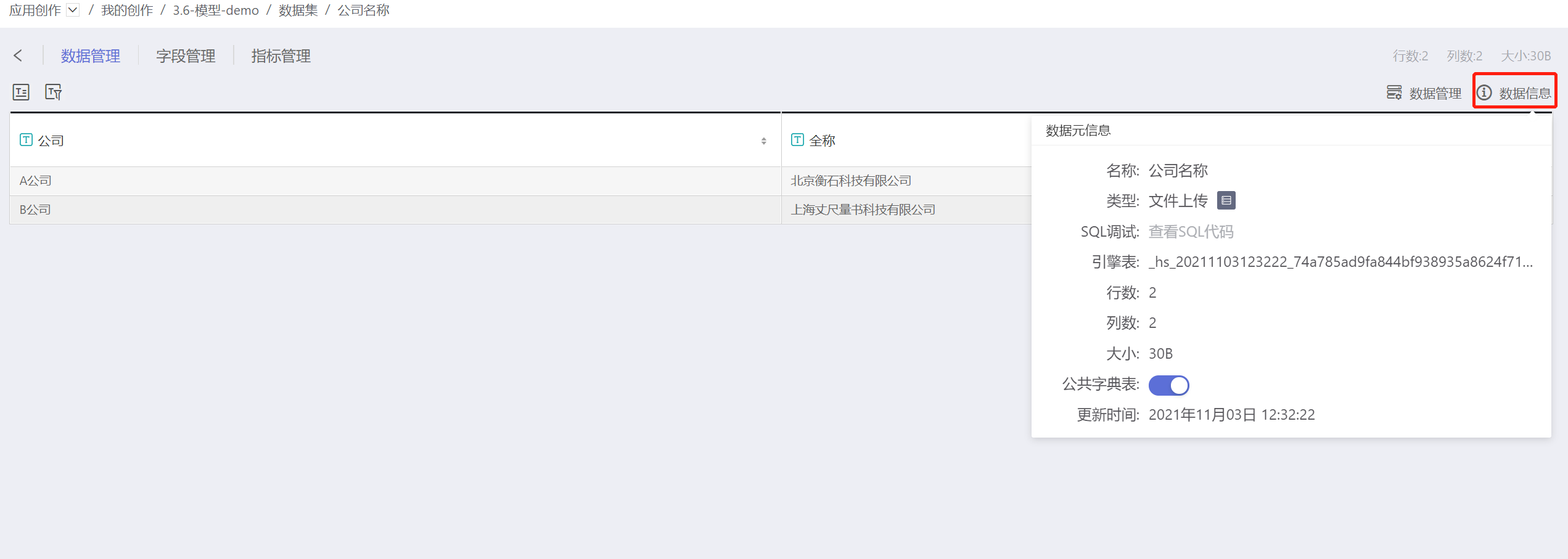
然后在数据模型中拖动公司名称与公司人数进行关联建模。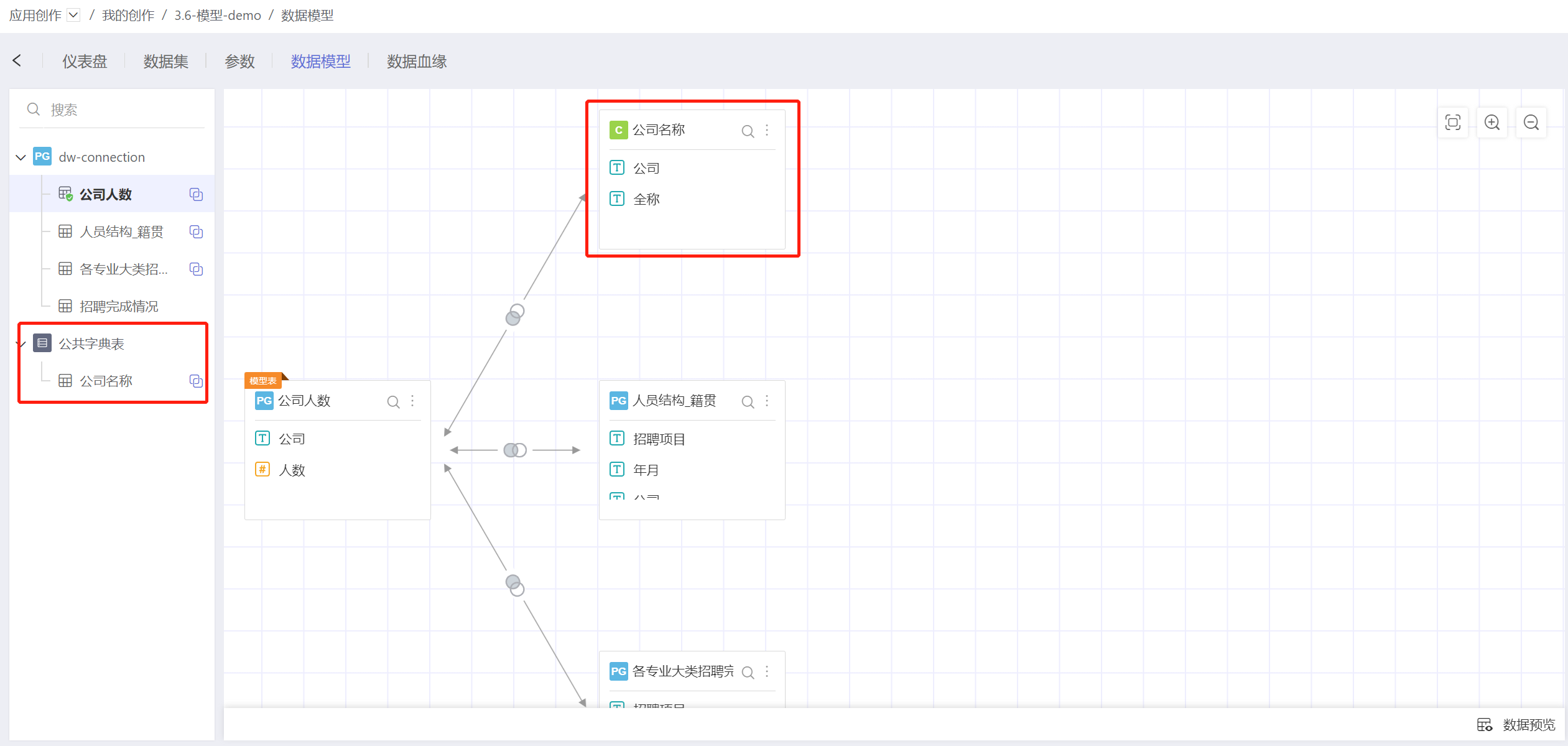
说明:
转换成公共字典的数据集不能大于500行。
任何类型的数据集都支持转换为公共字典。
1.5. 维度去重
在没有公共维度表的情况下,如果多表之间的数据是多对多关系时,直接关联建立模型后,数据可能会发生膨胀,生成重复数据,影响后期数据的挖掘和分析。这种情况下可以使用维度去重功能,去除重复数据,消除数据膨胀。
下面以订单表和广告投放表两个数据集举例,演示如何使用维度去重功能消除数据膨胀。
订单表和广告投放表的原始数据如下。
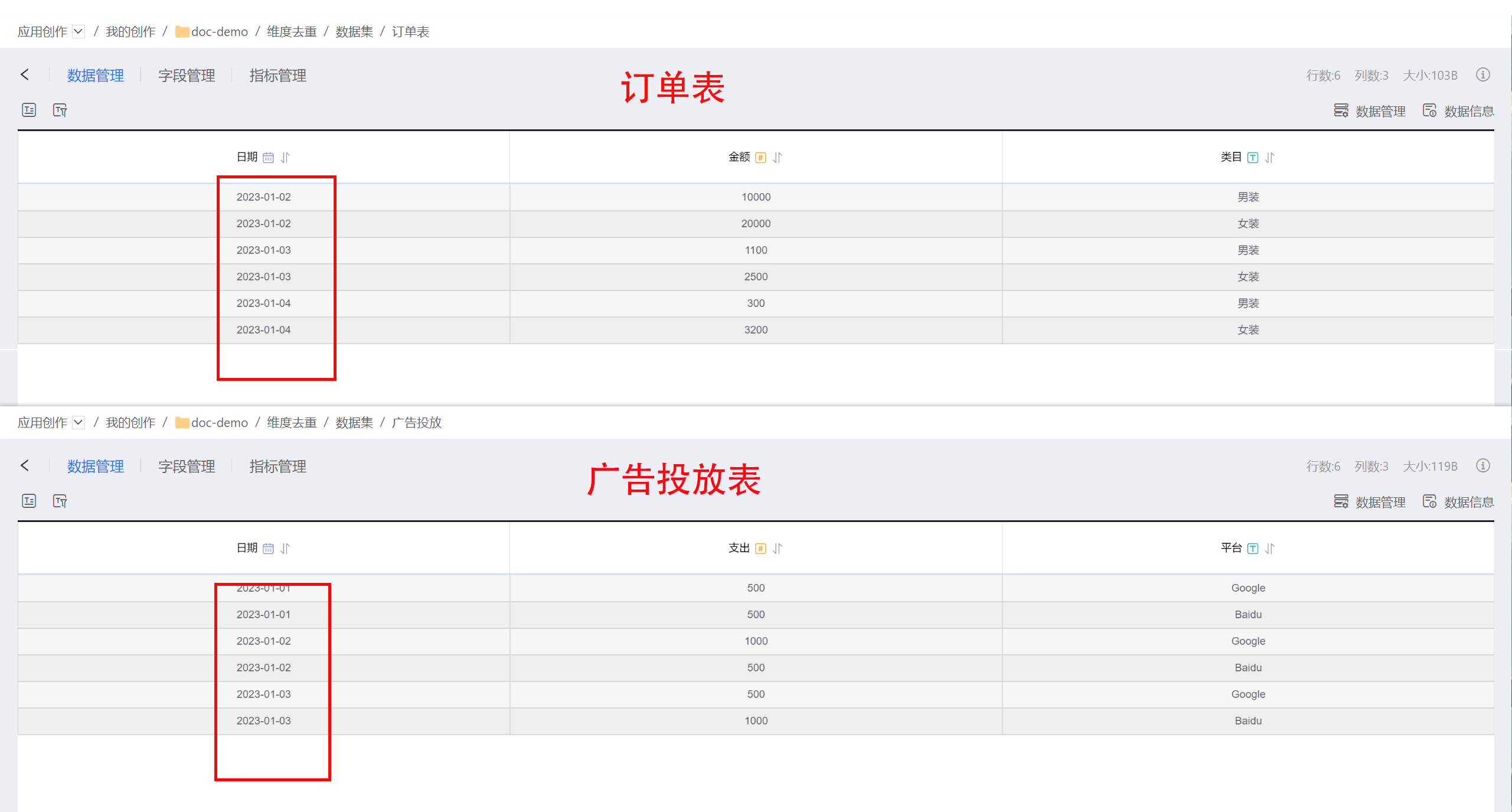
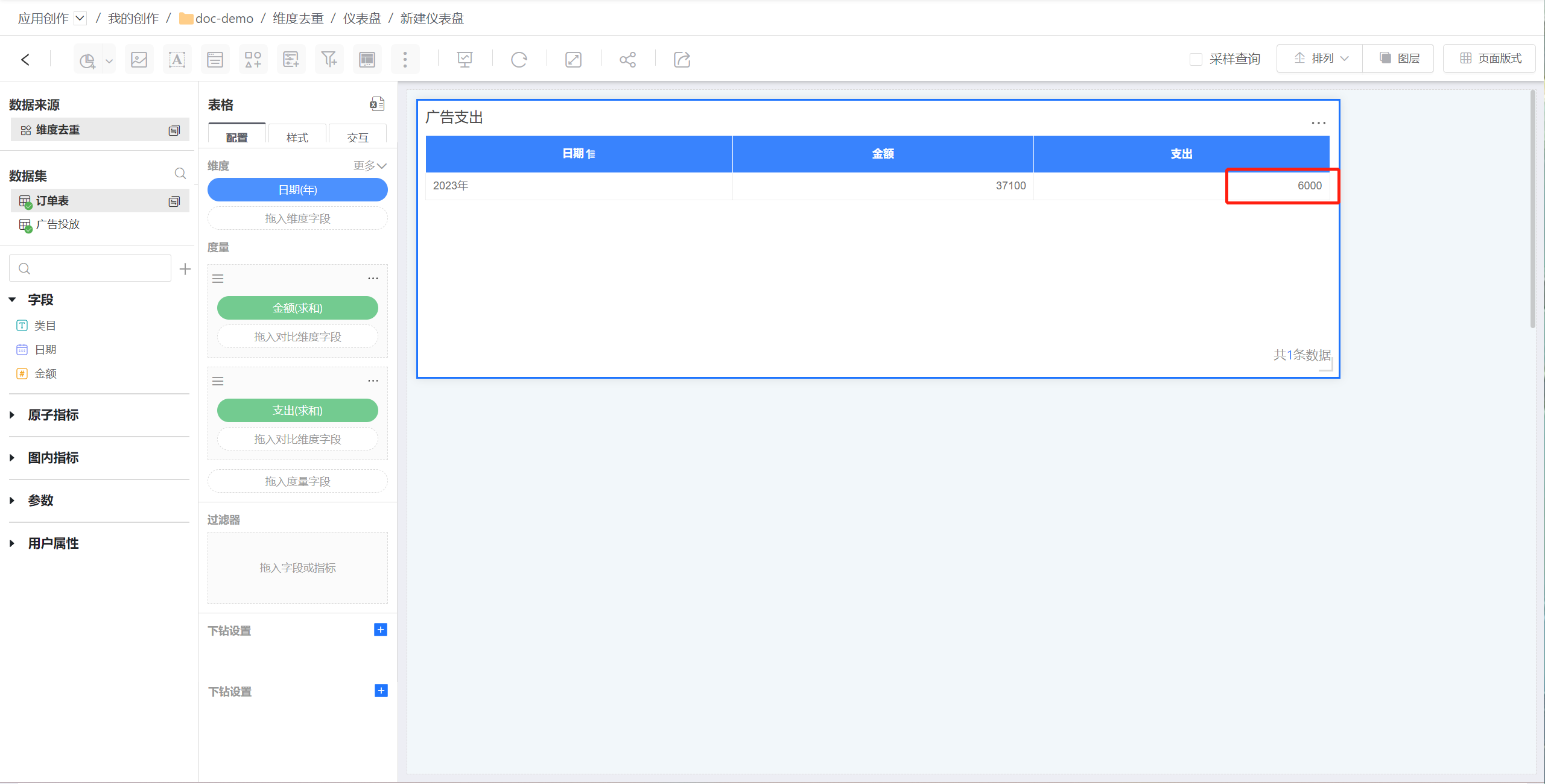
直接使用日期字段进行多对多的关联并作图分析,那么得到的关联关系和图形的数据会膨胀,总广告投放支出只有4000的情况下,聚合结果为6000。
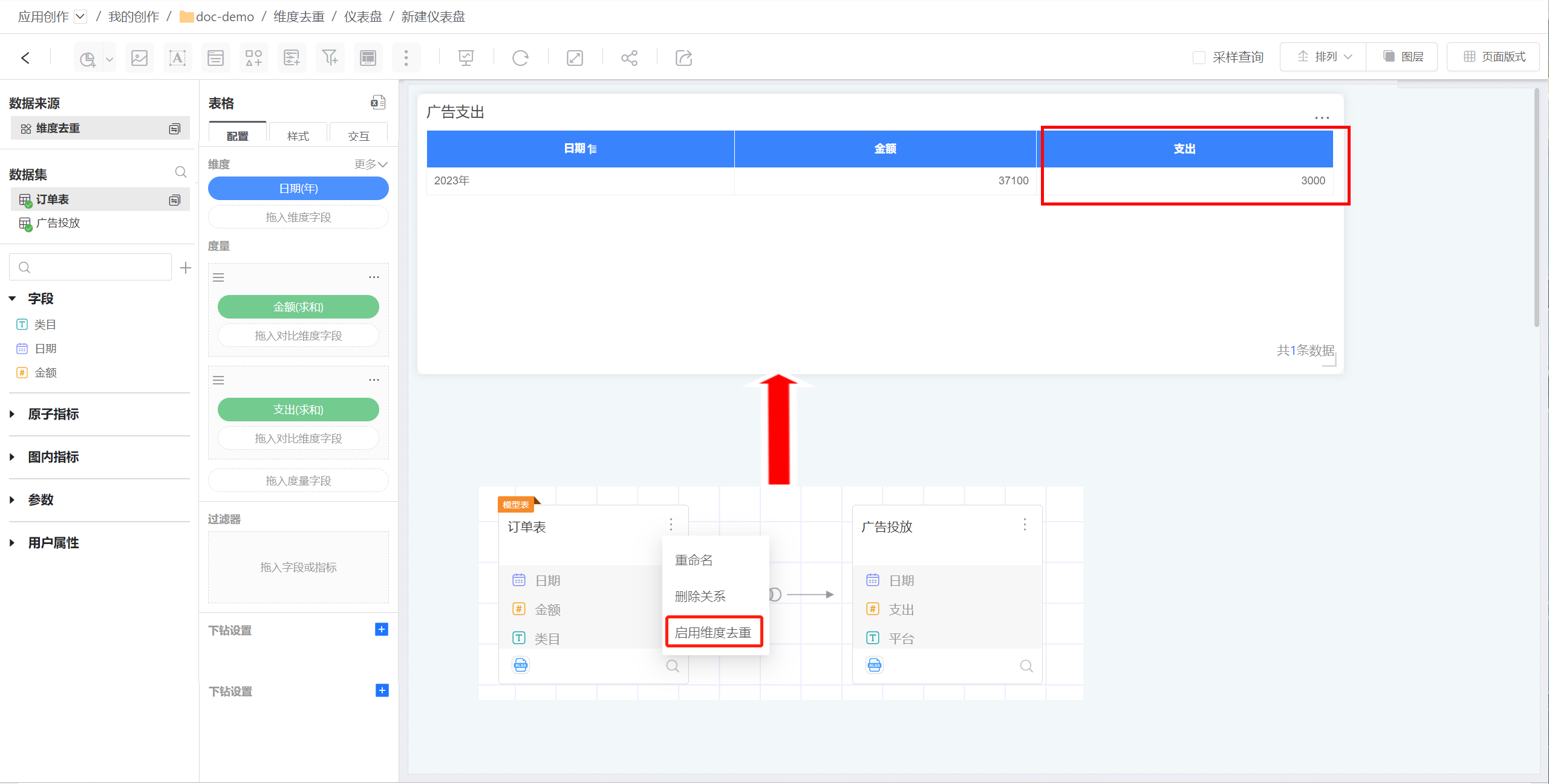
当开启维度去重之后,那么模型就可以根据用户的意图,算出订单对应的日期的广告支出实际上只有3000。
说明:
维度去重功能根据数据分析的需要支持开启和关闭。 在使用维度去重功能时,要清楚哪些数据发生了膨胀,消除的是哪些膨胀数据。
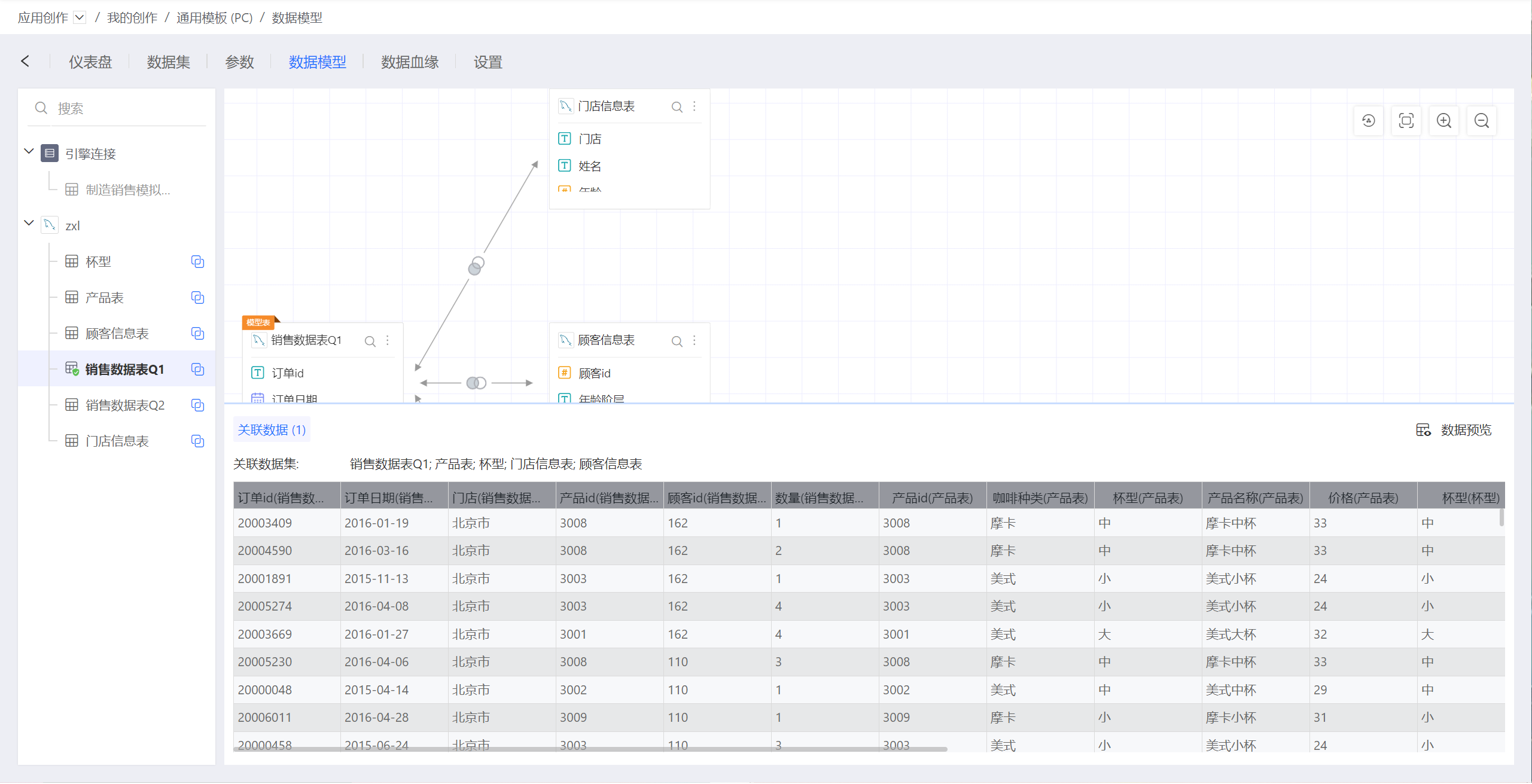
1.6. 预览数据
点击数据模型区域右下方的预览数据,可以即时预览关联模型生效后的数据:
1.7. 删除关系
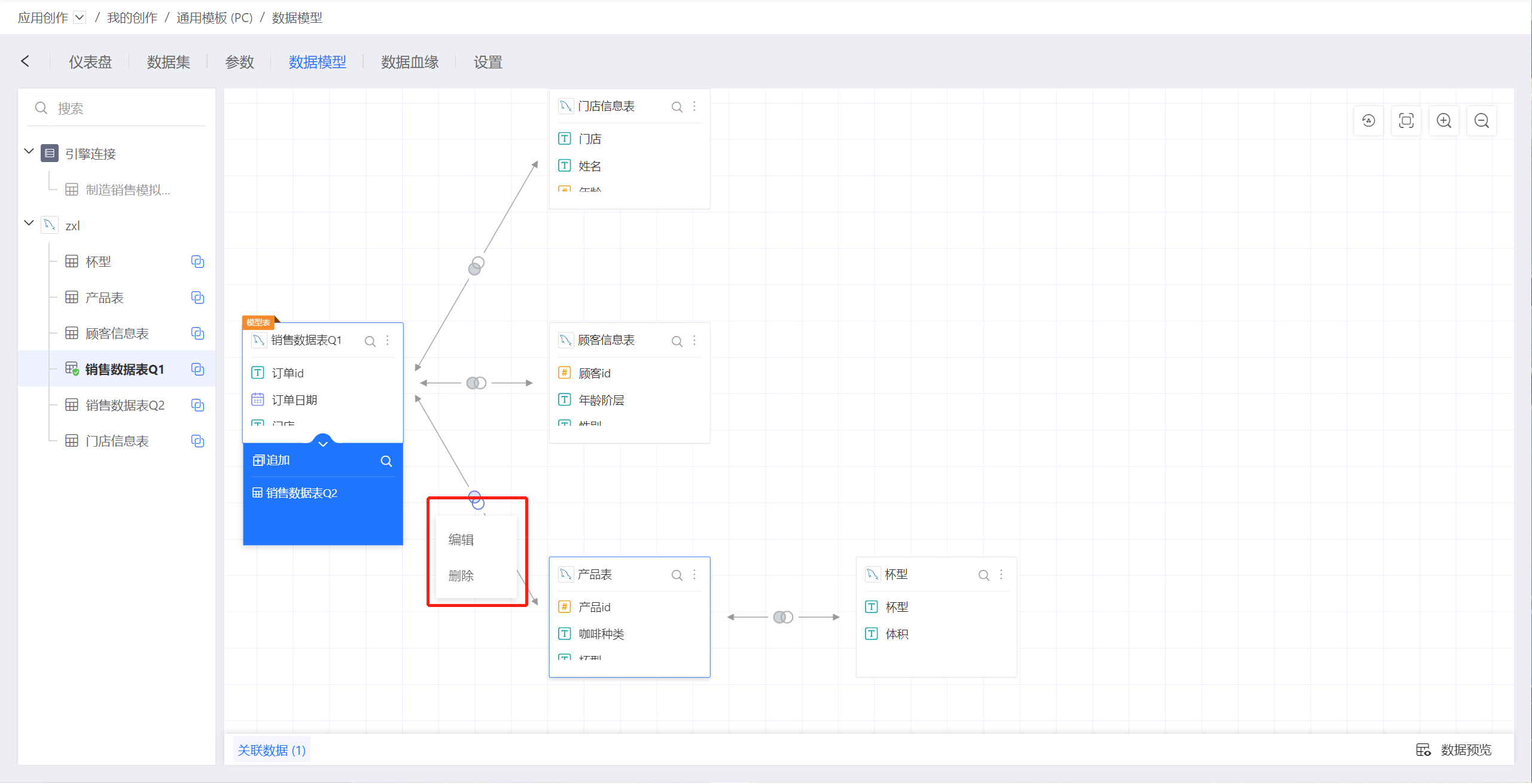
删除关系有两种方式:
- 点击关联图标,在弹出菜单中选择
删除,可以删除单个关系。删除单个关系时,与删除的关联表关联的其他关系也会被删除。也就是说,数据模型中不会有独立于模型表的关系,任何一个数据集都会通过一个或多个链条与模型表相关联。
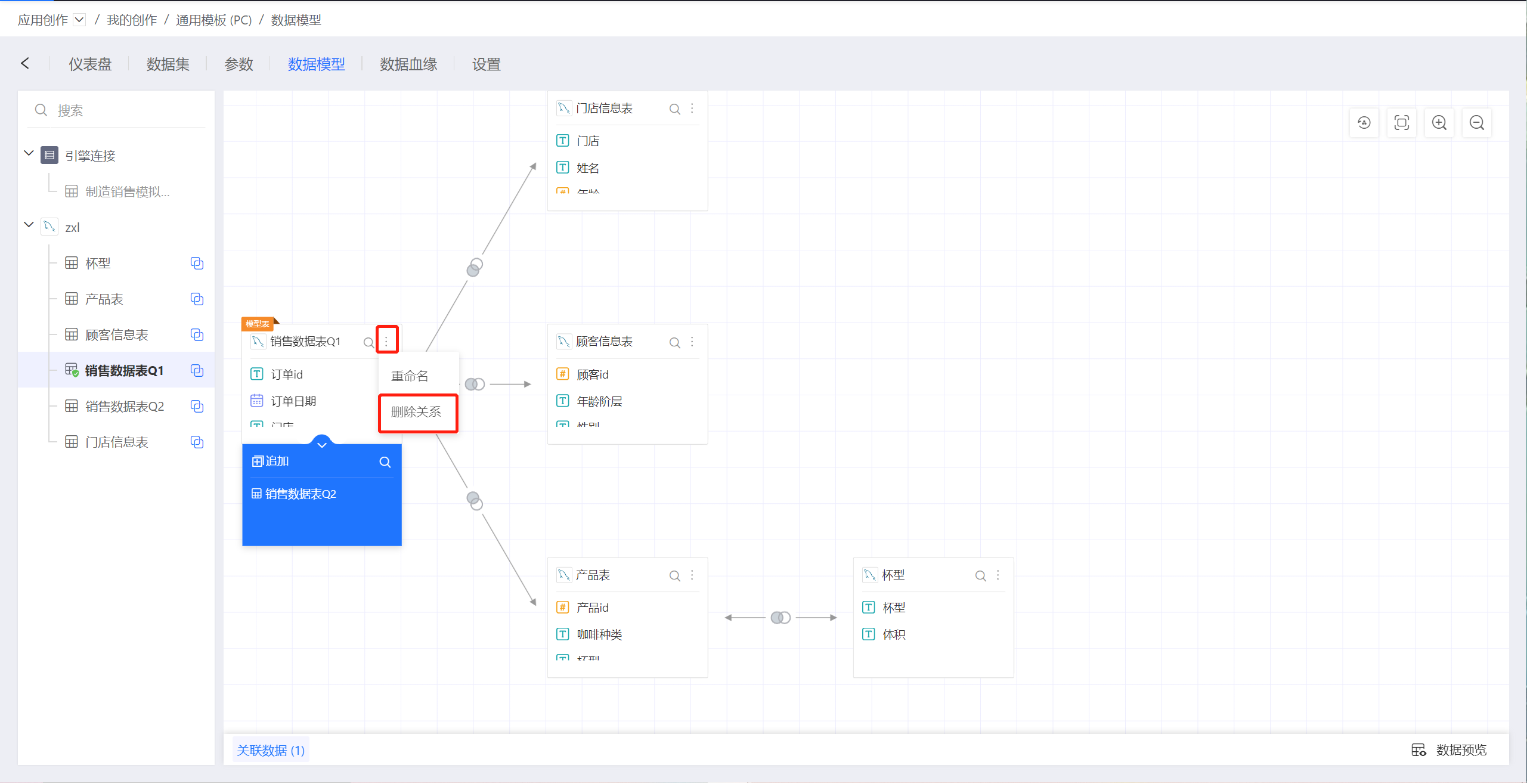
- 点击数据集右上方的三点菜单,在弹出菜单中点击
删除,这会删除与该数据集关联的所有关系。
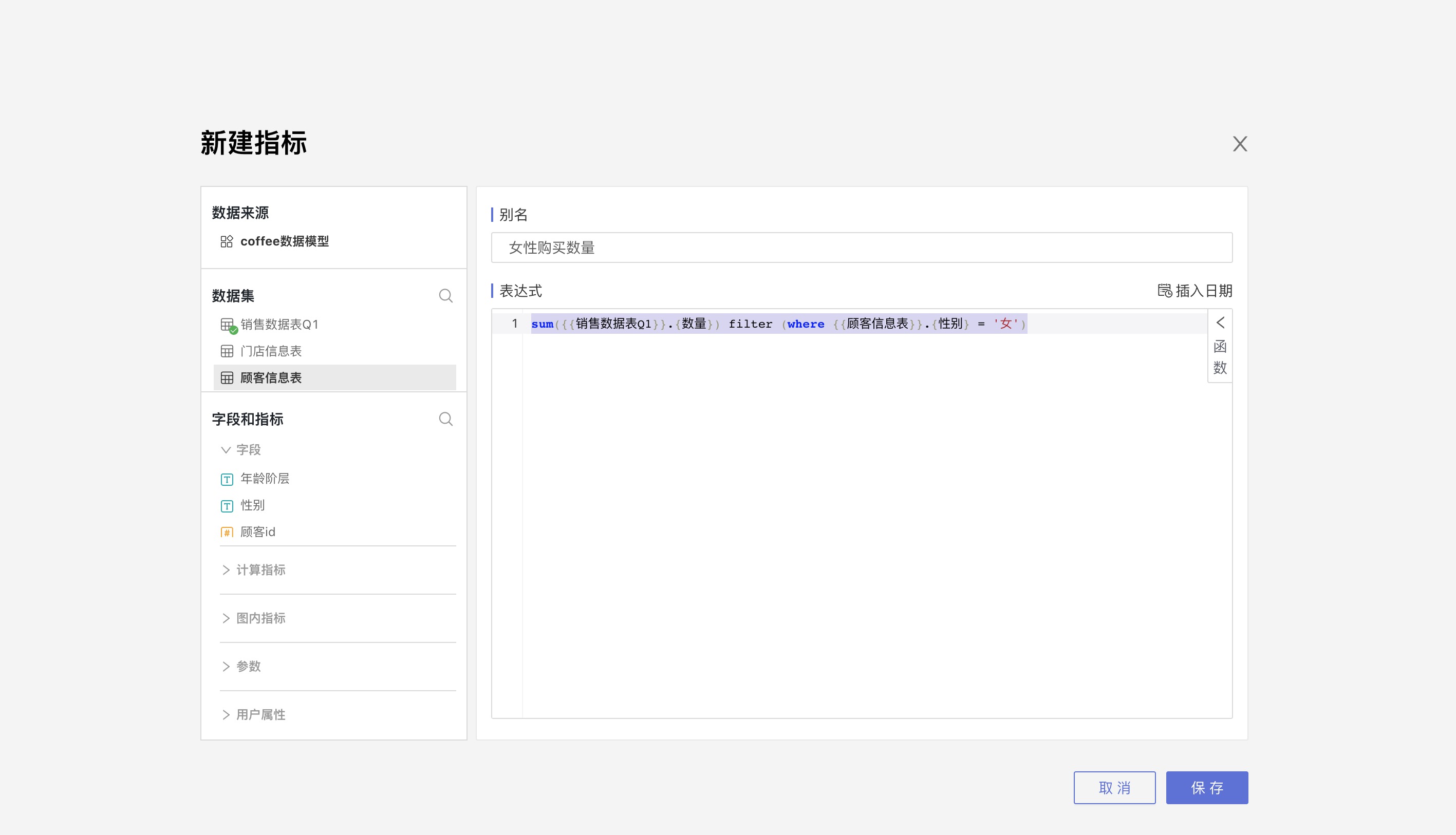
1.8. 跨数据集创建指标
打开模型表数据集,选择新建指标,在指标表达式中可以使用关联表的字段。
在一个模型中,只能给模型表创建指标,不能为关联表创建指标。
下图的指标使用了两个数据集的字段:
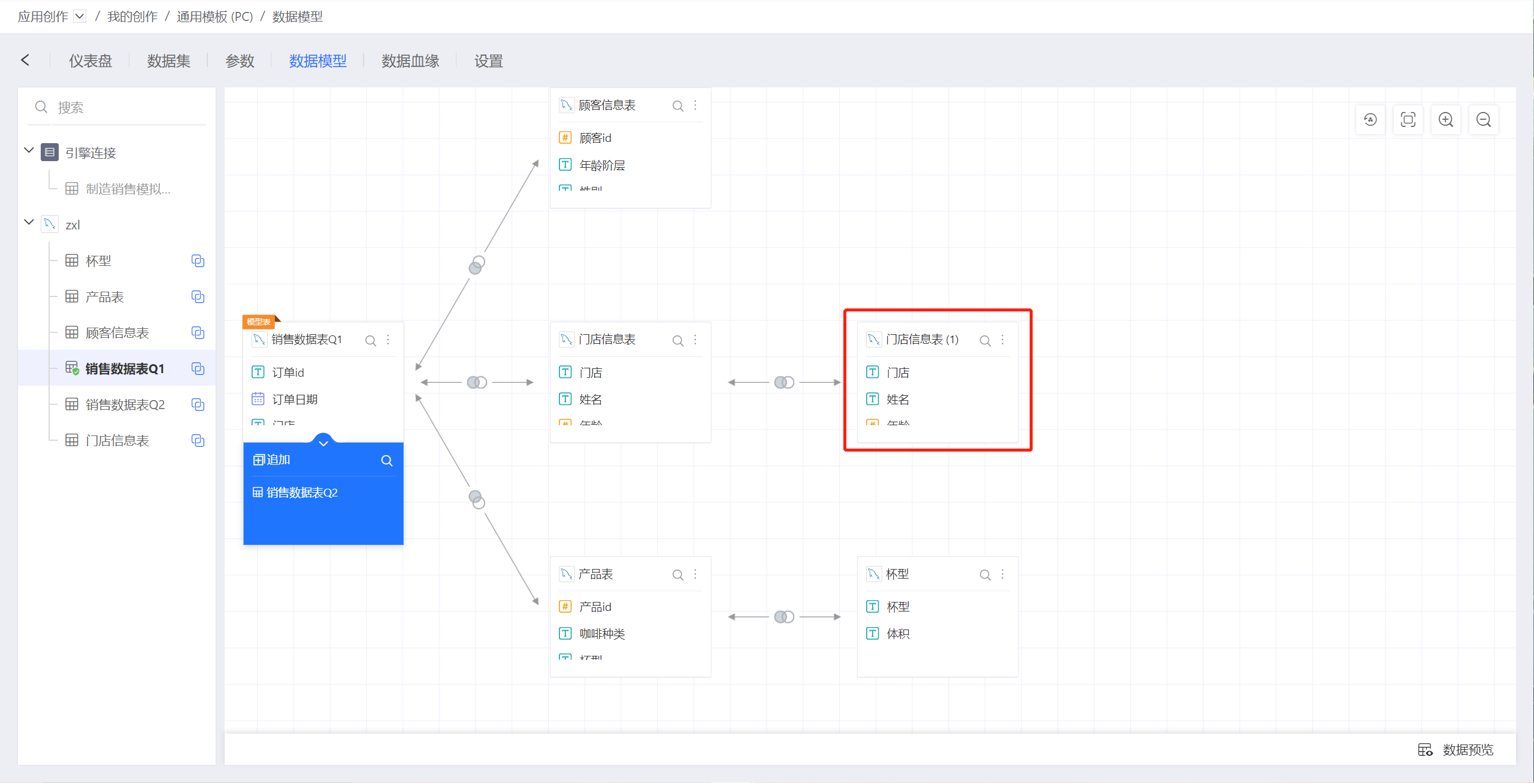
1.9. 数据集复用
在一个数据模型中,可以将同一数据集拖入多次,后续拖入时会在数据名称上自动加上(1)、(2),如下图,门店信息表第二次拖入时,自动加上了(1),变成了门店信息表(1)。
数据集复用主要适用于维度表/字典表自关联来实现多层级别的场景,比如员工表中,员工经理ID与员工ID进行自关联,来查询某个员工的经理是谁。
比如下图中,层级1、层级2、层级3这三个数据集都是字典表这个数据集的复用,它们相互之间使用parentid与id进行关联,一级一级查询到最高的父级,它们与订单表进行关联,从而可以统计出各个级别的订单销售情况。
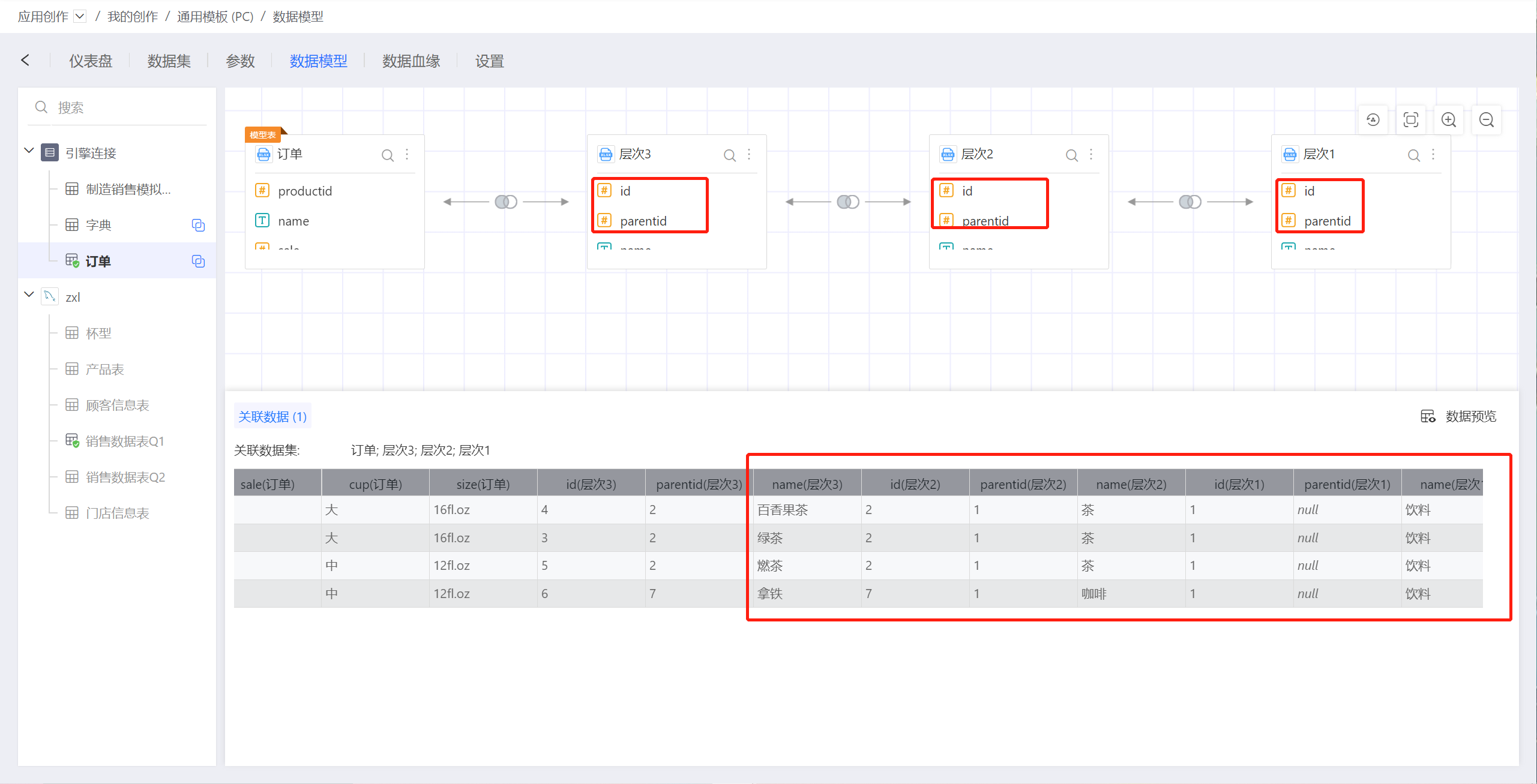
1.10. 数据集重命名
在数据模型中,可以点击数据集右上角的重命名对数据集进行重命名,重命名后的数据集本质上是一个新的引用数据集,在联动过滤时不会影响使用原始数据集做的图。
1.11. 联动过滤
只要数据集名称相同,就会联动过滤。
该规则适用于联动过滤和仪表盘过滤器。
1.12. 数据模型性能优化指南
- 直连时:原表使用窄表,避免宽表,去掉无用的字段,减少扫描,减少内存占用
- fusion等加工表落引擎表,也是去掉无用的字段,加速导入引擎过程
- 直连时,将计算字段在原表物化,避免做图时计算
- join时,尽量使用数字进行join,比如有部门id和部门名称,用部门id进行关联,数据库会对数字进行性能优化
- 生成聚合表,导入引擎:比如订单表,按照客户、天、产品去聚合,甚至可以按月来聚合
- 创建索引视图,给视图加索引
- 在源数据库新建一个日期维度表,将年、季度、月、周、日提前计算出来,确保日期覆盖了事实表的日期,用日期维度表和事实表进行关联,过滤时使用日期维度表
- 减少类型转换,建表时就把类型正确定好
- 关联字段不要使用计算字段,一个原因是计算字段耗时间,一个原因是计算字段没有索引
- 先聚合,再join,减少join基数
- 关联时:一对一、一对多,尽量避免多对多,因为会造成重复计算,聚合结果可能不正确
1.13. 数据模型与fusion数据集的区别
- fusion可以落实体表,偏分析性能
- 数据模型在作图时会显示数据集,便于字段识别,偏分析时的便利性
- 查询时,fusion会用到所有基础表,模型只会查询使用到的数据集
可以使用数据模型进行探索性分析,确定分析模型和分析数据之后,使用fusion将仅需的字段落实体表。
results matching ""
No results matching ""
衡石文档
- 产品功能一览
- 发布说明
- 新手上路
- 安装与启动
- 系统管理员手册
- 数据管理员手册
- 分析人员手册
- 数据查看员手册
- 数据服务
- 最佳实践
- 衡石分析平台 API 手册
- 附录