1. 连接ClickHouse
请参照如下步骤连接ClickHouse数据源。
1.在数据连接页面右上角点击新建数据连接。
 2.在数据源种类中选择ClickHouse数据源。
2.在数据源种类中选择ClickHouse数据源。
3.按要求填写连接时数据源的参数。
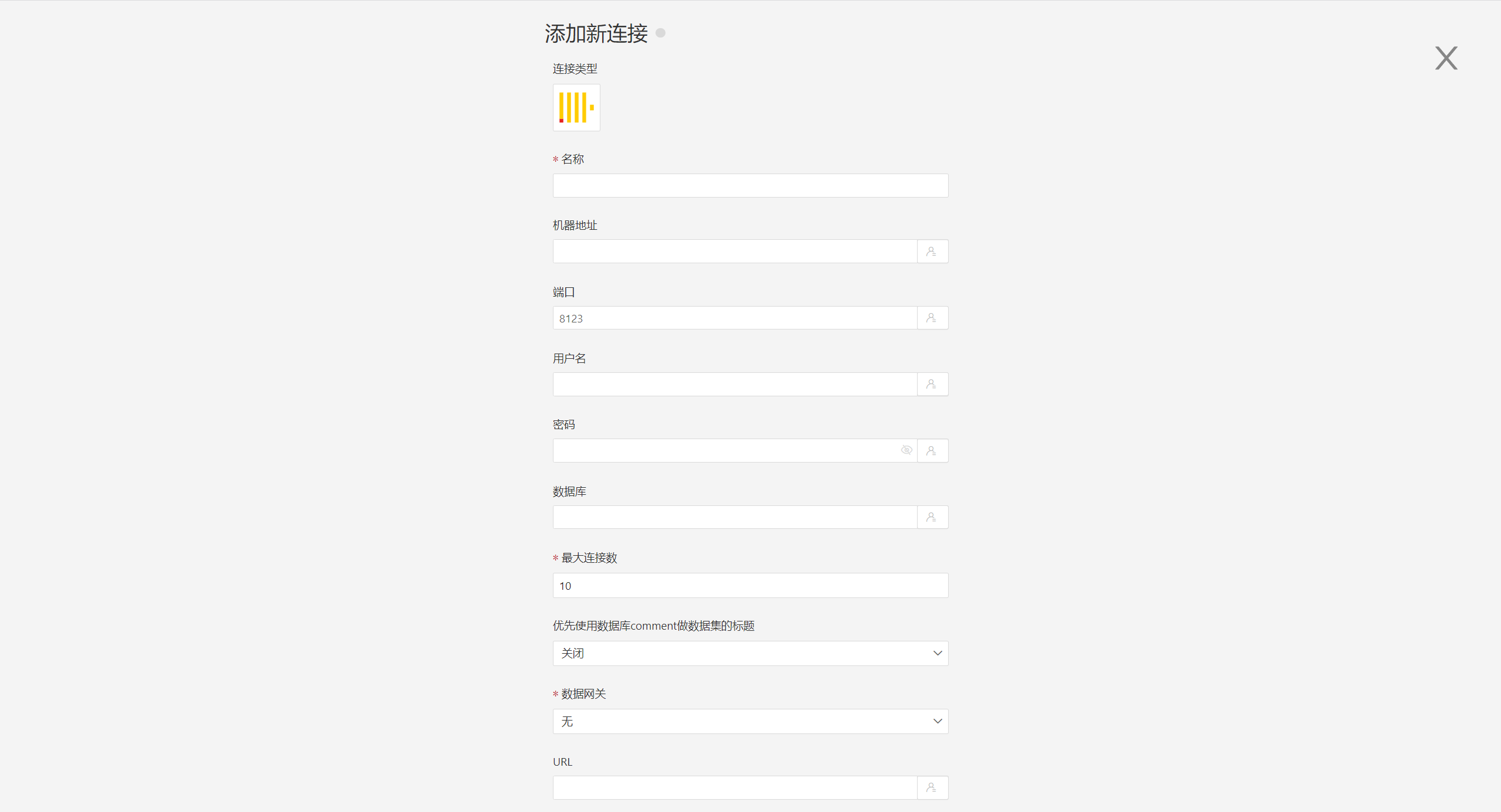
- 名称: 连接的名称,需要唯一。
- 机器地址:数据库的地址,如果填了url字段,优先使用url里面的。
- 端口:数据库的端口,如果填了url字段,优先使用url里面的。
- 用户名:数据库的用户名。
- 密码:数据库的密码。
- 数据库:数据库名称,如果填了url字段,优先使用url里面的。
- 最大连接数:连接池最大连接数
- 优先使用数据库comment做数据集的标题: 优先显示表的名字还是表的注释。开启时显示标题,关闭时显示表注释。
- 数据网关:当连接通过数据网关进行时填需要写数据网关ID。
- URL:数据库的jdbc url。
- Cluster:仅输出使用,输出到指定的cluster中。该参数为空时只写本地表MergeTree引擎,该参数填写后会根据cluster基于本地MergeTree表生成分布式表。
- ClickHouse输出是否使用表副本:仅输出使用,是否使用表副本。不使用副本则表引擎是MergeTree,使用副本表引擎为 ENGINE = ReplicatedMergeTree('/clickhouse/tables/{database}/{table}/{shard}', '{replica}') order by %s settings allow_nullable_key=1
- ClickHouse输出表引擎模板:默认为 ENGINE = ReplicatedMergeTree('/clickhouse/tables/{database}/{table}/{shard}', '{replica}') order by %s settings allow_nullable_key=1,用户也可以参照格式改写
- join_use_nulls:join_use_nulls的设置,可以填0或者1,影响join的行为。
- 支持上传文件到指定路径:具体的路径表示文件上传的数据库名称。验证通过后,才能配置该参数。
- 支持数据集成输出:表示该连接可以在数据集成,批量同步,流式同步中选择为输出连接。需要用户自己保证对数据库有写权限。验证通过后,才能配置该参数。
- 只显示指定数据库/模式下的表:该项选中时并且database字段不为空,则只显示该db下面的表。
4.填好参数后,点击"验证"按钮,获取验证结果(验证HENGSHI SENSE和设置的数据连接的连通性,在未验证通过时不可添加)。
5.验证通过后支持数据集成输出和支持上传文件到指定路径由禁用变为启用。可选择是否开启这两项。
6.点击执行预置代码,弹出该数据源对应的预置代码,点击执行按钮。
7.点击"添加"按钮,添加设置的ClickHouse连接。
说明:
- 配置参数时带*的参数是必填参数,其他参数为选填。
- 连接数据源时,必须执行预置代码。不执行会导致数据分析过程中某些函数无法使用。此外,从4.4之前的版本升到4.4时,需要对系统中已经存在的数据连接执行预置代码。
results matching ""
No results matching ""
衡石文档
- 产品功能一览
- 发布说明
- 新手上路
- 安装与启动
- 系统管理员手册
- 数据管理员手册
- 分析人员手册
- 数据查看员手册
- 数据服务
- 最佳实践
- 衡石分析平台 API 手册
- 附录