1. 流式同步
当用户需要将数据从一个数据库实时迁移到一个或多个目标数据库时可以通过在流式同步中创建项目来实现。
流式同步主要功能:
- 将一个或者多个表同步到指定连接中。
- 在数据同步过程中设置数据同步策略。
- 实时同步数据。
1.1. 创建数据同步流程
流式同步数据的过程如下:
- 创建流式同步项目。
- 配置来源数据连接和目标数据连接。
- 配置同步策略。
- 开始数据同步,实时监控来源数据的变化,将变化的数据同步到目标数据库中。
1.2. 流式同步详细指导
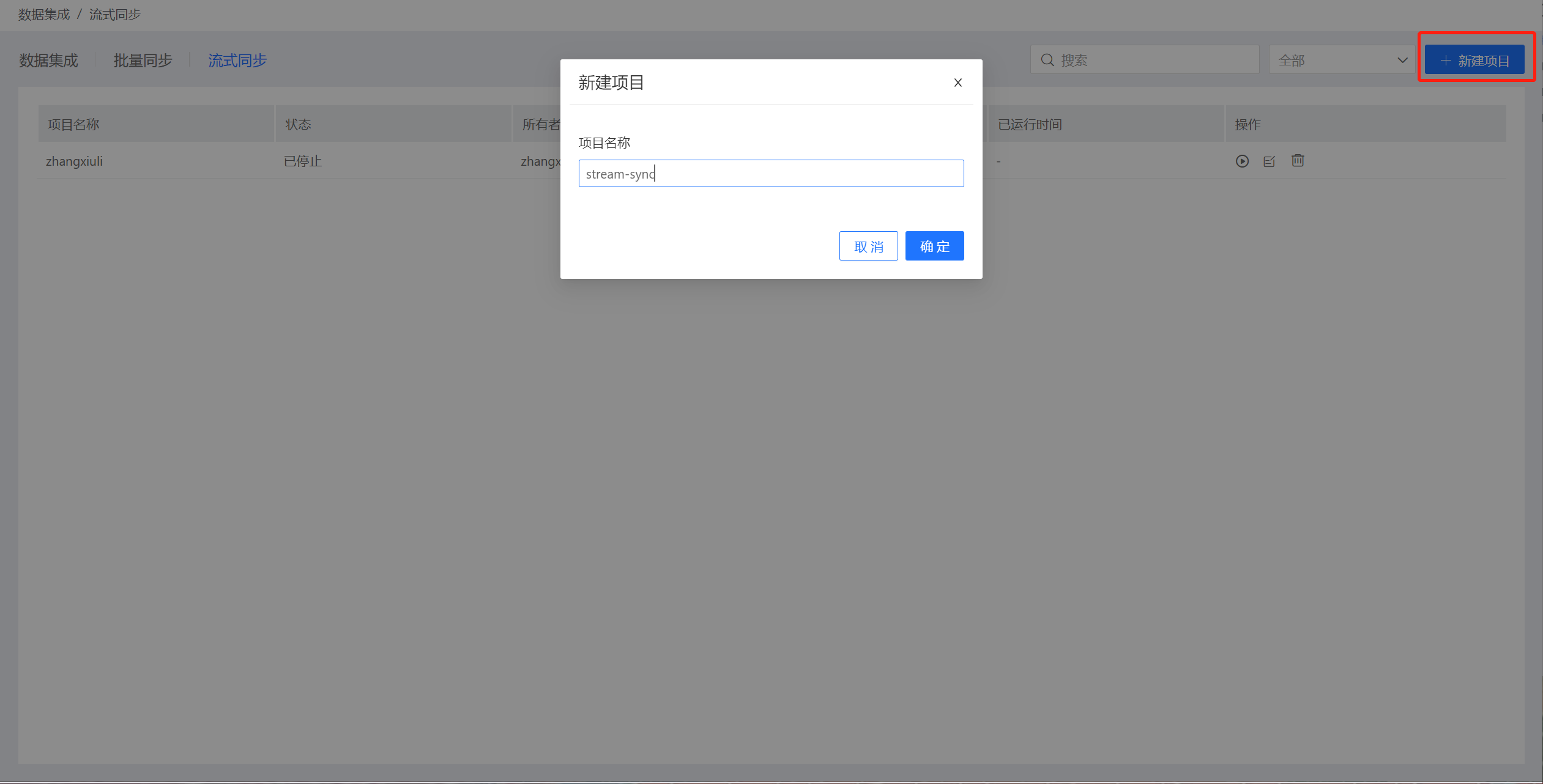
1.创建流式同步项目。
在数据集成->流式同步页面中,点击右上角的新建项目,创建流式同步项目。
2.配置数据源。
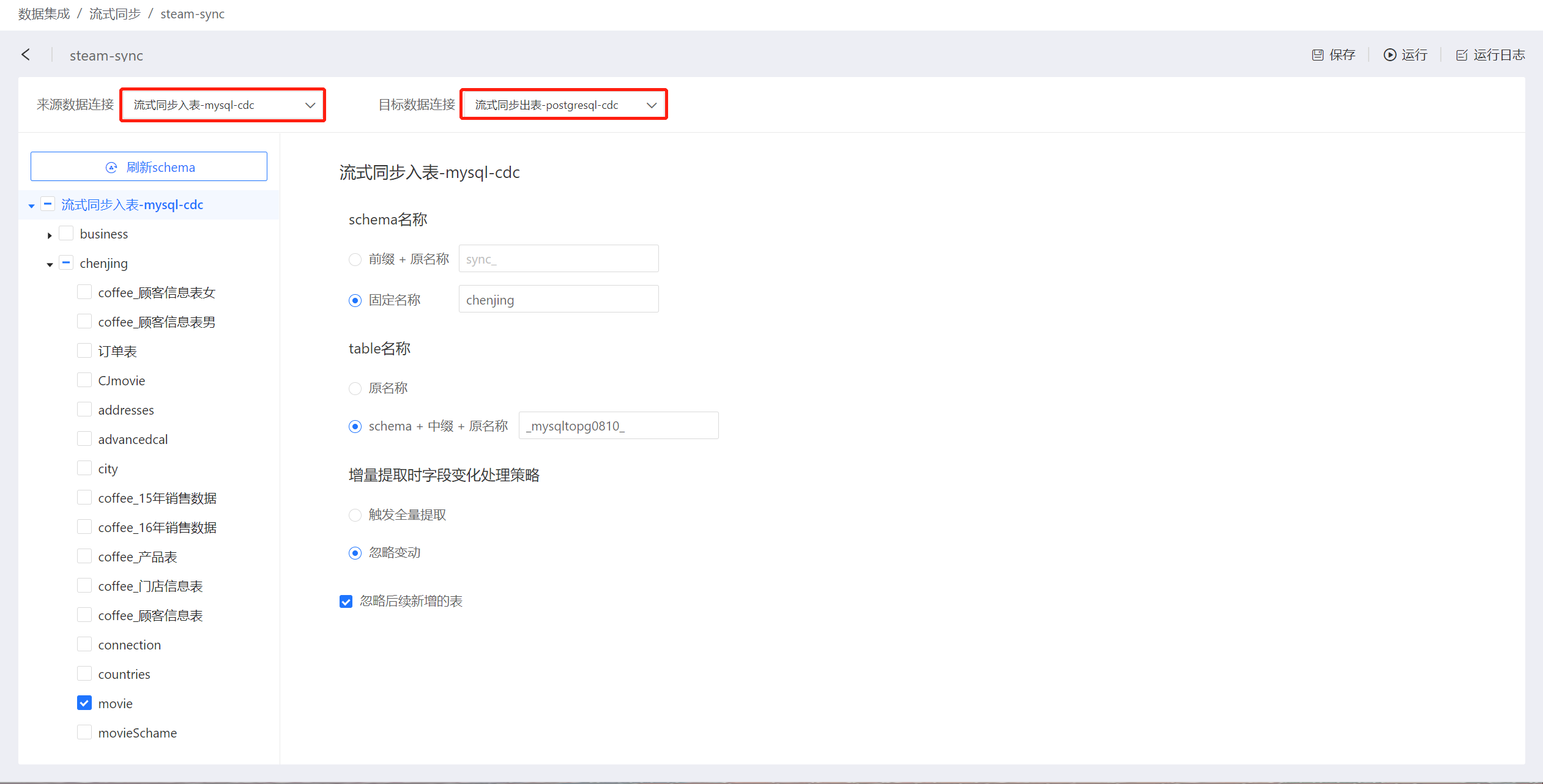
在流式同步项目页面设置来源数据连接(需要迁移数据的连接)和目标数据连接(数据迁移到的连接)。 目标数据连接创建时需要勾选支持数据集成输出功能。 如果不了解数据连接的概念,请先阅读数据连接。
注意:
来源数据连接支持MySQL、PostgreSQL、SQL Server和Oracle,目标数据连接支持Greenplum和PostgreSQL。
3.配置数据同步策略。
流式同步支持对连接、schema、表分别设置同步策略。
配置连接同步策略。连接同步策略对连接内所有目录及目录下的表都生效。
- schema名称: 数据同步后表所在的schema名称设置。
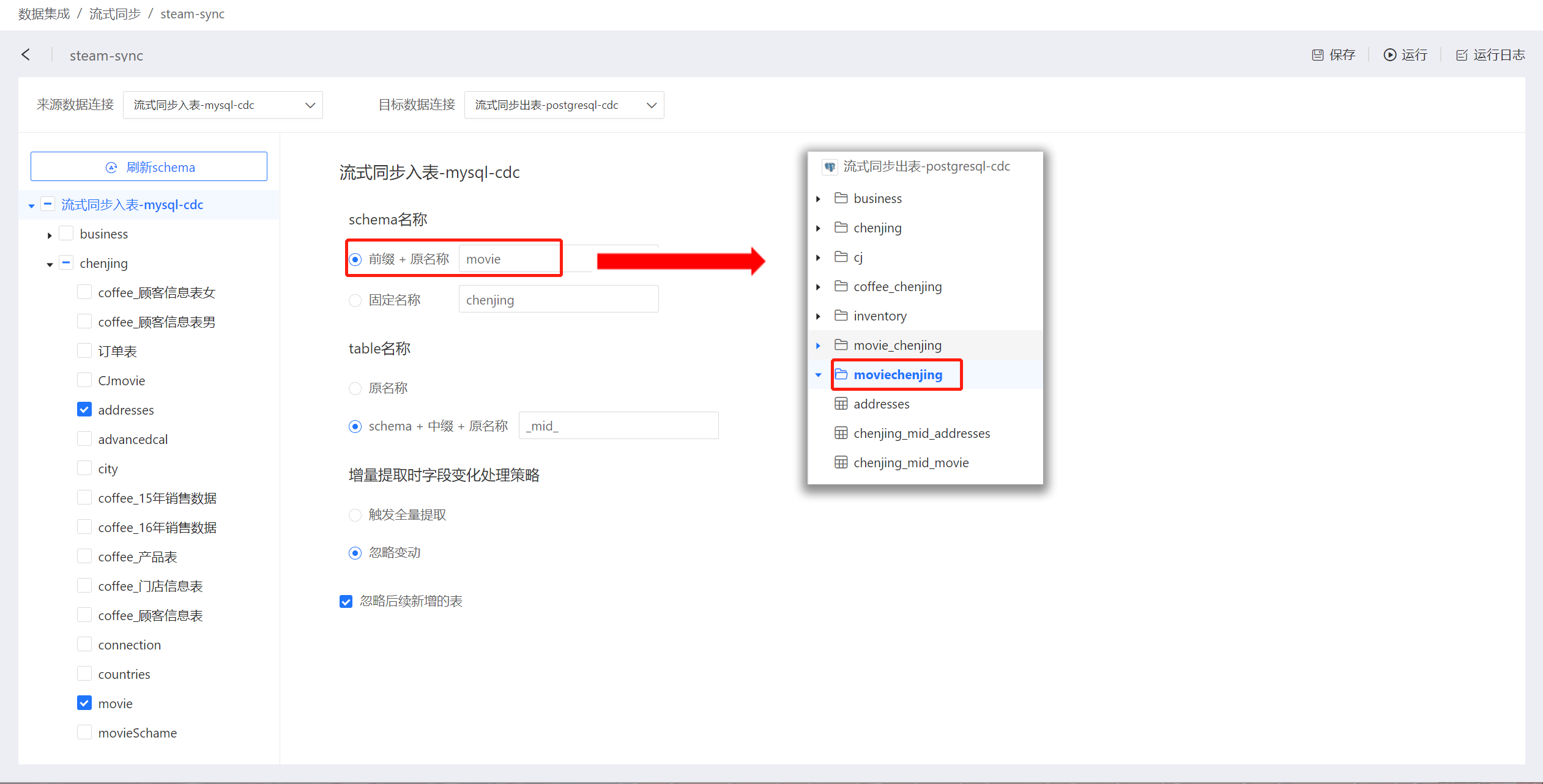
- 前缀+ 原名称: 数据同步后表存放的目录名称为“前缀”+“原名称”。 如图将前缀设置为“movie”时,数据同步前表addresses存放在目录chenjing中,同步后表addresses存放目录名称为“moviechenjing”。
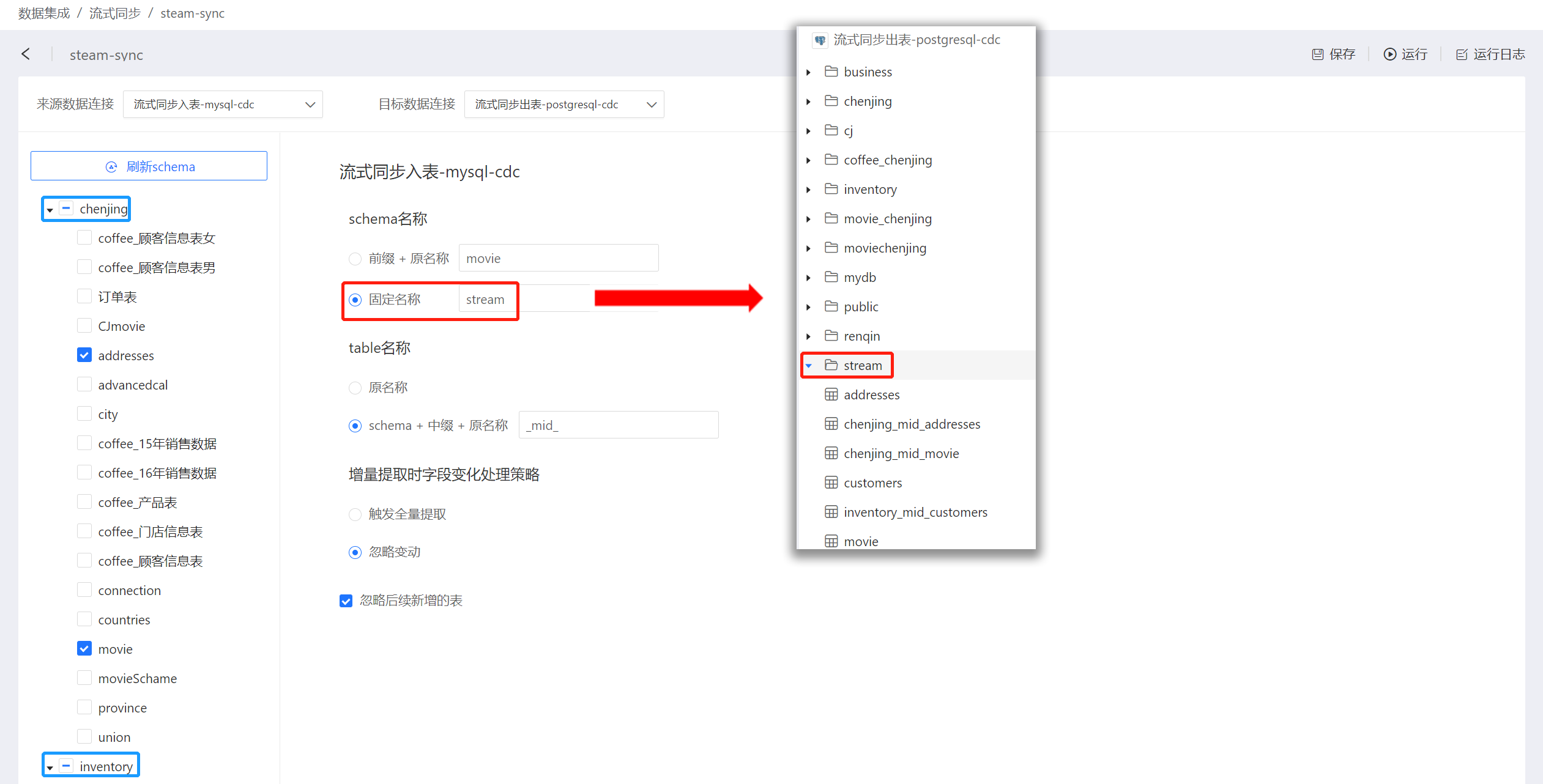
- 固定名称:数据同步后所有表存放在同一目录中。 如图所示,目录chenjing、inventory里面的表都存放在stream中。
- 前缀+ 原名称: 数据同步后表存放的目录名称为“前缀”+“原名称”。 如图将前缀设置为“movie”时,数据同步前表addresses存放在目录chenjing中,同步后表addresses存放目录名称为“moviechenjing”。
table名称:表同步后的命名规则。
- 原名称:数据同步后表名不变。
- schema+中缀+原名称:数据同步后,表的名称变为“schema”+“中缀”+“原名称”。将中缀设为“_mid_”时,表movie同步后名称改为chenjing_mid_movie。
增量提取时字段变化处理策略: 当表选择增量提取方法时,如果表的字段发生变化可以选择如下两种处理策略。
- 触发全量提取: 表按照全量方式进行提取方法。
- 忽略变动: 忽略变动的字段,表按照原来增量方式进行提取。
- 忽略后续新增的表: 勾选此项后,来源数据连接中新增的表不会被同步。
- schema名称: 数据同步后表所在的schema名称设置。
4.执行同步操作。
策略配置后,点击保存配置。点击执行后,开始同步数据。 项目会一直运行,监控源数据的变化,将其同步到目标数据中。
1.3. 流式同步数据源配置
在使用流式同步时,上游数据源的数据需要进行相关的配置,才能对其进行实时监控,下面介绍不同数据源需要配置的内容。
1.3.1. PostgreSQL数据源相关配置
PostgreSQL数据库作为来源数据源,首先检查版本信息,目前仅支持v9.6、v10、v11、v12、v13版本。然后对数据源进行以下操作。
- 调整同步表的replica identity的级别为FULL。
- 安装逻辑解码插件。
调整同步表的replica identity的级别
调整同步表的replica identity的级别为FULL,请参考如下代码进行修改。
-- 查看replica identity。
SELECT CASE relreplident
WHEN 'd' THEN 'default'
WHEN 'n' THEN 'nothing'
WHEN 'f' THEN 'full'
WHEN 'i' THEN 'index'
END AS replica_identity
FROM pg_class
WHERE oid = 'mytablename'::regclass;
-- 修改replica identity。
ALTER TABLE mytablename REPLICA IDENTITY FULL;
安装逻辑解码插件
PostgreSQL可以安装pgoutput,wal2json,decoderbufs三种逻辑解码插件,其中pgoutput要求版本在10以上。
插件pgoutput
PostgreSQL V10及以上版本自带pgoutput,请参照下面的提示修改postgresql.conf和pg_hba.conf 配置文件。
postgresql.conf 配置修改
# REPLICATION wal_level = logical # minimal, archive, hot_standby, or logical (change requires restart) max_wal_senders = 8 # max number of walsender processes (change requires restart) max_replication_slots = 4 # max number of replication slots (change requires restart)pg_hba.conf 配置修改
local replication <youruser> trust host replication <youruser> 127.0.0.1/32 trust host replication <youruser> ::1/128 trust host replication <youruser> 0.0.0.0/0 md5
说明
PostgreSQL V9.6版本没有pgoutput,请使用wal2json和decoderbufs插件。
插件wal2json
插件wal2json编译及安装过程请参考wal2json编译及安装。
安装后请修改下面的配置文件。
postgresql.conf 配置修改
wal_level = logical # # these parameters only need to set in versions 9.4, 9.5 and 9.6 # default values are ok in version 10 or later # max_replication_slots = 10 max_wal_senders = 10pg_hba.conf 配置修改
local replication <youruser> trust host replication <youruser> 127.0.0.1/32 trust host replication <youruser> ::1/128 trust host replication <youruser> 0.0.0.0/0 md5
插件decoderbufs
插件decoderbufs编译及安装过程请参考decoderbufs编译及安装。
安装后请修改下面的配置文件。
postgresql.conf 配置修改
# MODULES shared_preload_libraries = 'decoderbufs' # REPLICATION wal_level = logical # minimal, archive, hot_standby, or logical (change requires restart) max_wal_senders = 8 # max number of walsender processes (change requires restart) wal_keep_segments = 4 # in logfile segments, 16MB each; 0 disables #wal_sender_timeout = 60s # in milliseconds; 0 disables max_replication_slots = 4 # max number of replication slots (change requires restart)pg_hba.conf 配置修改
local replication <youruser> trust host replication <youruser> 127.0.0.1/32 trust host replication <youruser> ::1/128 trust host replication <youruser> 0.0.0.0/0 md5
1.3.2. MySQL数据源相关配置
MySQL数据库作为来源数据源,首先检查版本信息,目前仅支持MySQL5.6, 5.7, 8.0.x和MariaDB 10.x版本。然后对数据源进行以下操作。
修改配置文件
- my.cnf配置文件修改
[mysqld]
server-id = 1234 # 设置一个唯一的id,特别是在集群中,不能有重复
log_bin = mysql-bin # 开启binlog
binlog_format = ROW # 设置binlog模式为row
binlog_row_image = FULL
expire_logs_days = 10 # binlog 清理周期
创建用户和授权
- 创建用户。
mysql> CREATE USER 'user'@'localhost' IDENTIFIED BY 'password'; - 授权复制需要的权限。
mysql> GRANT SELECT, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user' IDENTIFIED BY 'password'; - 使授权生效。
mysql> FLUSH PRIVILEGES;
1.3.3. Oracle数据源相关配置
流式同步支持Oracle的LogMiner模式的CDC功能。Oracle数据库类型包含CDB数据库和非CDB数据库,两者的CDC配置略有不同。本章节主要介绍非CDB数据库相关配置,非CDB数据库的CDC信息请参考Oracle Flink CDC。
Oracle数据库的v11.2.x、v12.1.x、v12.2.x三个版本可作为流式同步的来源数据源,其他版本暂不支持。
作为来源数据源时,非CDB数据库需要完成以下配置。
开启日志归档
- 在命令行工具中执行以下命令以sys用户连接到数据库。
sqlplus /nolog CONNECT sys/password@host:port AS SYSDBA;- password为数据库sys用户的密码,可向数据库管理员获取。
- host为数据库实例所在服务器的IP地址,请根据实际情况设置。
- port为数据库实例所使用的端口,请根据实际情况设置。
- 执行以下命令,检查日志归档是否已开启。
archive log list;- 若回显打印“Database log mode: No Archive Mode”,说明日志归档未开启,继续执行开启日志归档下一步。
- 若回显打印“Database log mode: Archive Mode”,说明日志归档已开启。
- 执行以下命令配置归档日志参数。
alter system set db_recovery_file_dest_size = 10G; alter system set db_recovery_file_dest = '/opt/oracle/oradata/recovery_area' scope=spfile;- 10G为日志文件存储空间的大小,请根据实际情况设置。
- /opt/oracle/oradata/recovery_area为日志存储路径,请根据实际设置已经存在的路径。
- 执行以下命令开启日志归档。
shutdown immediate; startup mount; alter database archivelog; alter database open;注意:
开启日志归档功能需重启数据库,重启期间将导致业务中断,请谨慎操作。
归档日志会占用较多的磁盘空间,若磁盘空间满了会影响业务,请定期清理过期归档日志。
开启数据库和表的日志记录
执行下面命令开始数据库和表的日志记录,其中SCHEMA.TABLE为具体的表。
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
ALTER TABLE SCHEMA.TABLE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
创建表空间和LogMiner用户
执行下面命令,创建表空间、创建LogMiner执行用户,并给用户赋予权限。
CREATE TABLESPACE logminer_tbs DATAFILE '/opt/oracle/oradata/SID/logminer_tbs.dbf' SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
CREATE USER flinkuser IDENTIFIED BY flinkpw DEFAULT TABLESPACE LOGMINER_TBS QUOTA UNLIMITED ON LOGMINER_TBS;
GRANT CREATE SESSION TO flinkuser;
GRANT SELECT ON V_$DATABASE to flinkuser;
GRANT FLASHBACK ANY TABLE TO flinkuser;
GRANT SELECT ANY TABLE TO flinkuser;
GRANT SELECT_CATALOG_ROLE TO flinkuser;
GRANT EXECUTE_CATALOG_ROLE TO flinkuser;
GRANT SELECT ANY TRANSACTION TO flinkuser;
GRANT LOGMINING TO flinkuser; // 仅当Oracle为12c版本时,才需要执行这个语句
GRANT CREATE TABLE TO flinkuser;
GRANT LOCK ANY TABLE TO flinkuser;
GRANT ALTER ANY TABLE TO flinkuser;
GRANT CREATE SEQUENCE TO flinkuser;
GRANT EXECUTE ON DBMS_LOGMNR TO flinkuser;
GRANT EXECUTE ON DBMS_LOGMNR_D TO flinkuser;
GRANT SELECT ON V_$LOG TO flinkuser;
GRANT SELECT ON V_$LOG_HISTORY TO flinkuser;
GRANT SELECT ON V_$LOGMNR_LOGS TO flinkuser;
GRANT SELECT ON V_$LOGMNR_CONTENTS TO flinkuser;
GRANT SELECT ON V_$LOGMNR_PARAMETERS TO flinkuser;
GRANT SELECT ON V_$LOGFILE TO flinkuser;
GRANT SELECT ON V_$ARCHIVED_LOG TO flinkuser;
GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO flinkuser;
- /opt/oracle/oradata/SID/logminer_tbs.dbf为表空间路径,请根据实际规划设置。
- flinkuser和flinkpw为用户名和密码,请根据实际设置。
1.3.4. SQL Server数据源相关配置
SQL Server数据库作为来源数据源,首先检查版本信息,目前支持SQL Server 2016 Service Pack 1 (SP1) 及以上的版本。
作为流式同步的来源数据源,SQL Server数据库需要完成下面配置。
启动SQL Server Agent
SQL Server 2017 CU3以下版本需要手动安装,安装的步骤参考SQL Server的官方文档。
SQL Server 2017 CU4以上版本只需要启动即可。启动命令如下:
sudo /opt/mssql/bin/mssql-conf set sqlagent.enabled true
sudo systemctl restart mssql-server
开启数据库的CDC
执行命令,开启SQL Server某个数据库的CDC。
USE testdb
GO
EXEC sys.sp_cdc_enable_db
GO
开启数据库的表的CDC
执行命令,开启SQL Server某个数据库的某个表的CDC,source_schema是表的schema名字,source_name是表名。
USE testdb
GO
EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'table',
@role_name = NULL,
@filegroup_name = N'PRIMARY',
@supports_net_changes = 0
GO
重启启数据库的表的CDC
当表的字段发生变更后,需要重新开启SQL Server数据库的表的CDC。重启时,需要先停掉这个表的CDC,然后再按上一个步骤重新开启CDC。之后需要重启相应的流式同步任务,才能把字段变更信息同步到目标。 其中source_schema是表的schema名字,source_name是表名,
capture_instance是CDC实例名字,由source_schema、source_name、下划线拼接而成。
USE testdb
GO
EXEC sys.sp_cdc_disable_table
@source_schema = N'dbo',
@source_name = N'table',
@capture_instance = N'dbo_table'
GO
用户权限要求
流式同步读取SQL Server数据源中的数据进行数据同步时,必须拥有db_owner角色的权限。
results matching ""
No results matching ""
衡石文档
- 产品功能一览
- 发布说明
- 新手上路
- 安装与启动
- 系统管理员手册
- 数据管理员手册
- 分析人员手册
- 数据查看员手册
- API
- 最佳实践
- 衡石分析平台 API 手册
- 附录