1. 加速引擎
系统内置了高速 MPP 引擎,可以实现对亿级数据的即席分析,还可以将异构数据统一存储和建模,然后进行关联运算。
将数据集开启加速引擎,就会将数据集的数据导入到引擎中,对数据集进行查询时将会直接访问引擎表。
目前大数据数据源不建议大规模导入引擎,比如Hive,Spark,Impala,Presto,Max Compute,大数据集导入过程不支持流式复制,会占用大量内存,可能会卡死。允许这些数据源开启引擎是为了导入小表方便,这不意味着我们建议把这些数据源大规模导入引擎,这个不是最佳实践。建议这些数据源的数据集通过直连方式来使用,我们对直连的支持程度已经和引擎差不多了。
1.1. 开启加速引擎
点击数据源信息菜单,弹出数据元信息窗口。打开开启加速引擎,系统会提示“请稍后,数据提取中……”,此时,系统会将数据集提取到引擎中。
完成之后,会在元信息中显示引擎表名称,如图所示:
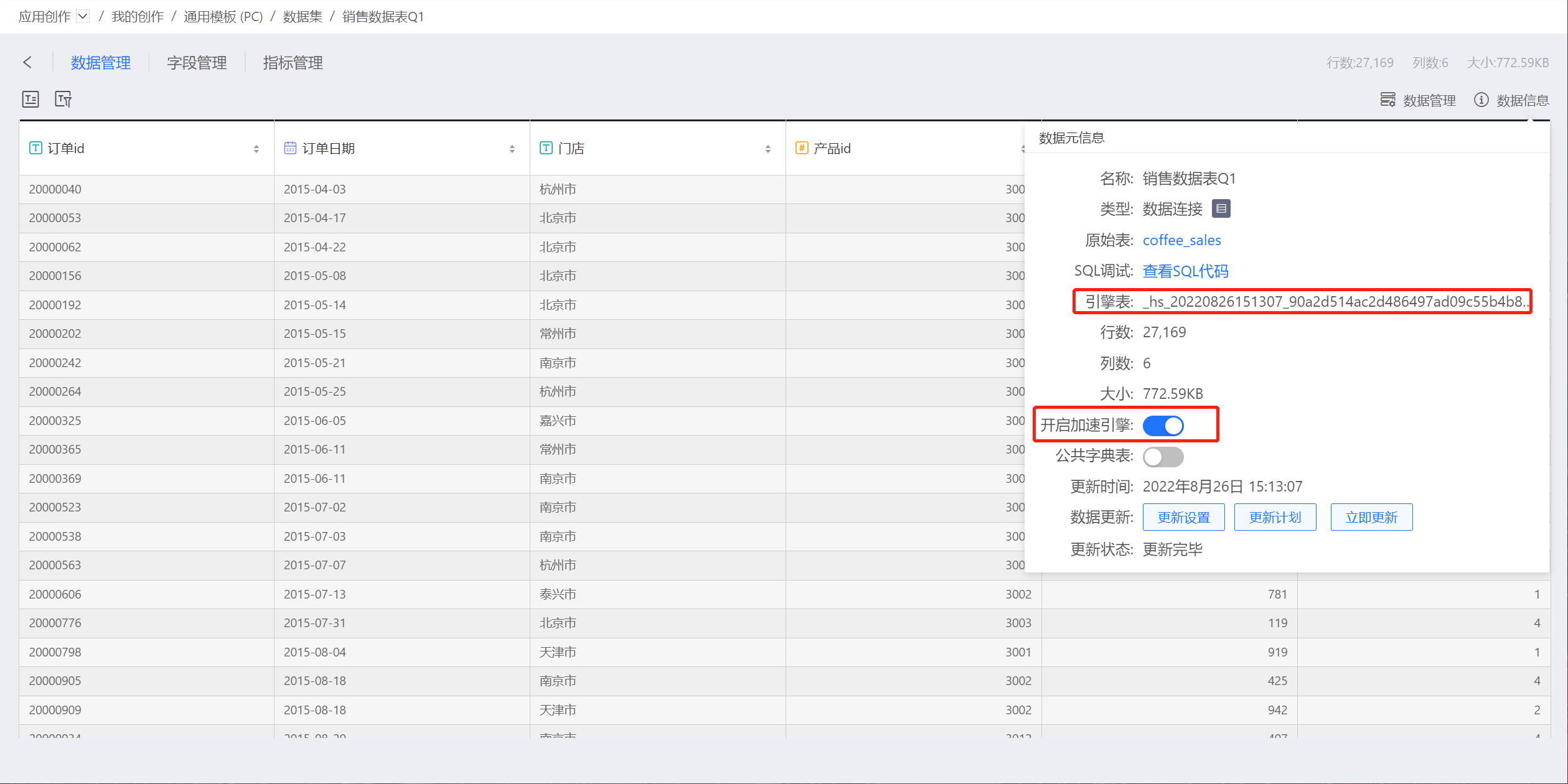
说明:
数据集大小超过系统配置的数据集缓存大小时不支持开启加速引擎。
1.2. 关闭加速引擎
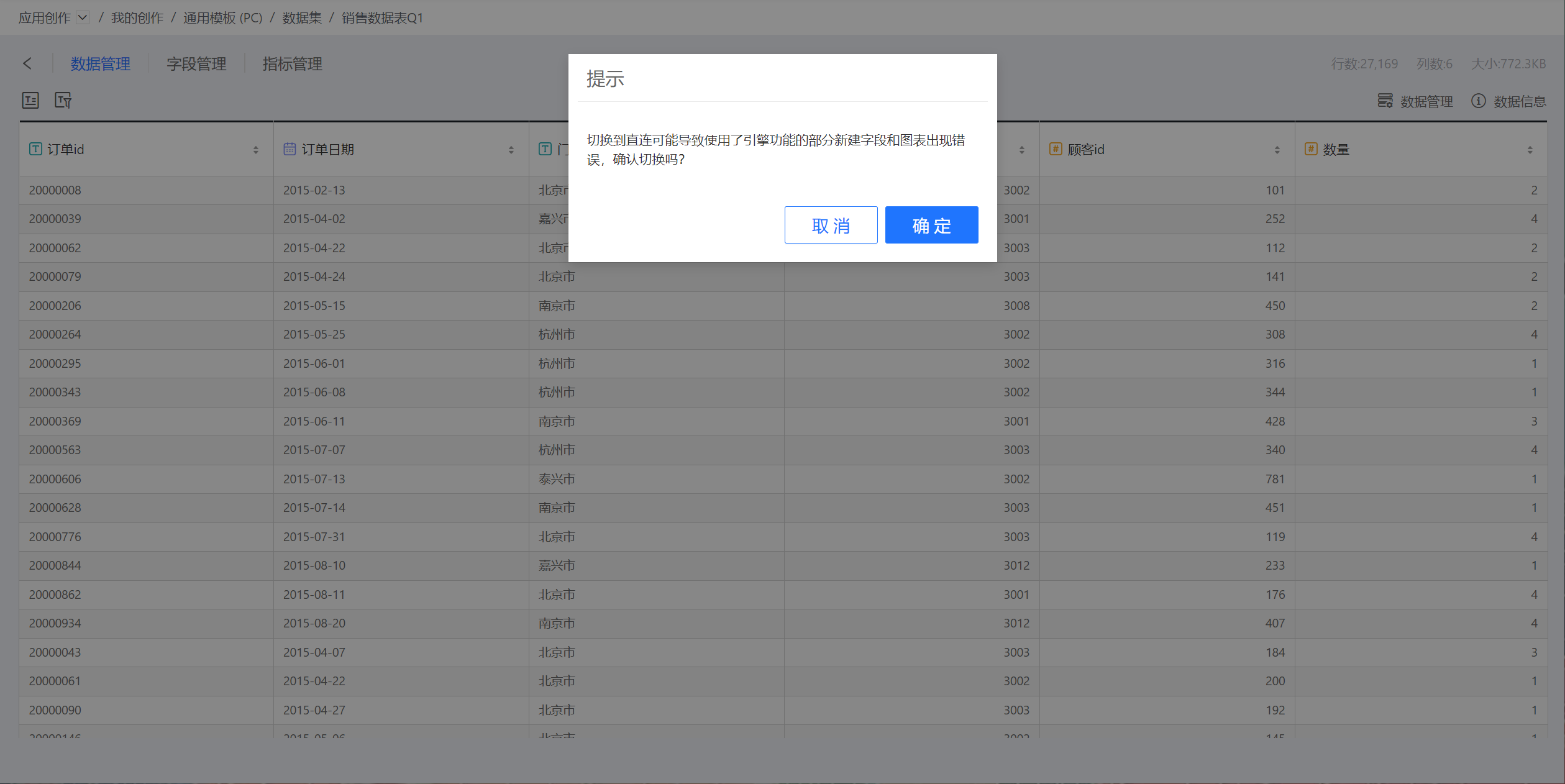
在数据元信息窗口中,关闭开启加速引擎。关闭加速引擎之后,数据集将返回直连原始表模式,此时,如果新字段使用了引擎支持但原始数据库不支持的函数,数据集就会加载失败。如果是新指标使用了引擎支持但原始数据看不支持的函数,则使用该指标的图标会出错。所以系统会弹出确认窗口,如下所示,点击确认可以关闭加速引擎:
如果该应用已发布,则不能关闭加速引擎。
1.3. 更新计划
在更新计划中可以设置引擎表与数据集原始表的同步频率。
详见更新计划。
1.4. 只有开启加速引擎后才支持的功能
- 追加数据集
- 合并数据集
- 非同源数据集多表联合
- 高级计算:Mysql 5及以下版本、Tidb不支持窗口函数,所以不支持高级计算,需要导入引擎才支持
- 部分直连数据集不支持的函数:引擎支持文档中列出的所有函数,其他数据源不支持的函数,需要导入引擎才支持
1.5. 加速引擎类型和相关数据源
系统支持使用内置引擎和外部引擎。
- 内置引擎即系统自带的加速引擎,包括Greenplum、StarRocks、Apache Doris三种类型,默认为Greenplum。用户在系统安装时可以更改内置引擎类型。
- 外部引擎即用户使用自己的数据源作为加速引擎。 目前支持开启加速引擎的数据源有:MySQL、PostgreSQL、Greenplum、Oracle、SQL Server、Spark SQL、TiDB、Amazon Redshift、MaxCompute PostgreSQL、DB2、Hive、Cloudera Impala、Presto、MongoDB、HBase、ClickHouse。
1.6. ClickHouse物化视图
当系统的加速引擎为Clickhouse时,多表联合数据集导入引擎时可使用Clickhouse物化视图。该物化视图可实时更新数据集,不需要设置更新计划,提升了关联数据的查询性能。
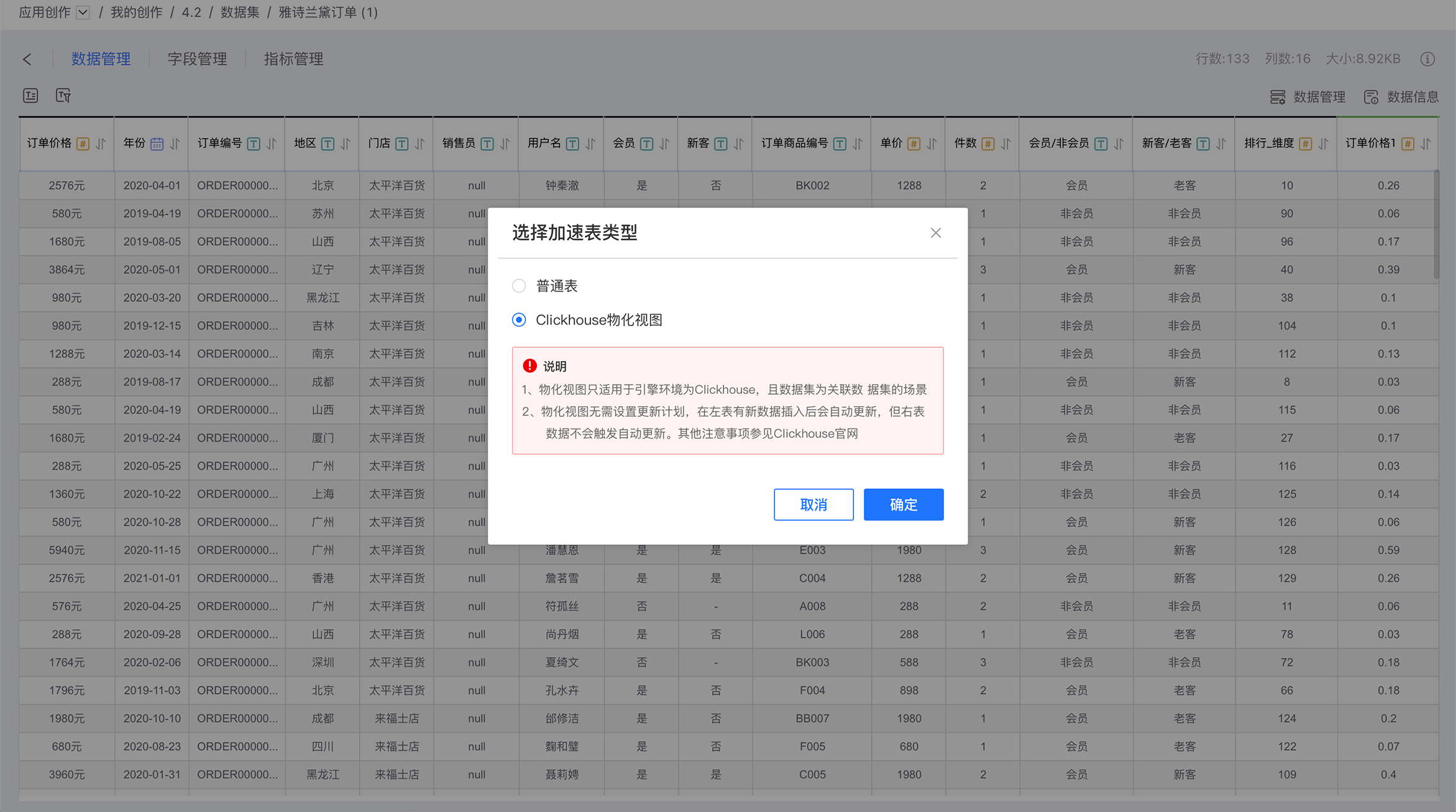
使用ClickHouse物化视图要求多表联合数据集的数据源必须是Clickhouse,并且要求与引擎在同一集群。 由于 Clickhouse 的实现机制原因,只有左表更新时才会触发视图,进行数据更新。 详细情况请参考ClickHouse官网说明。
results matching ""
No results matching ""
衡石文档
- 产品功能一览
- 发布说明
- 新手上路
- 安装与启动
- 系统管理员手册
- 数据管理员手册
- 分析人员手册
- 数据查看员手册
- API
- 最佳实践
- 衡石分析平台 API 手册
- 附录