Data Agent
模型供应商中介绍了支持的模型供应商,本文档主要介绍模型系统级配置项。
模型通用配置
下列配置项为 Data Agent 系统级配置,不区分模型供应商。
LLM_ANALYZE_RAW_DATA
在页面配置中是 允许模型分析原始数据。作用是设置 Data Agent 是否分析原始输入数据。若您的数据比较敏感,可以关掉此配置。
LLM_ANALYZE_RAW_DATA_LIMIT
在页面配置中是 允许分析的原始数据数量(行)。作用是设置分析原始数据的数量限制。依据模型供应商的处理能力、tokens 限制量、具体需求来设置。
LLM_ENABLE_SEED
在页面配置中是 使用 seed 参数。作用是控制是否在生成回复时启用随机种子,以带来结果的多样性。
LLM_API_SEED
在页面配置中是 seed 参数。作用是在生成回复时使用的随机种子数字。配合LLM_ENABLE_SEED使用,可由用户随机指定或保持默认。
LLM_SUGGEST_QUESTION_LOCALLY
在页面配置中是 不使用模型生成推荐问题。作用是指定是否在生成推荐问题时使用大模型。
- true 本地规则生成
- false 大模型生成
LLM_SELECT_ALL_FIELDS_THRESHOLD
在页面配置中是 允许模型分析元信息 (阈值)。作用是此参数设置选择所有字段的阈值。LLM_SELECT_FIELDS_SHORTCUT为 true 此参数才有作用,酌情设定。
LLM_SELECT_FIELDS_SHORTCUT
此参数设置是否在字段比较少的时候不挑选字段,直接选择所有字段参与生成 HQL。配合LLM_SELECT_ALL_FIELDS_THRESHOLD使用,依据具体操作场景确定此配置。一般不需要设置为 true。对速度特别敏感或者想省掉字段选择步骤时可以关掉此配置。但是不选择字段会影响最终数据查询的正确性。
LLM_API_SLEEP_INTERVAL
在页面配置中是 API 调用间隔 (秒)。作用是设定 API 请求之间的休眠间隔,以秒为单位。根据请求频率需求设定。对于需要限制频率的大模型 API 可以考虑设置。
HISTORY_LIMIT
在页面配置中是 连续对话上下文条数。作用是与大模型交互时携带的历史对话条目数量。
MAX_ITERATIONS
在页面配置中是 模型推理迭代上限。作用是最大迭代次数,用于控制处理大模型失败循环的次数。
LLM_HQL_USE_MULTI_STEPS
是否通过多个步骤来优化趋势,同环比类型的问题的指令遵循程度,酌情设定,多个步骤会相对慢一些。
CHAT_BEGIN_WITH_SUGGEST_QUESTION
在去分析跳转后,是否会给用户提供几个推荐问题。根据需要开启。
CHAT_END_WITH_SUGGEST_QUESTION
每个问题回合回答后,是否会给用户提供几个推荐问题。根据需要开启。关闭可以节省一部分时间。
LLM_MAX_TOKENS
大模型最大输出 token 数,默认值是 1000;
LLM_EXAMPLE_SIMILAR_COUNT
相似例子搜索个数限制,在 Workflow 模式下的例子选择步骤有效,默认值是 2。
LLM_RELATIVE_FUNCTIONS_COUNT
相关函数搜索个数限制,在 Workflow 模式下的函数选择步骤有效,默认值是 3。
LLM_SUMMARY_MAX_DATA_BYTES
模型对结果进行总结时,发送的数据部分最大字节数,默认值是 5000 字节。在 Workflow 模式下的总结步骤有效。
LLM_ENABLE_SUMMARY
是否开启总结。在 Workflow 模式下的总结步骤有效,默认值是 true。如果只需要数据和图表,不需要总结,可以关闭以节省时间和费用。
LLM_RAW_DATA_MAX_VALUE_SIZE
数据集原始字段值超过多少字节就不给这个值给大模型了,默认值是 30 字节。文本维度,日期等字段内容一般不会太长。太长的字段内容给大模型意义不大,比如html等。
CHAT_TOKEN_MATCH_SIMILARITY_THRESHOLD
文本搜索相似度阈值,一般不用调整。
CHAT_TOKEN_MATCH_WEIGHT
文本搜索分数权重,一般不用调整。
CHAT_VECTOR_MATCH_SIMILARITY_THRESHOLD
向量搜索相似度阈值,一般不用调整。
CHAT_VECTOR_MATCH_WEIGHT
向量搜索分数权重,一般不用调整。
CHAT_ENABLE_PROHIBITED_QUESTION
是否开启禁用问题功能,开启后可以在控制台的 UserSystem Prompt 中配置禁止回答的问题规则。默认是 false。
USE_LLM_TO_SELECT_DATASETS
是否用大模型来精选数据集,默认是 false。关闭时,主要通过向量和分词算法来选择数据集。开启后,通过大模型对向量和分词的结果进行二次筛选,得到最相关的数据集。当选择结果不理想时,可以考虑开启,并在数据集知识管理中定义被选中的规则。
LLM_SELECT_DATASETS_NUM
大模型从多少个最相关数据集中精选数据集。这个控制向量和分词初步筛选的分数最高的数据集个数。USE_LLM_TO_SELECT_DATASETS开启时,配置这个才有意义。默认是 15。
CHAT_SYNC_TIMEOUT
API 调用时,同步等待问答结果默认最大等待时间,单位是毫秒,默认 60000 毫秒。API 请求也可以在 URL 参数中设置 timeout 以覆盖这个值。
CHAT_DATE_FIELD_KEYWORDS
当有哪些关键字时,如果字段选择步骤没有选日期类型的字段,自动加上日期类型的字段。默认值是"年,月,日,周,季,日期,时间,YTD,year,month,day,week,quarter,Q,date,time,变化,走势,趋势,trend"
CHAT_DATE_TREND_KEYWORDS
当有哪些关键字时,判断为趋势计算。默认值是"变化,走势,趋势,trend"。
CHAT_DATE_COMPARE_KEYWORDS
当有哪些关键字时,判断为同环比计算。默认值是"同比,环比,增长,增量,减少,减量,异常,同期,相比,相对,波动,growth,decline,abnormal,fluctuation"。
CHAT_RATIO_KEYWORDS
当有哪些关键字时,判断为占比类计算。默认值是"百分比,比例,比率,占比,percentage,proportion,ratio,fraction,rate"。
CHAT_FILTER_TOKENS
分词过滤掉哪些无意义的字词。默认值是"的,于,了,为,年,月,日,时,分,秒,季,周,,,?,;,!,在,各,是,多少,(,)"。
USE_LLM_TO_SELECT_EXAMPLES
是否用大模型选例子。默认是 true。在 Workflow 模式下有效。大模型选择例子相关性会相对高一些。
ENABLE_SMART_CHART_TYPE_DETECTION
是否开启图表类型智能判断。默认为 true。如果需要图表类型全部为表格,可以关掉。根据轴判断图表类型规则:
- 1个时间维度和1个或多个度量:折线图
- 1个时间维度,1个文本维度,1个度量:面积图
- 1个文本维度和1个度量:柱状图
- 1个文本维度和2个度量:分组柱状图
- 其他默认使用表格。
ENABLE_KPI_CHART_DETERMINE_BY_DATA
是否根据data结果为1行1列数字修改图表类型为KPI,默认是 true。如果需要图表类型全部为表格,可以关掉。
MEASURE_TOKENIZE_BATCH_SIZE
业务指标分词分批处理大小。一般不用改。默认是 1000。
ENABLE_USER_ATTRIBUTE_PROMPT
是否开启用户属性prompt,开启后会根据用户填的用户属性带入相关信息给大模型。默认开启。
ENABLE_LLM_API_PROXY
是否开启大模型api代理,开启后可以通过衡石来调用大模型的/chat/completions接口。默认开启。Agent 模式也是通过通过衡石来调用大模型接口的。
ENABLE_TENANT_LLM_API_PROXY
租户是否可以使用大模型api代理,默认开启。Agent 模式也是通过通过衡石来调用大模型接口的。
CHAT_DATA_DEFAULT_LIMIT
AI 生成的图表,如果 AI 没有根据语义设置,默认 limit 是多少,默认 100。
CHAT_WITH_NO_THINK_PROMPT
大模型对话是否都加上 no think 的 prompt,对于阿里巴巴的 qwen3 系列模型有用,可以关闭思考,提高速度。另外对于智谱的 glm-4.5 以上模型,该开关也控制是否禁用思考。默认是false,即开启思考。
USE_FALLBACK_CHART
是否开启保底 chart ,用向量查询结果自动生成图表。默认是 false。默认生成的图表准确性不高,仅作为保底方案。
USE_MAX_COMPLETION_TOKENS
是否用 max_completion_tokens 替换 max_tokens 参数名称。默认关闭。gpt-5 以上的模型使用 max_completion_tokens 参数,需要开启。
USE_TEMPERATURE
是否使用 temperature 参数,默认开启。部分模型不支持 temperature 参数,可以关闭。
ENABLE_QUESTION_REFINE
是否开启用户问题优化功能,开启后会对用户问题进行优化再发送给大模型,默认开启。Workflow 模式下有效。如果问题保证比较具体,可以关闭以节省时间和费用。
SPLIT_FIELDS_BY_DATASET_IN_HQL_GENERATOR
在 HQLGenerator 中是否分数据集列出字段和指标列表,默认关闭。Workflow 模式下有效。开启后可以提升多数据集组成的数据模型场景下字段和指标选择的准确性,但会增加提示词长度。
LLM_API_TIMEOUT_SECONDS
大模型 api 调用超时时间(秒),默认 600 秒。
NODE_AGENT_ENABLE
是否开启衡石 AI Node Agent API 功能,以支持 API 调用方式也能用到 AI Agent。默认关闭。开启该功能需要额外的依赖要求和设置。见下面说明。
NODE_AGENT_TIMEOUT
衡石 AI Node Agent 执行超时时间,单位毫秒,默认 600000 毫秒(10 分钟)。
NODE_AGENT_CLIENT_ID
衡石 AI Node Agent 执行用到的衡石平台 API clientId,需要系统管理员生成,并配置,需要支持 sudo。
EXPAND_AGENT_REASONING
设定是否自动展开 agent 思考过程,默认展开。
PREFER_AGENT_MODE
设定是否默认使用 agent 模式,默认是 agent 模式,关闭后默认为 workflow 模式。
SCRATCH_PAD_TRIGGER
设定关键字强制 agent 使用草稿纸工具,关键字以英文逗号分割。
TABLE_FLEX_ROWS
设定对话中表格的最大可视范围行数,默认为 5.
AWS Bedrock 相关配置
LLM_AWS_BEDROCK_REGION
AWS Bedrock 区域,如果使用 AWS Bedrock 才需要配置。默认是 ap-southeast-2,具体请参考 AWS Bedrock 文档。
LLM_ANTHROPIC_VERSION
AWS Anthropic Claude 的版本号,如果使用 AWS Anthropic Claude 模型才需要配置。默认是 bedrock-2023-05-31,具体请参考 AWS Bedrock 中关于 AWS Anthropic Claude 的文档。
向量库配置
ENABLE_VECTOR
启用向量搜索功能。AI助手通过大模型 API 来挑选跟问题最相关的例子。开启向量搜索后,AI助手会综合大模型 API 和向量搜索的结果。
VECTOR_MODEL
向量化模型,基于是否需要向量搜索能力来设置。需要跟VECTOR_ENDPOINT 配合使用。系统自带的向量服务上已经包含的模型是intfloat/multilingual-e5-base。这个模型不需要下载。如果需要其他模型,目前支持选择在huggingface上面的向量模型。需要注意的是,向量服务必须能够保证可以连通huggingface官网,不然模型下载会失败。
VECTOR_ENDPOINT
向量化 API 地址,基于是否需要向量搜索能力来设置。安装好向量数据库相关服务后,默认指向自带的向量服务。
VECTOR_SEARCH_RELATIVE_FUNCTIONS
是否搜索问题相关的函数说明。开启后会搜索问题相关的函数说明,相应的,提示词会变大。这个开关只有在ENABLE_VECTOR开启的情况下才生效。
VECTOR_SEARCH_FIELD_VALUE_NUM_LIMIT
分词搜索数据集字段 distinct value 个数的上限,distinct value 匹配过多的部分将不会提取,酌情设定。
INIT_VECTOR_PARTITIONS_SIZE
例子向量化分批执行,每批大小。一般不用调整。默认是 100。
VECTOR_MODEL_KEEP_COUNT
当切换向量模型时,保留历史向量模型向量化数据的最大模型个数。默认是 5。一般不用调整。
INIT_VECTOR_INTERRUPTION_THRESHOLDS
当向量化例子库时,最大允许失败个数。默认是 100。一般不用调整。
向量库详细配置见: AI 配置
控制台
在控制台中,我们公开展示了 Data Agent workflow 模式的工作流,每个节点都是可编辑的提示词。同时,还可以直接在此页面与 Data Agent 进行对话,方便进行故障排查。
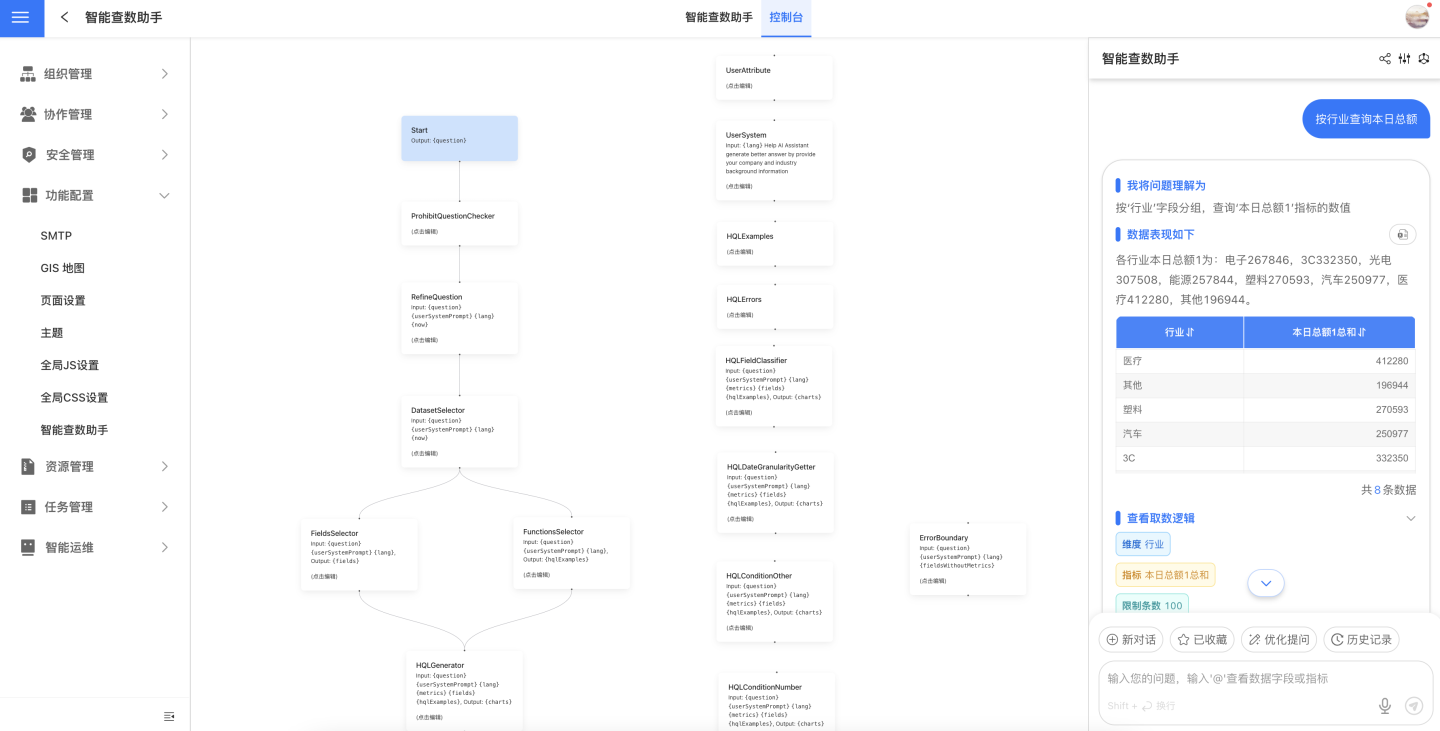
提升
编辑提示词需要你对大模型有一定的了解,建议由系统管理员进行操作。
UserSystem Prompt 用户系统提示词
大模型具备绝大多数的通识知识,但对于特定业务、行业黑话、私域知识等,需要通过提示词来提升大模型的理解能力。
举例来说,在电商领域,“大促”、“爆款”等词汇,对大模型来说,可能不具备明确的含义,通过提示词,可以提升大模型对这些词汇的理解能力。
大模型通常认为“大促”通常指的是在某个特定时间段内,商家或平台进行的规模较大的促销活动。这类活动通常集中在购物节、节假日或特定主题日,例如“双十一”、“618”等。
若你希望大模型能够准确理解“大促”的含义,可以在提示词中明确说明大促是指双十一等。
Conclusion Prompt 回答总结提示词
在 Data Agent 根据用户问题查询到数据后,会让大模型依据此提示词,对查询结果进行总结来回答问题。
系统默认的总结提示词是较为基础的,你可以根据业务需求,修改为更贴合实际场景的总结提示词,具体与你公司业务密切相关。
SuggestQuestions Prompt 推荐问题提示词
系统默认的推荐问题提示词是较为基础的,你可以根据业务需求,修改为更贴合实际场景的问题推荐逻辑提示词,具体与你公司业务密切相关。
如何配置 AI API 调用使用 Agent 模式
API 调用默认使用 Workflow 模式,如果需要使用 Agent 模式,需要有额外的环境要求,并进行额外配置。
环境要求
- Node JS 22 及以上版本,需要在衡石服务所在机器上安装 Node JS 环境,确保衡石服务可以调用。比较老的系统比如 CentOS7 可能没法支持。
配置步骤
- 在设置-功能配置-Data Agent-模型通用配置中,开启
NODE_AGENT_ENABLE参数。 - 在设置-安全管理-API授权中,添加授权,填写名称,勾选
sudo功能,记录下 clientId。 - 在设置-功能配置-Data Agent-模型通用配置中,配置
NODE_AGENT_CLIENT_ID参数为上一步创建的 clientId。